한 스포츠 용품 회사의 디자이너가 새 축구 골키퍼 장갑을 검사하려고 합니다. 디자이너는 선수 20명에게 새 장갑을 착용하도록 하고 선수의 성별, 키, 몸무게, 잘 쓰는 손에 대한 정보를 수집합니다. 디자이너는 이러한 범주의 유사성을 기준으로 선수들을 분류하려고 합니다.
- 표본 데이터 집합장갑시험자.MWX을 엽니다.
- 을 선택합니다.
- 변수 또는 거리 행렬에 성별키무게잘 쓰는 손을 입력합니다.
- 연결 방법에서 완전을 선택합니다. 거리 측도에서 Euclid을 선택합니다.
- 변수 표준화을 선택합니다.
- 덴드로그램 표시을 선택합니다.
- 확인을 클릭합니다.
결과 해석
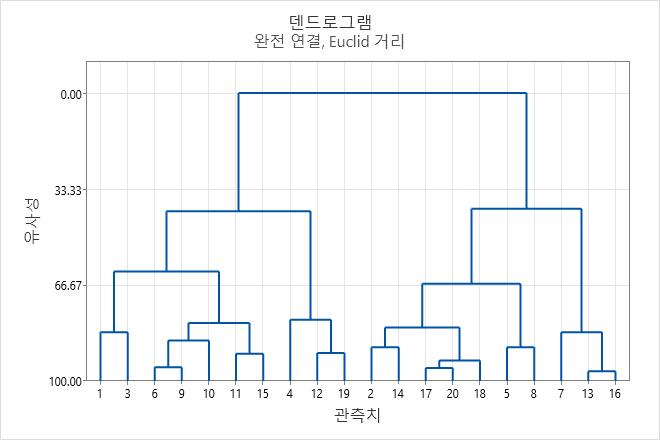
표에는 각 단계에서 결합된 군집, 군집 사이의 거리, 군집의 유사성이 표시됩니다.
- 유사성 수준은 15단계까지 약 3 이하씩 감소합니다. 군집 수가 4에서 3으로 변경되는 16단계와 17단계에서는 유사성 수준이 (62.0036에서 41.0474로) 20 이상 감소합니다.
- 결합된 군집 사이의 거리는 처음에 약 0.6 이하 감소합니다. 군집 수가 4에서 3으로 변경되는 16단계와 17단계에서는 거리 수준이 (1.81904에서 2.82229로) 1 이상 증가합니다.
거리 및 유사성 결과는 4개의 군집이 최종 분할에 충분하다는 것을 나타냅니다. 이 그룹화 방식이 설계자에게 직관적인 의미를 가지면 이 방식을 선택하는 것이 좋습니다. 덴드로그램에서는 표의 정보를 트리 다이어그램 형식으로 표시합니다.
설계자는 분석을 다시 실행하고 최종 분할에 4개의 군집을 지정해야 합니다. 최종 분할을 지정하면 Minitab에서 최종 분할에 포함된 각 군집의 특성을 설명하는 추가 표를 표시합니다.
표준화 변수, Euclid 거리, 완전 연결
합병 단계
| 단계 | 군집 수 | 유사성 수준 | 거리 수준 | 결합된 군집 | 새 군집 | 새 군집의 관측치 수 | |
|---|---|---|---|---|---|---|---|
| 1 | 19 | 96.6005 | 0.16275 | 13 | 16 | 13 | 2 |
| 2 | 18 | 95.4642 | 0.21715 | 17 | 20 | 17 | 2 |
| 3 | 17 | 95.2648 | 0.22669 | 6 | 9 | 6 | 2 |
| 4 | 16 | 92.9178 | 0.33905 | 17 | 18 | 17 | 3 |
| 5 | 15 | 90.5296 | 0.45339 | 11 | 15 | 11 | 2 |
| 6 | 14 | 90.3124 | 0.46378 | 12 | 19 | 12 | 2 |
| 7 | 13 | 88.2431 | 0.56285 | 2 | 14 | 2 | 2 |
| 8 | 12 | 88.2431 | 0.56285 | 5 | 8 | 5 | 2 |
| 9 | 11 | 85.9744 | 0.67146 | 6 | 10 | 6 | 3 |
| 10 | 10 | 83.0639 | 0.81080 | 7 | 13 | 7 | 3 |
| 11 | 9 | 83.0639 | 0.81080 | 1 | 3 | 1 | 2 |
| 12 | 8 | 81.4039 | 0.89027 | 2 | 17 | 2 | 5 |
| 13 | 7 | 79.8185 | 0.96617 | 6 | 11 | 6 | 5 |
| 14 | 6 | 78.7534 | 1.01716 | 4 | 12 | 4 | 3 |
| 15 | 5 | 66.2112 | 1.61760 | 2 | 5 | 2 | 7 |
| 16 | 4 | 62.0036 | 1.81904 | 1 | 6 | 1 | 7 |
| 17 | 3 | 41.0474 | 2.82229 | 1 | 4 | 1 | 10 |
| 18 | 2 | 40.1718 | 2.86421 | 2 | 7 | 2 | 10 |
| 19 | 1 | 0.0000 | 4.78739 | 1 | 2 | 1 | 20 |
최종 분할
| 관측치 수 | 군집 내 제곱합 | 중심으로부터 평균 거리 | 중심으로부터 최대 거리 | |
|---|---|---|---|---|
| 군집1 | 20 | 76 | 1.91323 | 2.53613 |