거리 제곱
Mahalanobis 거리 제곱 - 일반적인 형식
선형 판별에 대한 관측치 x의 그룹 t의 중심(평균)까지의 거리 제곱(Mahalanobis 거리라고도 함)은 다음과 같은 일반적인 형식으로 제공됩니다.

Mahalanobis 거리 제곱 - 2차 함수
2차 판별 함수에 대한 x에서 그룹 t까지의 Mahalanobis 거리 제곱은 다음과 같이 계산됩니다.

일반화 거리 제곱 - 선형 함수
선형 판별 함수에 대한 x에서 그룹 t까지의 일반화 거리 제곱은 다음과 같이 계산됩니다.
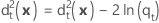
일반화 거리 제곱 - 2차 함수
2차 판별 함수에 대한 x에서 그룹 t까지의 일반화 거리 제곱은 다음과 같이 계산됩니다.

사후 확률
그룹 t에 속하는 x에 대한 사후 확률은 다음과 같이 계산됩니다.
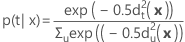
선형 판별 점수
선형 판별 점수는 다음과 같이 계산됩니다.

표기법
| 용어 | 설명 |
|---|---|
| x | 이 관측치에 대한 예측 변수의 값이 포함된 길이 p의 열 벡터(이 열 벡터는 하나의 행으로 저장됩니다.) |
| p | 예측 변수의 수 |
| n | 총 관측치 수 |
| t | 그룹 첨자 |
| nt | 그룹 t의 관측치 수 |
| qt | 그룹 t의 사전 확률, nt/n과 같음 |
| Sp | 선형 판별 분석에 대한 합동 공분산 행렬 |
| Si | 2차 판별 분석에 대한 그룹 i의 공분산 행렬 |
| mt | 그룹 t의 데이터에서 계산된 예측 변수의 평균이 포함된 길이 p의 열 벡터 |
| St | 그룹 t의 공분산 행렬 |
| |St| | St의 행렬식 |
선형 판별 함수
선형 판별 함수는 다중 회귀 분석의 회귀 계수에 해당하며 다음과 같이 계산됩니다.

주어진 x에 대해 이 규칙은 x를 선형 판별 함수가 가장 큰 그룹에 할당합니다.
표기법
| 용어 | 설명 |
|---|---|
| x | 이 관측치에 대한 예측 변수의 값이 포함된 길이 p의 열 벡터(이 열 벡터는 하나의 행으로 저장됩니다.) |
| mi | 그룹 i의 데이터에서 계산된 예측 변수의 평균이 포함된 길이 p의 열 벡터 |
| Sp | 합동 공분산 행렬 |
| ln pi | 그룹 i에 대한 사전 확률의 자연 로그 |
일반화 거리 제곱
일반화 거리 제곱은 2차 거리 측도로 사용되며 다음과 같이 계산됩니다.

표기법
| 용어 | 설명 |
|---|---|
| x | 이 관측치에 대한 예측 변수의 값이 포함된 길이 p의 열 벡터(이 열 벡터는 하나의 행으로 저장됩니다.) |
| mi | 그룹 i의 데이터에서 계산된 예측 변수의 평균이 포함된 길이 p의 열 벡터 |
| Sp | 합동 공분산 행렬 f |
| ln pi | 그룹 i에 대한 사전 확률의 자연 로그 |
사후 확률
사후 확률은 데이터가 주어진 상태에서 그룹 i의 확률이며 다음과 같이 계산됩니다.
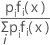
사후 확률이 가장 크면 ln [pi fi (x)] 값도 가장 큽니다.
설명(분포가 정규 분포인 경우):

그리고

표기법
| 용어 | 설명 |
|---|---|
| pi | 그룹 i의 사전 확률 |
| fi(x) | 그룹 i에 있는 데이터의 결합 밀도(모집단 모수는 표본 추정치로 바뀜) |