이 항목의 내용
1단계: 반응의 변동에 가장 기여하는 항 확인
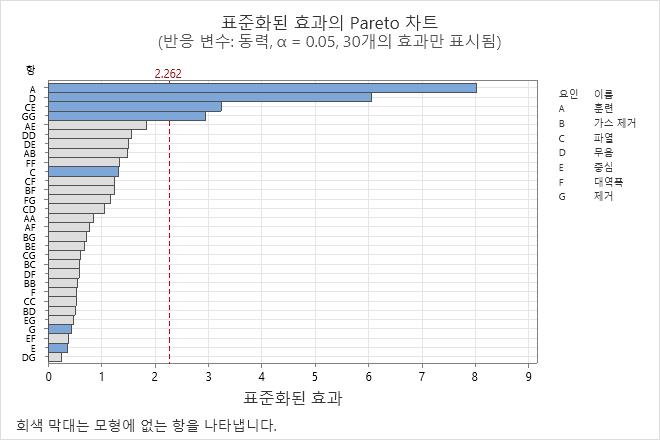
표준화된 효과의 Pareto 차트를 사용하여 효과의 상대적 크기 및 통계적 유의성을 비교할 수 있습니다.
Minitab은 각 표준화된 효과의 절대값을 내림차순으로 표시합니다. 이때 차트의 기준선은 통계적으로 유의한 효과를 나타냅니다.
주요 결과: Pareto 차트
이 결과에서는 모형에 포함된 항이 파란색 막대로 표시됩니다. 모형에 포함되지 않은 항은 회색 막대로 표시됩니다. 이 그림은 2개의 주효과가 α = 0.05 유의 수준에서 통계적으로 유의하다는 것을 보여줍니다. 2차 항과 교호작용 효과도 유의합니다. 교호작용 및 2차 항의 일부인 주효과는 통계적으로 유의하지 않더라도 모형에 포함됩니다.
또한 A 막대의 길이가 가장 길기 때문에 이 효과가 가장 크다는 것을 알 수 있습니다. EE 2차 항에 대한 효과가 차트에서 가장 작은 효과입니다.
2단계: 반응에 통계적으로 유의한 영향을 미치는 항 확인
- p-값 ≤ α: 연관성이 통계적으로 유의합니다.
- p-값이 유의 수준보다 작거나 같으면 반응 변수와 항 간에 통계적으로 유의한 연관성이 있다는 결론을 내릴 수 있습니다.
- p-값 > α: 연관성이 통계적으로 유의하지 않습니다.
- p-값이 유의 수준보다 크면 반응 변수와 항 간에 통계적으로 유의한 연관성이 있다는 결론을 내릴 수 없습니다. 항 없이 모형을 다시 적합시킬 수도 있습니다.
- 요인
- 요인에 대한 계수가 통계적으로 유의하면 요인에 대한 계수가 0이 아니라는 결론을 내릴 수 있습니다.
- 요인 간의 교호작용
- 교호작용 항에 대한 계수가 통계적으로 유의하면 요인과 반응의 관계가 항의 다른 요인에 따라 다르다는 결론을 내릴 수 있습니다.
- 2차 항
- 2차 항에 대한 계수가 통계적으로 유의하면 반응 표면에 곡면성이 있다는 결론을 내릴 수 있습니다.
- 공변량
- 공변량에 대한 계수가 통계적으로 유의하면 반응과 공변량 간의 연관성이 통계적으로 유의하다는 결론을 내릴 수 있습니다.
- 블럭
- 블럭에 대한 계수가 통계적으로 유의하면 해당 블럭의 반응 값 평균이 반응의 전체 평균과 다르다는 결론을 내릴 수 있습니다.
코드화된 계수
| 항 | 계수 | SE 계수 | T-값 | P-값 | VIF |
|---|---|---|---|---|---|
| 상수 | 617.1 | 15.0 | 41.16 | 0.000 | |
| 훈련 | 52.41 | 6.53 | 8.02 | 0.000 | 1.00 |
| 파열 | 8.62 | 6.53 | 1.32 | 0.220 | 1.00 |
| 무음 | -39.59 | 6.53 | -6.06 | 0.000 | 1.00 |
| 중심 | -2.36 | 6.53 | -0.36 | 0.727 | 1.00 |
| 제거 | 2.84 | 6.53 | 0.44 | 0.674 | 1.00 |
| 제거*제거 | 49.4 | 16.7 | 2.95 | 0.016 | 1.16 |
| 파열*중심 | 24.63 | 7.59 | 3.25 | 0.010 | 1.16 |
주요 결과: p-값, 계수
이 결과에서 훈련 및 무음에 대한 주효과는 0.05 수준에서 통계적으로 유의합니다. 이러한 변수의 변화가 반응 변수의 변화와 연관되어 있다는 결론을 내릴 수 있습니다.
제거에 대한 주효과는 통계적으로 유의하지 않지만 2차 효과는 유의합니다. 이러한 변수의 변화가 반응 변수의 변화와 연관되어 있지만 연관성이 선형이 아니라는 결론을 내릴 수 있습니다.
파열 및 중심에 대한 주효과는 통계적으로 유의하지 않지만 교호작용 효과는 유의합니다. 이러한 변수의 변화가 반응 변수의 변화와 연관되어 있지만 효과는 다른 요인에 종속된다는 결론을 내릴 수 있습니다.
3단계: 모형이 데이터를 얼마나 잘 적합시키는지 확인
모형이 데이터를 얼마나 잘 적합시키는지 확인하려면 모형 요약 표의 적합도 통계량을 조사합니다.
- S
-
S는 모형이 반응을 얼마나 잘 설명하는지 평가하기 위해 사용합니다.
S는 반응 변수 단위로 측정되며, 데이터 값이 적합치로부터 얼마나 떨어져 있는지 나타냅니다. S의 값이 낮을수록 모형이 반응을 더 잘 설명합니다. 그러나 낮은 S 값 자체는 모형이 모형 가정을 충족한다는 것을 나타내지 않습니다. 가정을 확인하려면 잔차 그림을 확인해야 합니다.
- R-제곱
-
R2 값이 클수록 모형이 데이터를 더 잘 적합시킵니다. R2은 항상 0%에서 100% 사이입니다.
모형에 예측 변수를 추가하면 R2은 항상 증가합니다. 예를 들어, 최량 예측 변수가 5개인 모형은 최량 예측 변수가 4개인 모형보다 항상 R2 값이 큽니다. 따라서 R2은 같은 크기의 모형을 비교할 때 가장 유용합니다.
- R-제곱(수정)
-
예측 변수 수가 다른 여러 모형을 비교하려면 수정 R2을 사용합니다. 모형에 예측 변수를 추가하면 모형이 실제로 개선되지 않더라도 R2은 항상 증가합니다. 수정 R2 값은 모형의 예측 변수 수에 통합되어 올바른 모형을 선택하는 데 도움이 됩니다.
- R-제곱(예측)
-
모형의 새 관측치에 대한 반응을 얼마나 잘 예측하는지 확인하려면 예측 R2을 사용합니다. 모형의 예측 R2 값이 클수록 예측 능력이 더 좋습니다.
예측 R2이 R2보다 상당히 작으면 모형이 과다 적합하다는 것을 나타낼 수도 있습니다. 모집단에서 중요하지 않은 효과에 대한 항을 추가할 경우 과다 적합 모형이 발생할 수 있습니다. 모형이 표본 데이터에 따라 조정되므로, 모집단에 대해 예측 시 유용하지 않을 수도 있습니다.
예측 R2은 또한 모형 계산에 포함되지 않은 관측치를 사용하여 계산되므로, 모형을 비교할 때 수정 R2보다 유용할 수 있습니다.
- AICc 및 BIC
- 단계적 방법의 각 단계에 대한 자세한 내용을 표시하거나 분석의 확장된 결과를 표시할 때 Minitab에서는 두 개의 통계량을 더 표시합니다. 이들 통계량은 교정된 AIC(Akaike Information Criterion) 및 BIC(Bayesian Information Criterion)입니다. 여러 모형을 비교하려면 이들 통계량을 사용하십시오. 각 통계량에 대해 작은 값을 사용하는 것이 바람직합니다.
- 작은 표본은 반응과 예측 변수 간 관계의 강도에 대한 정확한 추정치를 제공하지 않습니다. 예를 들어, 더 정확한 R2이 필요하면 더 큰 표본을 사용해야 합니다(일반적으로 40 이상).
- 적합도 통계량은 모형이 데이터를 얼마나 잘 적합시키는 지에 대한 하나의 측도에 지나지 않습니다. 모형에 바람직한 값이 있더라도 해당 모형이 모형 가정을 충족하는지 확인하려면 잔차 그림을 확인해야 합니다.
모형 요약
| S | R-제곱 | R-제곱(수정) | R-제곱(예측) |
|---|---|---|---|
| 24.4482 | 93.68% | 88.77% | 76.78% |
주요 결과: S, R-제곱, R-제곱(수정), R-제곱(예측)
이 결과에서는 모형이 변동의 93.68%를 설명합니다. 이 데이터의 경우 R2 값은 모형이 데이터에 좋은 적합치를 제공한다는 것을 나타냅니다. 다른 항을 사용하여 추가 모형을 적합화하는 경우 수정 R2 값과 예측 R2 값을 비교하여 모형이 데이터를 얼마나 잘 적합하는지 비교하십시오.
4단계: 모형이 분석의 가정을 충족하는지 여부 확인
모형이 적절하고 분석의 가정을 충족하는지 여부를 확인하려면 잔차 그림을 사용합니다. 가정이 충족되지 않으면 모형이 데이터에 적합하지 않은 것이므로 결과를 해석할 때 주의해야 합니다.
잔차 그림의 패턴을 처리하는 방법에 대한 자세한 내용을 보려면 확정 선별 설계 분석의 잔차 그림으로 이동하여 페이지 상단의 리스트에서 잔차 그림의 이름을 클릭하십시오.
잔차 대 적합치 그림
다음 표의 패턴들은 모형이 모형 가설을 충족하지 않음을 나타낼 수 있습니다.| 패턴 | 패턴이 나타내는 내용 |
|---|---|
| 적합치에 대해 잔차가 부채꼴 모양으로 흩어져 있거나 고르지 않게 퍼져 있음 | 일정하지 않은 분산 |
| 곡선 | 고차 항 누락 |
| 한 점이 0에서 멀리 떨어져 있음 | 특이치 |
| 다른 점에서 x 방향으로 멀리 떨어져 있는 점 | 영향력 있는 점 |
잔차가 랜덤하게 분포되어 있고 잔차의 분산이 일정하다는 가정을 확인하려면 잔차 대 적합치 그림을 사용합니다. 이상적으로는 점들이 식별 가능한 패턴 없이 0의 양쪽에 랜덤하게 분포해야 합니다.
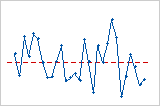
잔차 대 순서 그림
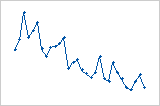
추세
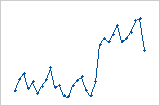
이동
주기
잔차 정규 확률도
잔차가 정규 분포를 따른다는 가정을 확인하려면 잔차의 정규 확률도를 사용합니다. 잔차의 정규 확률도는 대략 직선을 따라야 합니다.
다음 표의 패턴들은 모형이 모형 가설을 충족하지 않음을 나타낼 수 있습니다.
| 패턴 | 패턴이 나타내는 내용 |
|---|---|
| 직선이 아님 | 비정규성 |
| 선에서 멀리 떨어져 있는 점 | 특이치 |
| 기울기 변화 | 식별되지 않은 변수 |