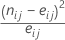분할표에 r개의 행과 c개의 열이 있다고 가정합니다. 분할표의 i행과 j열의 항목, nij는 해당 열에 대한 빈도입니다. i행의 총계, ni.는 i행의 빈도 합입니다. j열의 총계, n.j는 j열의 빈도 합입니다. 표에 대한 총계, n.. 또는 n은 표의 모든 빈도 합입니다.
행 및 열 프로파일
프로파일은 본래 분할표의 카운트 nij로부터 계산된 비율입니다. 구체적으로 i행에 대한 프로파일은 (ni1 / ni., ..., nic / ni.)이고 j열에 대한 프로파일은 (n1j / n.j, ..., nrj / n.j)입니다.
평균 행 프로파일은 열 총계에서 계산됩니다. 구체적으로 평균 행 프로파일은 (n.1 / n, ..., n.c / n)입니다. 마찬가지로, 평균 열 프로파일은 행 총계에서 계산됩니다. 구체적으로 평균 열 프로파일은 (n1. / n,..., nr. / n)입니다.
기대 빈도
기대 셀 빈도는 행 프로파일 또는 열 프로파일이 동질적이라는 가정 하에 계산됩니다. i행과 j열의 셀에 대한 기대 빈도는 다음과 같이 계산됩니다.
카이-제곱 값
i행과 j열의 셀에 있는 χ2 값은 다음과 같이 계산됩니다.
관측 및 기대 셀 빈도가 크게 다르면 셀에 대한 χ2 값이 큽니다.
χ2 통계량은 표에 있는 모든 셀의 χ2 값의 합입니다. 이 통계량은 행 프로파일 또는 열 프로파일의 동질성으로부터의 불일치를 측정합니다. 행(열) 프로파일이 서로 크게 다르면 χ2 통계량이 큰 것입니다. χ2 통계량은 또한 행 프로파일(또는 열 프로파일)이 평균 행(열) 프로파일로부터 얼마나 떨어져 있는지 나타내는 측도로 간주할 수 있습니다.