단계
군집을 결합하는 합병 절차의 단계 수입니다. 각 단계에서 새 군집이 기본 군집에 결합되고 유사성 수준과 거리 수준이 계산됩니다.
군집 수
합병 과정의 각 단계에서 형성된 군집의 수입니다. 첫 번째 단계 전에 군집 수는 총 관측치 수(군집 관측치의 경우) 또는 총 변수 수(군집 변수의 경우)와 같습니다. 첫 번째 단계에서는 두 군집이 결합하여 새 군집을 형성합니다. 이후의 각 단계에서는 또 하나의 군집이 기존 군집에 결합되어 새 군집을 형성합니다. 최종 단계에서는 모든 관측치 또는 변수가 하나의 군집으로 결합됩니다.
주 대화 상자에 군집 수를 입력하여 데이터의 최종 분할을 지정할 수 있습니다. 선택한 연결 방법 및 거리 측도에 따라 군집화 결과가 크게 달라집니다.
유사성 수준
각 합병 단계에서 데이터의 관측 개체 간 최대 거리와 비교한 군집 간 최소 거리의 백분율입니다. 두 군집 i와 j 사이의 유사성 s(ij)는 s(ij) = 100 * [1-d(ij)) / d(max]입니다. 여기서 d(max)는 i와 j 사이의 거리에 대한 항목 d(ij)를 가진 원래 거리 행렬 D의 최대값입니다.
해석
데이터에 대한 최종 그룹을 결정하려면 각 단계에서 결합된 군집에 대한 유사성 수준을 사용합니다.단계 간에 유사성 수준이 급격하게 변경되었는지 확인합니다. 유사성이 급격하게 변경되기 전의 단계가 최종 분할에 대한 좋은 컷오프 점을 제공할 수도 있습니다. 최종 분할의 경우 군집의 유사성 수준이 상당히 높아야 합니다. 또한 연구에 가장 유의한 최종 그룹을 결정하려면 데이터에 대한 실제 지식을 활용해야 합니다.
예를 들어, 다음 합병 표는 유사성 수준이 1단계(93.9666)에서 2단계(93.1548)로 약간 감소한다는 것을 보여줍니다. 그런 다음 군집 수가 3에서 2로 변경되는 3단계(0.253700)에서는 유사성이 급격하게 감소하며, 이 결과는 3개의 군집이 최종 분할에 적절할 수도 있음을 나타냅니다. 이 그룹화 방식이 직관적인 의미를 가지면 이 방식을 선택하는 것이 좋습니다.
합병 단계
| 단계 | 군집 수 | 유사성 수준 | 거리 수준 | 결합된 군집 | 새 군집 | 새 군집의 관측치 수 | |
|---|---|---|---|---|---|---|---|
| 1 | 4 | 93.9666 | 0.120669 | 2 | 3 | 2 | 2 |
| 2 | 3 | 93.1548 | 0.136904 | 4 | 5 | 4 | 2 |
| 3 | 2 | 87.3150 | 0.253700 | 1 | 4 | 1 | 3 |
| 4 | 1 | 79.8113 | 0.403775 | 1 | 2 | 1 | 5 |
거리 수준
각 단계에서 결합된 군집(선택한 연결 방법 사용) 또는 변수(선택한 거리 측도 사용) 사이의 거리입니다. Minitab에서는 사용자가 주 대화 상자에서 선택한 연결 방법과 거리 측도를 기반으로 거리 수준을 계산합니다.
두 변수 사이의 거리는 상관과 직접 관련되어 있습니다. 즉, 두 변수 X1과 X2의 경우 거리는 1 − 상관과 같습니다. 예를 들어, Corr(X1,X2) = 0.879인 경우 거리(X1,X2) = 1 − 0.879 = 0.121입니다.
해석
데이터에 대한 최종 그룹화를 결정하려면 각 단계에서 결합된 군집에 대한 거리 수준을 사용합니다. 단계 간에 거리 수준이 급격하게 변경되었는지 확인합니다. 거리가 급격하게 변경되기 전의 단계가 최종 분할에 대한 좋은 컷오프 점을 제공할 수도 있습니다. 최종 분할의 경우 군집의 거리 수준이 상당히 작아야 합니다. 또한 연구에 가장 유의한 최종 그룹을 결정하려면 데이터의 실제 지식을 사용해야 합니다.
예를 들어, 다음 합병 표는 거리 수준이 1단계(0.120669)에서 2단계(0.136904)로 약간 증가한다는 것을 보여줍니다. 그런 다음 군집 수가 3에서 2로 변경되는 3단계(0.253700)에서는 거리가 급격하게 증가하며, 이 결과는 3개의 군집이 최종 분할에 적절할 수 있다는 것을 나타냅니다. 이 그룹화 방식이 직관적인 의미를 가지면 이 방식을 선택하는 것이 좋습니다.
합병 단계
| 단계 | 군집 수 | 유사성 수준 | 거리 수준 | 결합된 군집 | 새 군집 | 새 군집의 관측치 수 | |
|---|---|---|---|---|---|---|---|
| 1 | 4 | 93.9666 | 0.120669 | 2 | 3 | 2 | 2 |
| 2 | 3 | 93.1548 | 0.136904 | 4 | 5 | 4 | 2 |
| 3 | 2 | 87.3150 | 0.253700 | 1 | 4 | 1 | 3 |
| 4 | 1 | 79.8113 | 0.403775 | 1 | 2 | 1 | 5 |
결합된 군집
합병 공정의 각 단계에서 새 군집을 형성하기 위해 결합된 두 군집입니다.
새 군집
합병 공정의 각 단계에서 형성된 새 군집의 식별 번호입니다. 새 군집의 식별 번호는 항상 결합된 두 군집의 식별 번호 중 작은 값입니다. 예를 들어, 군집 2와 군집 9를 결합한 경우 새로 형성된 군집은 군집 2가 됩니다.
새 군집의 관측치 수
합병 과정의 각 단계에서 각 새 군집의 관측치 수입니다. 최종 단계에서 모든 관측치는 하나의 군집으로 결합합니다. 따라서 마지막 단계에서 새 군집의 관측치 수는 데이터의 총 관측치 수와 같습니다.
참고
변수 군집의 경우 관측치 수는 새 군집의 변수 수입니다.
최종 분할
주 대화 상자에서 최종 분할을 지정하면 Minitab에서 각 군집의 변수 리스트를 표시합니다. 최종 분할의 각 군집 내 변수는 특정 분야를 기반으로 직관적인 의미를 가지고 있어야 합니다.
덴드로그램
덴드로그램은 각 단계에서 변수의 군집화를 통해 형성된 그룹과 이들의 유사성 수준을 표시하는 트리 다이어그램입니다. 유사성 수준은 수직 축을 따라 측정되거나 사용자가 거리 수준을 표시할 수 있는데 여러 관측치는 수평 축을 따라 나열됩니다.
해석
덴드로그램을 사용하면 각 단계에서 군집이 어떻게 형성되었는지 확인하고 형성된 군집의 유사성(또는 거리) 수준을 평가할 수 있습니다.
유사성(또는 거리) 수준을 보려면 덴드로그램의 수평선 위에 포인터를 놓습니다. 한 단계에서 다음 단계로 갈 때 유사성 또는 거리 값이 바뀌는 패턴을 보면 데이터의 최종 그룹을 쉽게 선택할 수 있습니다. 값이 급격히 바뀌는 단계는 최종 그룹화를 정의하는 데 좋은 지점이 될 수 있습니다.
최종 그룹에 관해 결정하는 것을 덴드로그램 커팅이라고도 합니다. 덴드로그램 커팅은 덴드로그램에 선을 그려 최종 그룹을 지정하는 것과 유사합니다. 또한 서로 다른 최종 그룹의 덴드로그램을 비교하여 데이터에 가장 의미 있는 그룹을 결정할 수도 있습니다.
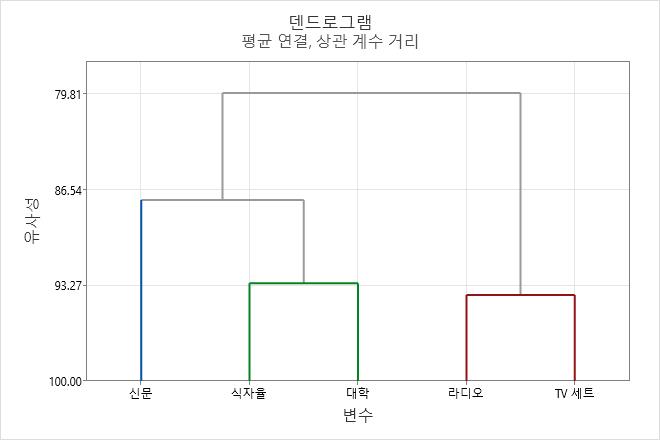
이 덴드로그램은 군집 세 개의 최종 분할을 사용하여 생성되었습니다. 각 최종 군집은 별도의 색상으로 표시됩니다. 덴드로그램은 약 88의 유사성 수준에서 "커팅"됩니다. 덴드로그램이 높이 커팅될수록 최종 군집 수가 작지만 유사성 수준은 감소합니다. 덴드로그램이 낮게 커팅될수록 유사성 수준이 더 크지만 최종 군집 수가 더 많습니다.
참고
일부 데이터 집합의 경우에는 평균, 중심, 중위수 및 Ward의 연결 방법으로 계층적 덴드로그램이 생성되지 않습니다. 즉, 결합 거리가 각 단계에서 항상 증가하지 않습니다. 덴드로그램에서 이러한 단계는 위쪽보다는 아래쪽으로 이동하는 결합을 생성합니다.