1단계: 유사성 및 거리 수준 조사
합병 공정의 각 단계에서 형성된 군집을 보고 유사성 및 거리 수준을 조사합니다. 유사성 수준이 높을수록 각 군집의 관측치가 더 유사합니다. 거리 수준이 낮을수록 각 군집의 관측치가 서로 더 가깝습니다.
이상적으로 군집의 유사성 수준은 상대적으로 높고 거리 수준은 상대적으로 낮습니다. 그러나 합리적이고 실제적인 수의 군집을 사용하여 이 목표의 균형을 맞추어야 합니다.
합병 단계
| 단계 | 군집 수 | 유사성 수준 | 거리 수준 | 결합된 군집 | 새 군집 | 새 군집의 관측치 수 | |
|---|---|---|---|---|---|---|---|
| 1 | 19 | 96.6005 | 0.16275 | 13 | 16 | 13 | 2 |
| 2 | 18 | 95.4642 | 0.21715 | 17 | 20 | 17 | 2 |
| 3 | 17 | 95.2648 | 0.22669 | 6 | 9 | 6 | 2 |
| 4 | 16 | 92.9178 | 0.33905 | 17 | 18 | 17 | 3 |
| 5 | 15 | 90.5296 | 0.45339 | 11 | 15 | 11 | 2 |
| 6 | 14 | 90.3124 | 0.46378 | 12 | 19 | 12 | 2 |
| 7 | 13 | 88.2431 | 0.56285 | 2 | 14 | 2 | 2 |
| 8 | 12 | 88.2431 | 0.56285 | 5 | 8 | 5 | 2 |
| 9 | 11 | 85.9744 | 0.67146 | 6 | 10 | 6 | 3 |
| 10 | 10 | 83.0639 | 0.81080 | 7 | 13 | 7 | 3 |
| 11 | 9 | 83.0639 | 0.81080 | 1 | 3 | 1 | 2 |
| 12 | 8 | 81.4039 | 0.89027 | 2 | 17 | 2 | 5 |
| 13 | 7 | 79.8185 | 0.96617 | 6 | 11 | 6 | 5 |
| 14 | 6 | 78.7534 | 1.01716 | 4 | 12 | 4 | 3 |
| 15 | 5 | 66.2112 | 1.61760 | 2 | 5 | 2 | 7 |
| 16 | 4 | 62.0036 | 1.81904 | 1 | 6 | 1 | 7 |
| 17 | 3 | 41.0474 | 2.82229 | 1 | 4 | 1 | 10 |
| 18 | 2 | 40.1718 | 2.86421 | 2 | 7 | 2 | 10 |
| 19 | 1 | 0.0000 | 4.78739 | 1 | 2 | 1 | 20 |
주요 결과: 유사성 수준, 거리 수준
이 결과에서 데이터에는 총 20개의 관측치가 포함됩니다. 1단계에서는 두 군집(워크시트의 관측치 13과 16)이 결합하여 새 군집을 형성합니다. 데이터에는 유사성 수준이 96.6005이고 거리 수준이 0.16275인 19개의 군집이 생성됩니다. 유사성 수준이 높고 거리 수준이 낮아도 군집 수가 너무 많아 유용하지 않습니다. 이후의 각 단계에서는 새 군집이 형성됨에 따라 유사성 수준이 감소하고 거리 수준이 증가합니다. 최종 단계에서 모든 관측치는 하나의 군집으로 결합합니다.
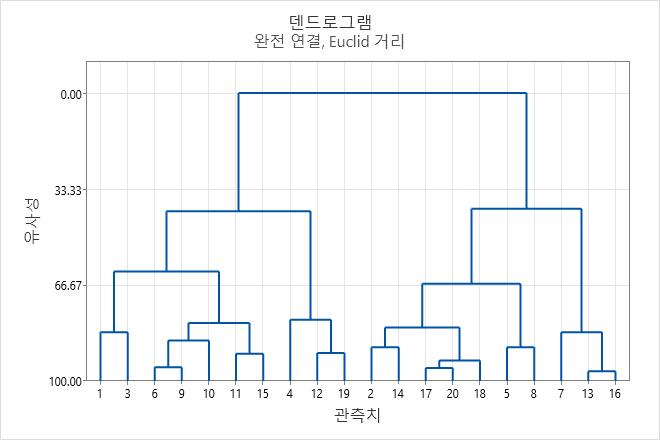
덴드로그램에서 유사성 수준을 보려면 Minitab에서 트리 다이어그램의 수평선 위에 포인터를 놓습니다.
2단계: 데이터에 대한 최종 그룹화 결정
데이터에 대한 최종 그룹을 결정하려면 각 단계에서 결합된 군집에 대한 유사성 수준을 사용합니다.단계 간에 유사성 수준이 급격하게 변경되었는지 확인합니다. 유사성이 급격하게 변경되기 전의 단계가 최종 분할에 대한 좋은 컷오프 점을 제공할 수도 있습니다. 최종 분할의 경우 군집의 유사성 수준이 상당히 높아야 합니다. 또한 연구에 가장 유의한 최종 그룹을 결정하려면 데이터에 대한 실제 지식을 활용해야 합니다.
예를 들어, 다음 합병 표는 유사성 수준이 15단계까지 약 3 이하씩 감소한다는 것을 보여줍니다. 군집 수가 4에서 3으로 변경되는 16, 17단계에서는 유사성이 (62.0036에서 41.0474로) 약 20 이상씩 감소하며, 이 결과는 4개의 군집이 최종 분할에 충분할 수 있음을 나타냅니다. 이 그룹화 방식이 직관적인 의미를 가지면 이 방식을 선택하는 것이 좋습니다.
합병 단계
| 단계 | 군집 수 | 유사성 수준 | 거리 수준 | 결합된 군집 | 새 군집 | 새 군집의 관측치 수 | |
|---|---|---|---|---|---|---|---|
| 1 | 19 | 96.6005 | 0.16275 | 13 | 16 | 13 | 2 |
| 2 | 18 | 95.4642 | 0.21715 | 17 | 20 | 17 | 2 |
| 3 | 17 | 95.2648 | 0.22669 | 6 | 9 | 6 | 2 |
| 4 | 16 | 92.9178 | 0.33905 | 17 | 18 | 17 | 3 |
| 5 | 15 | 90.5296 | 0.45339 | 11 | 15 | 11 | 2 |
| 6 | 14 | 90.3124 | 0.46378 | 12 | 19 | 12 | 2 |
| 7 | 13 | 88.2431 | 0.56285 | 2 | 14 | 2 | 2 |
| 8 | 12 | 88.2431 | 0.56285 | 5 | 8 | 5 | 2 |
| 9 | 11 | 85.9744 | 0.67146 | 6 | 10 | 6 | 3 |
| 10 | 10 | 83.0639 | 0.81080 | 7 | 13 | 7 | 3 |
| 11 | 9 | 83.0639 | 0.81080 | 1 | 3 | 1 | 2 |
| 12 | 8 | 81.4039 | 0.89027 | 2 | 17 | 2 | 5 |
| 13 | 7 | 79.8185 | 0.96617 | 6 | 11 | 6 | 5 |
| 14 | 6 | 78.7534 | 1.01716 | 4 | 12 | 4 | 3 |
| 15 | 5 | 66.2112 | 1.61760 | 2 | 5 | 2 | 7 |
| 16 | 4 | 62.0036 | 1.81904 | 1 | 6 | 1 | 7 |
| 17 | 3 | 41.0474 | 2.82229 | 1 | 4 | 1 | 10 |
| 18 | 2 | 40.1718 | 2.86421 | 2 | 7 | 2 | 10 |
| 19 | 1 | 0.0000 | 4.78739 | 1 | 2 | 1 | 20 |
주요 결과: 유사성 수준, 군집 수
최종 그룹화에 대해 결정하는 것을 덴드로그램 커팅이라고도 합니다. 덴드로그램 커팅은 덴드로그램에 수평선을 그려 최종 그룹화를 지정하는 것과 유사합니다. 예를 들어, 이 덴드로그램을 네 개의 군집으로 커팅하려면 약 41의 유사성 수준 바로 아래 수직 축의 중간 부분에 아래 방향으로 수평선을 그린다고 가정합니다.
3단계: 최종 분할 조사
2단계에서 최종 그룹을 결정한 후 분석을 다시 실행하고 최종 분할을 위한 군집 수(또는 유사성 수준)를 지정합니다. Minitab에서는 최종 분할에서 각 군집의 특성을 보여주는 최종 분할 표를 표시합니다. 예를 들어, 중심으로부터의 평균 거리는 각 군집 내 관측치의 변동성 측도입니다.
참고
이 통계량에 대한 자세한 내용은 최종 분할에서 확인하십시오.
최종 분할
| 관측치 수 | 군집 내 제곱합 | 중심으로부터 평균 거리 | 중심으로부터 최대 거리 | |
|---|---|---|---|---|
| 군집1 | 7 | 3.25713 | 0.612540 | 1.12081 |
| 군집2 | 7 | 2.72247 | 0.581390 | 0.95186 |
| 군집3 | 3 | 0.55977 | 0.398964 | 0.54907 |
| 군집4 | 3 | 0.37116 | 0.326533 | 0.48848 |
군집 중심
| 변수 | 군집1 | 군집2 | 군집3 | 군집4 | 총 중심 |
|---|---|---|---|---|---|
| 성별 | 0.97468 | -0.97468 | 0.97468 | -0.97468 | -0.0000000 |
| 키 | -1.00352 | 1.01283 | -0.37277 | 0.35105 | 0.0000000 |
| 무게 | -0.90672 | 0.93927 | -0.86797 | 0.79203 | -0.0000000 |
| 잘 쓰는 손 | 0.63808 | 0.63808 | -1.48885 | -1.48885 | 0.0000000 |
군집 중심 간 거리
| 군집1 | 군집2 | 군집3 | 군집4 | |
|---|---|---|---|---|
| 군집1 | 0.00000 | 3.35759 | 2.21882 | 3.61171 |
| 군집2 | 3.35759 | 0.00000 | 3.67557 | 2.23236 |
| 군집3 | 2.21882 | 3.67557 | 0.00000 | 2.66074 |
| 군집4 | 3.61171 | 2.23236 | 2.66074 | 0.00000 |
주요 결과: 최종 분할, 덴드로그램
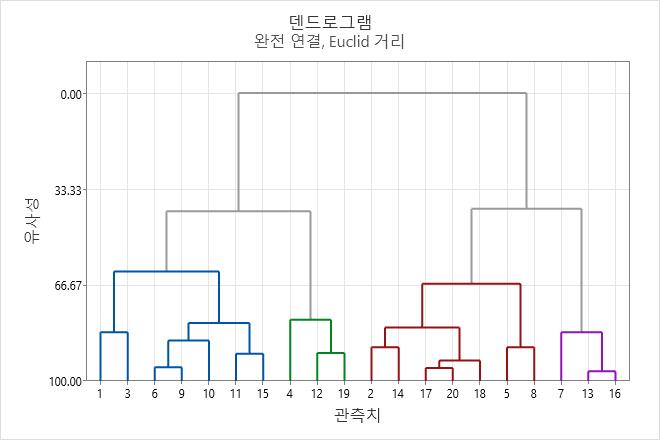
이 덴드로그램은 약 40의 유사성 수준에서 발생하는 군집 4개의 최종 분할을 사용하여 생성되었습니다. 첫 번째 군집(가장 왼쪽)은 7개의 관측치(워크시트의 1, 3, 6, 9, 10, 11, 15행의 관측치)로 구성됩니다. 바로 오른쪽의 두 번째 군집은 3개의 관측치(워크시트의 4, 12, 19행의 관측치)로 구성됩니다. 세 번째 군집은 7개의 관측치(2, 14, 17, 20, 18, 5, 8행의 관측치)로 구성됩니다. 가장 오른쪽의 네 번째 군집은 3개의 관측치(7, 13, 16행의 관측치)로 구성됩니다. 덴드로그램을 높이 커팅할수록 최종 군집 수가 작지만 유사성 수준이 낮아집니다. 덴드로그램을 낮게 커팅할수록 유사성 수준이 더 높지만 최종 군집 수가 많습니다.