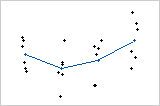
다음 두 개별 값 그림에 있는 데이터 집합의 요인 수준 평균은 모두 동일합니다. 따라서 요인으로 인한 데이터의 변동성은 두 데이터 집합에서 동일합니다. 그림을 보면 두 가지 경우에서 모두 평균이 다르다는 결론을 내릴 수도 있습니다. 그러나 요인 수준 내의 변동성이 첫 번째 데이터 집합보다 두 번째 데이터 집합에서 훨씬 크다는 점에 유의해야 합니다.
평균들 사이의 차이를 평가하려면 이러한 차이와 평균 주위에 있는 관측치의 퍼짐을 비교해야 합니다. 이것이 바로 분산 분석의 역할입니다. 분산 분석을 사용하면 첫 번째 그림에 해당하는 p-값은 0.000이고 두 번째 그림에 해당하는 p-값은 0.109입니다.
따라서 검정에서 유의 수준으로 0.05를 사용하는 경우 첫 번째 데이터 집합의 평균들은 유의하게 다릅니다. 그러나 두 번째 데이터 집합에 대한 표본 평균들의 차이는 전체적으로 큰 데이터 변동성의 랜덤한 결과일 수 있습니다.
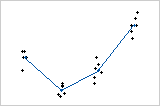
변동성이 낮은 그림