제곱합(SS)
거리 제곱의 합입니다. 여기에 제시된 공식은 A와 B 요인이 포함된 완전 요인 2-요인 모형에 대한 공식입니다. 이 공식은 요인이 세 개 이상인 모형으로 확장할 수 있습니다. 자세한 내용은 Montgomery1에서 확인하십시오.
SS 전체는 모형의 총 변동입니다. SS(A) 및 SS(B)는 전체 평균에 대한 추정된 요인 수준 평균의 편차 제곱의 합입니다. SS 오차는 잔차 제곱의 합으로, 처리 내 오차라고도 합니다. 다음과 같이 계산됩니다.





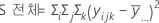
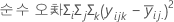
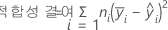
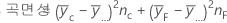


- D.C. Montgomery (1991). Design and Analysis of Experiments, Third Edition, John Wiley & Sons.
표기법
| 용어 | 설명 |
|---|---|
| a | 요인 A의 수준 수 |
| b | 요인 B의 수준 수 |
| n | 총 반복실험 횟수 |
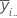 | 요인 A의 i번째 수준의 평균 |
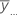 | 모든 관측치의 전체 평균 |
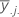 | 요인 B의 j번째 요인 수준의 평균 |
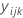 | 요인 A의 i번째 수준, 요인 B의 j번째 수준, k번째 반복실험에서의 관측치 |
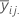 | 요인 A의 i번째 수준과 요인 B의 j번째 수준의 평균 |
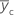 | 중앙점에 대한 평균 반응 |
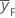 | 요인 설계점에 대한 평균 반응 |
| nF | 요인 설계점의 수 |
순차 제곱합
Minitab에서는 변동의 SS 회귀 분석 또는 처리 성분을 각 요인의 순차 제곱합으로 세분화합니다. 순차 제곱합은 모형에 요인 또는 예측 변수를 입력한 순서에 따라 다릅니다. 순차 제곱합은 이전에 요인을 입력한 경우 SS 회귀 분석에서 한 요인만으로 설명되는 부분을 나타냅니다.
예를 들어 X1, X2, X3 등 요인 또는 예측 변수가 세 개인 모형의 경우 X2의 순차 제곱합은 X1이 모형에 포함된 상태에서 X2에 의해 설명되는 분산의 정도를 나타냅니다. 요인의 다른 순서를 얻으려면 분석을 반복하고 다른 순서로 요인을 입력합니다.
수정 제곱합
수정 제곱합은 항을 모형에 입력하는 순서에 의존하지 않습니다. 항을 모형에 입력한 순서에 관계없이 다른 모든 항이 주어진 경우 수정 제곱합은 항에 의해 설명되는 변동량입니다.
예를 들어 X1, X2, X3 등 요인이 세 개인 모형의 경우 X2의 수정 제곱합은 X1과 X3에 대한 항도 모형에 포함된 상태에서 X2에 대한 항에 의해 설명되는 분산의 정도를 나타냅니다.
세 요인에 대한 수정 제곱합은 다음과 같이 계산됩니다.
- SSR(X3 | X1, X2) = SSE (X1, X2) - SSE (X1, X2, X3) 또는
- SSR(X3 | X1, X2) = SSR (X1, X2, X3) - SSR (X1, X2)
여기서 SSR(X3 | X1, X2)은 X1과 X2가 모형에 있는 경우 X3에 대한 수정 제곱합입니다.
- SSR(X2, X3 | X1) = SSE (X1) - SSE (X1, X2, X3) 또는
- SSR(X2, X3 | X1) = SSR (X1, X2, X3) - SSR (X1)
여기서 SSR(X3 | X1, X2)은 X1이 모형에 있는 경우 X2와 X3에 대한 수정 제곱합입니다.
모형에 4개 이상의 요인이 있는 경우 이 공식을 확장할 수 있습니다1.
- J. Neter, W. Wasserman and M.H. Kutner (1985). Applied Linear Statistical Models, Second Edition. Irwin, Inc.
자유도(DF)
요인 A와 B, 블럭화 변수가 포함된 완전 요인 설계의 경우 각 제곱합과 연관된 자유도는 다음과 같습니다.


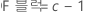

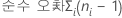

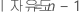
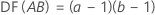
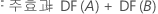
중앙점이 있는 2-수준 설계의 경우 곡면성에 대한 자유도는 1입니다.
표기법
| 용어 | 설명 |
|---|---|
| a | 요인 A의 수준 수 |
| b | 요인 B의 수준 수 |
| c | 블럭 수 |
| n | 총 관측치 수 |
| ni | i번째 요인 수준 조합에 대한 관측치 수 |
| m | 요인 수준 조합의 수 |
| p | 계수의 수 |
Adj MS - 항

F
교호작용 및 주효과가 유의한지 여부를 확인하기 위한 검정입니다. 모형 항에 대한 공식은 다음과 같습니다.

검정에 대한 자유도는 다음과 같습니다.
- 분자 = 항의 자유도
- 분모 = 오차의 자유도
F 값이 클수록 유의한 효과가 없다는 귀무 가설을 기각할 수 있는 확률이 높습니다.
균형 분할구 설계의 경우 변경하기 어려운 요인에 대한 F 통계량은 분모에 주구 오차에 대한 MS를 사용합니다. 다른 분할구 설계의 경우 Minitab에서는 WP 오차와 SP 오차의 선형 조합을 사용하여 기대 평균 제곱을 기반으로 하는 분모를 구성합니다.
p-값 – 분산 분석표
p-값은 자유도(DF)가 다음과 같은 F 분포에서 계산되는 확률입니다.
- 분자 DF
- 검정의 항에 대한 자유도의 합
- 분모 DF
- 오차에 대한 자유도
공식
1 − P(F ≤ fj)
표기법
| 용어 | 설명 |
|---|---|
| P(F ≤ f) | F-분포의 누적분포함수 |
| f | 검정에 대한 f-통계량 |
순수 오차 적합성 결여 검정
- 반복실험의 각 집합 내 평균으로부터 반응의 제곱 편차의 합을 계산한 다음 더하여 순수 오차 제곱합(SS PE)을 생성합니다.
- 순수 오차 평균 제곱
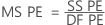

여기서 n = 관측치의 수이고 m = 고유한 x-수준 조합의 수입니다.
- 적합성 결여 제곱합
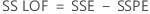
- 적합성 결여 평균 제곱

- 검정 통계량
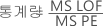
큰 F-값과 작은 p-값은 모형이 적절하지 않다는 것을 나타냅니다.
p-값 - 적합성 결여 검정
- 분자 DF
- 적합성 결여 검정의 자유도
- 분모 DF
- 순수 오차에 대한 자유도
공식
1 − P(F ≤ fj)
표기법
| 용어 | 설명 |
|---|---|
| P(F ≤ fj) | F-분포의 누적분포함수 |
| fj | 검정에 대한 f-통계량 |