1단계: 유사성 및 거리 수준 조사
합병 공정의 각 단계에서 형성된 군집을 보고 유사성 및 거리 수준을 조사합니다. 유사성 수준이 높을수록 각 군집의 변수가 더 유사합니다(상관됨). 거리 수준이 낮을수록 각 군집의 변수가 서로 더 가깝습니다.
이상적으로 군집의 유사성 수준은 상대적으로 높고 거리 수준은 상대적으로 낮습니다. 그러나 합리적이고 실제적인 수의 군집을 사용하여 이 목표의 균형을 맞추어야 합니다.
합병 단계
| 단계 | 군집 수 | 유사성 수준 | 거리 수준 | 결합된 군집 | 새 군집 | 새 군집의 관측치 수 | |
|---|---|---|---|---|---|---|---|
| 1 | 4 | 93.9666 | 0.120669 | 2 | 3 | 2 | 2 |
| 2 | 3 | 93.1548 | 0.136904 | 4 | 5 | 4 | 2 |
| 3 | 2 | 87.3150 | 0.253700 | 1 | 4 | 1 | 3 |
| 4 | 1 | 79.8113 | 0.403775 | 1 | 2 | 1 | 5 |
주요 결과: 유사성 수준, 거리 수준
이 결과의 데이터에는 총 5개의 변수가 포함됩니다. 1단계에서는 두 군집(워크시트의 변수 2와 3)이 결합하여 새 군집을 형성합니다. 결과적으로 데이터에는 유사성 수준이 93.9666이고 거리 수준이 0.130669인 4개의 군집이 생성됩니다. 유사성 수준이 높고 거리 수준이 낮아도 군집 수가 너무 많아 유용하지 않습니다. 이후의 각 단계에서는 새 군집이 형성됨에 따라 유사성 수준이 감소하고 거리 수준이 증가합니다. 최종 단계에서는 모든 변수가 하나의 군집으로 결합됩니다.
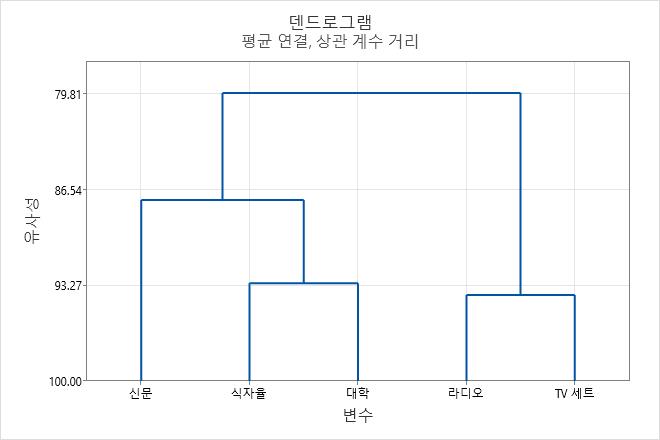
덴드로그램에서 유사성 수준을 보려면 Minitab에서 트리 다이어그램의 수평선 위에 포인터를 놓습니다.
2단계: 데이터에 대한 최종 그룹화 결정
데이터에 대한 최종 그룹을 결정하려면 각 단계에서 결합된 군집에 대한 유사성 수준을 사용합니다.단계 간에 유사성 수준이 급격하게 변경되었는지 확인합니다. 유사성이 급격하게 변경되기 전의 단계가 최종 분할에 대한 좋은 컷오프 점을 제공할 수도 있습니다. 최종 분할의 경우 군집의 유사성 수준이 상당히 높아야 합니다. 또한 연구에 가장 유의한 최종 그룹을 결정하려면 데이터에 대한 실제 지식을 활용해야 합니다.
예를 들어, 다음 합병 표는 유사성 수준이 1단계(93.9666)에서 2단계(93.1548)로 약간 감소한다는 것을 보여줍니다. 그런 다음 군집 수가 3에서 2로 변경되는 3단계(0.253700)에서는 유사성이 급격하게 감소하며, 이 결과는 3개의 군집이 최종 분할에 적절할 수도 있다는 것을 나타냅니다. 이 그룹화 방식이 직관적인 의미를 가지면 이 방식을 선택하는 것이 좋습니다.
합병 단계
| 단계 | 군집 수 | 유사성 수준 | 거리 수준 | 결합된 군집 | 새 군집 | 새 군집의 관측치 수 | |
|---|---|---|---|---|---|---|---|
| 1 | 4 | 93.9666 | 0.120669 | 2 | 3 | 2 | 2 |
| 2 | 3 | 93.1548 | 0.136904 | 4 | 5 | 4 | 2 |
| 3 | 2 | 87.3150 | 0.253700 | 1 | 4 | 1 | 3 |
| 4 | 1 | 79.8113 | 0.403775 | 1 | 2 | 1 | 5 |
주요 결과: 유사성 수준, 군집 수
최종 그룹화에 대해 결정하는 것을 덴드로그램 커팅이라고도 합니다. 덴드로그램 커팅은 덴드로그램에 수평선을 그려 최종 그룹화를 지정하는 것과 유사합니다. 예를 들어, 이 덴드로그램을 네 개의 군집으로 커팅하려면 약 88의 유사성 수준 바로 아래 수직 축의 중간 부분에 아래 방향으로 수평선을 그린다고 가정하십시오.
3단계: 최종 분할 조사
2단계에서 최종 그룹화를 결정한 후 분석을 반복하고 최종 분할을 위한 군집 수(또는 유사성 수준)을 지정합니다. Minitab에서는 최종 분할에서 각 군집을 형성하는 변수를 보여주는 최종 분할 표를 표시합니다.
그룹화가 현재 연구에 대해 논리적인지 확인하려면 최종 분할의 군집을 살펴봅니다. 그래도 확실하지 않으면 분석을 반복하고 여러 최종 그룹화의 덴드로그램을 비교하여 데이터에 가장 논리적인 그룹을 결정합니다.
합병 단계
| 단계 | 군집 수 | 유사성 수준 | 거리 수준 | 결합된 군집 | 새 군집 | 새 군집의 관측치 수 | |
|---|---|---|---|---|---|---|---|
| 1 | 4 | 93.9666 | 0.120669 | 2 | 3 | 2 | 2 |
| 2 | 3 | 93.1548 | 0.136904 | 4 | 5 | 4 | 2 |
| 3 | 2 | 87.3150 | 0.253700 | 1 | 4 | 1 | 3 |
| 4 | 1 | 79.8113 | 0.403775 | 1 | 2 | 1 | 5 |
최종 분할
| 변수 | |
|---|---|
| 군집 1 | 신문 |
| 군집 2 | 라디오 TV 세트 |
| 군집 3 | 식자율 대학 |
주요 결과: 최종 분할, 덴드로그램
이 결과에서는 최종 분할에서 세 개의 군집이 생성됩니다.
- 1,000명당 신문 부수
- 라디오 및 텔레비전 수
- 식자율 및 도시에 대학이 있는지 여부
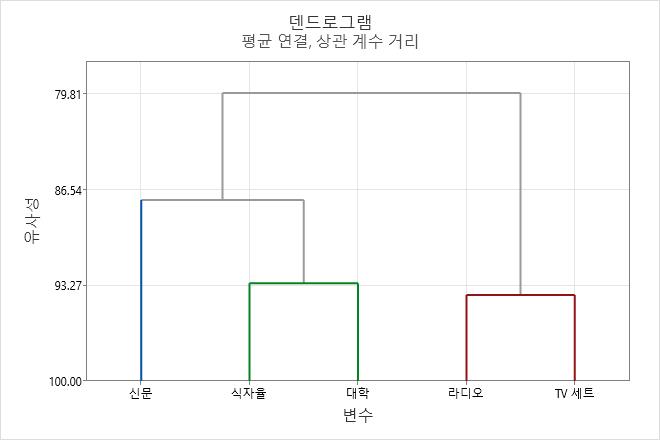
이 덴드로그램은 군집 세 개의 최종 분할을 사용하여 생성되었습니다. 각 최종 군집은 별도의 색상으로 표시됩니다. 덴드로그램은 약 88의 유사성 수준에서 커팅되었습니다. 덴드로그램을 높이 커팅할수록 최종 군집 수가 작지만 유사성 수준은 감소합니다. 덴드로그램을 낮게 커팅할수록 유사성 수준이 더 크지만 최종 군집 수가 많습니다.