귀무 가설, 대립 가설
등분산 검정은 두 개 이상의 모집단 표준 편차에 대해 서로 배타적인 두 문장을 평가하는 가설 검정입니다. 두 문장을 귀무 가설과 대립 가설이라고 합니다. 가설 검정은 표본 데이터를 사용하여 귀무 가설의 기각 여부를 확인합니다.
- 귀무 가설(H0)
- 귀무 가설은 모집단 표준 편차가 모두 같다는 것입니다.
- 대립 가설(HA)
- 대립 가설은 모든 모집단 표준 편차가 같지는 않다는 것입니다.
해석
귀무 가설의 기각 여부를 확인하려면 p-값을 유의 수준과 비교하십시오.
N
표본 크기(N)는 각 그룹의 총 관측치 수입니다.
해석
표본 크기는 신뢰 구간 및 검정의 검정력에 영향을 미칩니다.
일반적으로 표본이 클수록 신뢰 구간이 좁아집니다. 또한 표본 크기가 클수록 차이를 탐지하기 위한 검정력이 더 높습니다.
표준 편차
표준 편차는 산포, 즉 데이터가 평균을 중심으로 퍼져 있는 정도를 나타내는 가장 일반적인 측도입니다. 모집단의 표준 편차를 나타내는 데는 일반적으로 기호 σ(시그마)가 사용됩니다. 표본의 표준 편차를 나타내는 데는 일반적으로 기호 s가 사용됩니다.
해석
표준 편차는 변수와 동일한 단위를 사용합니다. 표준 편차 값이 클수록 데이터가 더 퍼져 있다는 것을 나타냅니다. 정규 분포를 따르는 데이터에 대한 지침은 대략 68%의 값이 평균으로부터 1 표준 편차 거리 내에 있고, 95%의 값이 2 표준 편차 거리 내에 있고, 99.7%의 값이 3 표준 편차 거리 내에 있다는 것입니다.
Bonferroni 신뢰 구간
범주형 요인을 기반으로 각 모집단의 표준 편차를 추정하려면 Bonferroni 신뢰 구간을 사용합니다. 각 신뢰 구간은 해당 모집단의 표준 편차가 포함될 수 있는 값의 범위입니다. Minitab에서는 Bonferroni 신뢰 구간을 조정하여 동시 신뢰 수준을 유지합니다.
동시 신뢰 구간을 관리하는 것은 여러 개의 신뢰 구간을 평가할 때 특히 중요합니다. 동시 신뢰 수준을 관리하지 않을 경우, 신뢰 구간의 수가 증가하면 하나 이상의 신뢰 구간에 실제 표준 편차가 포함되지 않을 확률이 증가합니다.
자세한 내용은 다중 비교의 개별 및 동시 신뢰 구간 이해 및 Bonferroni 방법의 정의를 참조하십시오.
참고
그룹 쌍 간의 차이가 통계적으로 유의한지 여부를 확인하기 위해 이러한 Bonferroni 신뢰 구간을 사용할 수 없습니다. 차이의 통계적 유의성을 확인하려면 요약도의 p-값과 다중 비교 신뢰 구간을 사용하십시오.
해석
방법
| 귀무 가설 | 모든 분산이 동일합니다. |
|---|---|
| 대립 가설 | 하나 이상의 분산이 다릅니다. |
| 유의 수준 | α = 0.05 |
표준 편차의 95% Bonferroni 신뢰 구간
| 비료 | N | 표준 편차 | CI |
|---|---|---|---|
| GrowFast | 50 | 4.28743 | (3.43659, 5.61790) |
| 사용하지 않음 | 50 | 5.09137 | (4.24793, 6.40914) |
| SuperPlant | 49 | 5.49969 | (4.48577, 7.08914) |
이 결과에서 95% Bonferroni 신뢰 구간은 전체 신뢰 구간의 집합에 모든 그룹에 대한 실제 모집단 표준 편차가 포함된다고 95% 신뢰할 수 있다는 것을 나타냅니다. 또한 개별 신뢰 수준은 개별 신뢰 구간에 해당 특정 그룹의 모집단 표준 편차가 포함된다고 얼마나 신뢰할 수 있는지를 나타냅니다. 예를 들어, GrowFast 모집단에 대한 표준 편차가 신뢰 구간 (3.43659, 5.61790)에 있다고 98.3333% 신뢰할 수 있습니다.
개별 신뢰 수준
개별 신뢰 수준은 연구를 여러 번 반복하는 경우 단일 신뢰 구간에 해당 특정 그룹에 대한 실제 표준 편차가 포함될 횟수의 백분율입니다.
집합 내 신뢰 구간의 수가 증가하면 하나 이상의 신뢰 구간에 실제 표준 편차가 포함되지 않을 확률이 증가합니다. 동시 신뢰 수준은 전체 신뢰 구간의 집합에 모든 그룹에 대한 실제 모집단 표준 편차가 포함된다고 얼마나 신뢰할 수 있는지 나타냅니다.
해석
방법
| 귀무 가설 | 모든 분산이 동일합니다. |
|---|---|
| 대립 가설 | 하나 이상의 분산이 다릅니다. |
| 유의 수준 | α = 0.05 |
표준 편차의 95% Bonferroni 신뢰 구간
| 비료 | N | 표준 편차 | CI |
|---|---|---|---|
| GrowFast | 50 | 4.28743 | (3.43659, 5.61790) |
| 사용하지 않음 | 50 | 5.09137 | (4.24793, 6.40914) |
| SuperPlant | 49 | 5.49969 | (4.48577, 7.08914) |
각각의 개별 신뢰 구간에 해당 특정 그룹에 대한 모집단 표준 편차가 포함된다고 98.3333% 신뢰할 수 있습니다. 예를 들어, GrowFast 모집단에 대한 표준 편차가 신뢰 구간(3.43659, 5.61790)에 있다고 98.3333% 신뢰할 수 있습니다. 그러나 세 개의 신뢰 구간이 집합에 포함되어 있기 때문에 모든 구간에 실제 값이 포함되다고 95%만 신뢰할 수 있습니다.
검정
Minitab에서 표시하는 등분산 검정의 유형은 정규 분포를 바탕으로 하는 검정 사용(옵션 하위 대화 상자)을 선택했는지 여부와 데이터 내 그룹의 수에 따라 다릅니다.
다중 비교, Levene의 방법
정규 분포를 바탕으로 하는 검정 사용을 선택하지 않은 경우 Minitab에서는 다중 비교 방법과 Levene의 방법에 대한 검정 결과를 모두 표시됩니다. 대부분의 계량형 분포의 경우, 두 방법 모두 유의 수준(α 또는 알파로 표시함)에 가까운 제1종 오류율을 제공합니다. 일반적으로 다중 비교 구간이 더 강력합니다. 다중 비교 방법에 대한 p-값이 유의한 경우 요약도를 사용하여 서로 다른 표준 편차를 가진 특정 모집단을 식별할 수 있습니다.
- 각 표본의 관측치가 20개 미만입니다.
- 하나 이상의 모집단에 대한 분포가 심하게 치우쳐 있거나 두꺼운 꼬리를 가지는 모집단이 있습니다. 두꺼운 꼬리를 가진 분포는 정규 분포와 비교하여 하한과 상한에 데이터가 더 많이 있습니다.
다중 비교 검정의 p-값이 선택된 유의 수준보다 작으면 일부 표준 편차 간의 차이가 통계적으로 유의합니다. 표준 편차가 유의하게 서로 다른지 여부를 확인하려면 다중 비교 구간을 사용하십시오. 두 구간이 서로 겹치지 않으면 해당 표준 편차(및 분산)가 유의하게 서로 다릅니다.
심하게 치우쳐 있거나 꼬리가 두꺼운 분포에서 추출한 소표본의 경우 다중 비교 방법에 대한 제1종 오류율이 α보다 높을 수 있습니다. 이러한 조건에서 Levene의 방법이 다중 비교 방법보다 작은 p-값을 제공하는 경우 Levene의 방법을 기반으로 결론을 내리십시오.
F-검정, Bartlett의 검정
정규 분포를 바탕으로 하는 검정 사용을 선택하고 그룹이 두 개 있는 경우 Minitab에서 F-검정을 수행합니다. 그룹이 3개 이상 있는 경우에는 Minitab에서 Bartlett의 검정을 수행합니다.
F-검정과 Bartlett의 검정은 정규 분포 데이터에 대해서만 정확합니다. 정규성에서 벗어날 경우 검정 결과가 부정확해질 수 있습니다. 그러나 데이터가 정규 분포를 따르는 경우 일반적으로 F-검정 및 Bartlett의 검정이 다중 비교 방법이나 Levene의 방법보다 강력합니다.
검정의 p-값이 유의 수준보다 작으면 일부 표준 편차 간의 차이가 통계적으로 유의합니다.
검정 통계량
참고
다중 비교 검정은 검정 통계량을 사용하지 않습니다.
해석
Minitab에서는 검정 통계량을 사용하여 표준 편차 간 차이의 통계적 유의성에 대한 결정을 내릴 때 사용하는 p-값을 계산합니다. p-값은 귀무 가설에 반하는 증거를 측정하는 확률입니다. p-값이 작을수록 귀무 가설에 반하는 더 강력한 증거가 됩니다.
검정 통계량이 충분히 크면 일부 표준 편차 간의 차이가 통계적으로 유의하다는 것을 나타냅니다.
검정 통계량을 사용하여 귀무 가설의 기각 여부를 확인할 수 있습니다. 그러나 p-값이 해석하기 더 쉽기 때문에 더 자주 사용됩니다.
p-값
p-값은 귀무 가설에 반하는 증거를 측정하는 확률입니다. p-값이 작을수록 귀무 가설에 반하는 더 강력한 증거가 됩니다.
해석
표준 편차 간의 차이가 통계적으로 유의한지 여부를 확인하려면 p-값을 사용합니다. Minitab에서는 분산의 동일성을 평가하는 하나 또는 두 검정의 결과를 표시합니다. 두 개의 p-값이 있는 데 서로 일치하지 않는 경우에는 "검정"을 참조하십시오.
표준 편차 간의 차이가 통계적으로 유의한지 여부를 확인하려면 p-값을 유의 수준과 비교하여 귀무 가설을 평가합니다. 귀무 가설은 그룹 평균이 모두 같다는 것입니다. 일반적으로 0.05의 유의 수준(α 또는 알파로 표시함)이 적절합니다. 0.05의 유의 수준은 실제로 차이가 없는데 차이가 존재한다는 결론을 내릴 위험이 5%라는 것을 나타냅니다.
- p-값 > α이면 표준 편차 간의 차이가 통계적으로 유의하지 않습니다.
- p-값 ≤ α이면 일부 표준 편차 간의 차이가 통계적으로 유의합니다.
요약도
요약도에는 등분산 검정에 대한 p-값과 신뢰 구간이 표시됩니다. Minitab에서 표시하는 검정과 구간의 유형은 정규 분포를 바탕으로 하는 검정 사용(옵션 대화 상자)을 선택했는지 여부와 데이터 내 그룹의 수에 따라 다릅니다.
정규 분포를 바탕으로 하는 검정 사용을 선택하지 않은 경우 요약도에는 다중 비교 방법과 Levene의 방법에 대한 p-값이 모두 표시됩니다. 그림에는 다중 비교 구간도 표시됩니다. 데이터 속성을 기반으로 두 방법 중에서 선택해야 합니다.
정규 분포를 바탕으로 하는 검정 사용을 선택했고 그룹이 두 개 있는 경우 Minitab에서 F-검정을 수행합니다. 그룹이 3개 이상 있는 경우에는 Minitab에서 Bartlett의 검정을 수행합니다. 두 검정 모두 Bonferroni 신뢰 구간도 그림에 표시됩니다.
p-값
p-값은 귀무 가설에 반하는 증거를 측정하는 확률입니다. p-값이 작을수록 귀무 가설에 반하는 더 강력한 증거가 됩니다.
표준 편차 간의 차이가 통계적으로 유의한지 여부를 확인하려면 p-값을 사용합니다. Minitab에서는 분산의 동일성을 평가하는 하나 또는 두 검정의 결과를 표시합니다. 두 개의 p-값이 있는데 서로 일치하지 않는 경우에는 검정에 대한 섹션에서 어느 검정을 사용할 것인 지에 대한 정보를 참조하십시오.
표준 편차 간의 차이가 통계적으로 유의한지 여부를 확인하려면 p-값을 유의 수준과 비교하여 귀무 가설을 평가합니다. 귀무 가설은 그룹 표준 편차가 모두 같다는 것입니다. 일반적으로 0.05의 유의 수준(α 또는 알파로 표시됨)이 적절합니다. 0.05의 유의 수준은 실제로 차이가 없는데 차이가 존재한다는 결론을 내릴 위험이 5%라는 것을 나타냅니다.
- p-값 > α이면 표준 편차 간의 차이가 통계적으로 유의하지 않습니다.
- p-값 ≤ α이면 일부 표준 편차 간의 차이가 통계적으로 유의합니다.
다중 비교 구간
정규 분포를 바탕으로 하는 검정 사용을 선택하지 않은 경우 요약도에 다중 비교 구간이 표시됩니다.
다중 비교 p-값을 사용할 수 있는 경우 다중 비교 신뢰 구간을 사용하여 통계적으로 유의한 차이를 갖는 그룹 쌍을 식별할 수 있습니다. 두 구간이 겹치지 않으면 해당 표준 편차 간의 차이가 통계적으로 유의합니다.
데이터 속성에 따라 Levene의 방법을 사용해야 하는 경우 요약도의 신뢰 구간을 평가하지 마십시오.
Bonferroni 신뢰 구간
정규 분포를 바탕으로 하는 검정 사용을 선택한 경우 요약도에 Bonferroni 신뢰 구간이 표시됩니다.
범주형 요인에 대한 각 모집단의 표준 편차를 추정하려면 Bonferroni 신뢰 구간을 사용합니다. 각 신뢰 구간은 해당 모집단의 표준 편차가 포함될 수 있는 값의 범위입니다. Minitab에서는 Bonferroni 신뢰 구간을 조정하여 동시 신뢰 수준을 관리합니다.
동시 신뢰 구간을 관리하는 것은 여러 개의 신뢰 구간을 평가할 때 특히 중요합니다. 동시 신뢰 수준을 관리하지 않을 경우, 신뢰 구간의 수가 증가하면 하나 이상의 신뢰 구간에 실제 표준 편차가 포함되지 않을 확률이 증가합니다.
자세한 내용은 다중 비교의 개별 및 동시 신뢰 구간 이해 및 Bonferroni 방법의 정의를 참조하십시오.
참고
그룹 쌍 간의 차이가 통계적으로 유의한지 여부를 확인하기 위해 이러한 Bonferroni 신뢰 구간을 사용할 수 없습니다. 차이의 통계적 유의성을 확인하려면 요약도의 p-값과 다중 비교 신뢰 구간을 사용하십시오.
해석
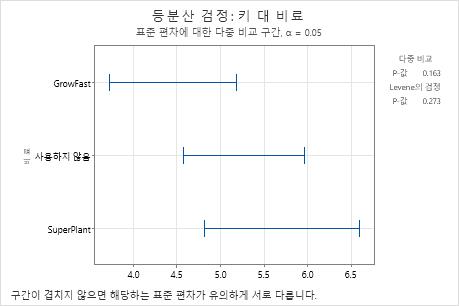
요약도에서 다중 비교 검정에 대한 p-값이 유의 수준 0.05보다 큽니다. 그룹 간의 어떠한 차이도 통계적으로 유의하지 않으며 모든 다중 비교 구간이 겹칩니다.
개별 값 그림
개별 값 그림은 각 표본 내 개별 값을 표시합니다. 개별 값 그림을 사용하면 표본을 쉽게 비교할 수 있습니다. 각 원은 하나의 관측치를 나타냅니다. 개별 값 그림은 표본 크기가 작을 때 특히 유용합니다.
해석
데이터의 산포를 평가하고 잠재적 특이치를 식별하려면 개별 값 그림을 사용합니다. 개별 값 그림은 표본 크기가 50보다 작을 때 가장 적합합니다.
- 치우친 데이터
-
데이터가 치우쳐 있는 것으로 보이는지 여부를 확인하려면 데이터의 산포를 조사합니다. 데이터가 치우쳐 있으면 대부분의 데이터가 그래프의 높은 쪽이나 낮은 쪽에 위치합니다. 치우친 데이터는 데이터가 정규 분포를 따르지 않을 수도 있음을 나타냅니다. 일반적으로 개별 값 그림, 히스토그램 또는 상자 그림에서 왜도를 탐지하기가 가장 쉽습니다.
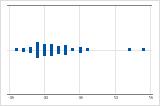
오른쪽으로 치우침
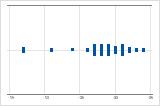
왼쪽으로 치우침
오른쪽으로 치우친 데이터의 개별 값 그림은 대기 시간을 보여줍니다. 대부분의 대기 시간이 비교적 짧고 몇 개의 대기 시간만 더 깁니다. 왼쪽으로 치우친 데이터의 개별 값 그림은 수명 데이터를 보여줍니다. 몇 개의 품목이 즉시 고장나고 더 많은 품목이 나중에 고장납니다.
- 특이치
-
다른 데이터 값에서 멀리 떨어져 있는 데이터 값인 특이치는 결과에 크게 영향을 미칠 수 있습니다. 일반적으로 개별 값 그림에서 특이치를 식별하기가 쉽습니다.
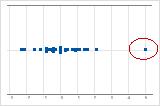
개별 값 그림에서는 비정상적으로 낮거나 높은 데이터 값이 가능한 특이치를 나타냅니다.
특이치의 원인을 식별해 보십시오. 모든 데이터 입력 또는 측정 오류를 수정하십시오. 비정상적인 일회성 사건에 대한 데이터 값을 삭제하십시오(특수 원인). 그런 다음 분석을 반복하십시오.
상자 그림
상자 그림은 각 표본 분포의 그래픽 요약을 제공합니다. 상자 그림을 사용하면 표본의 모양, 중심 위치 및 변동성을 쉽게 비교할 수 있습니다.
해석
데이터의 산포를 평가하고 잠재적 특이치를 식별하려면 상자 그림을 사용합니다. 상자 그림은 표본 크기가 20보다 클 때 가장 적합합니다.
- 치우친 데이터
-
데이터가 치우쳐 있는 것으로 보이는지 여부를 확인하려면 데이터의 산포를 조사합니다. 데이터가 치우쳐 있으면 대부분의 데이터가 그래프의 높은 쪽이나 낮은 쪽에 위치합니다. 치우친 데이터는 데이터가 정규 분포를 따르지 않을 수도 있음을 나타냅니다. 일반적으로 개별 값 그림, 히스토그램 또는 상자 그림에서 왜도를 탐지하기가 가장 쉽습니다.
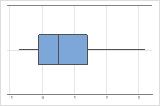
오른쪽으로 치우침
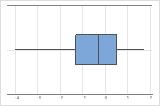
왼쪽으로 치우침
오른쪽으로 치우친 데이터의 상자 그림은 평균 대기 시간을 보여줍니다. 대부분의 대기 시간이 비교적 짧고 몇 개의 대기 시간만 더 깁니다. 왼쪽으로 치우친 데이터의 상자 그림은 고장률 데이터를 보여줍니다. 몇 개의 품목이 즉시 고장나고 더 많은 품목이 나중에 고장납니다.
심하게 치우친 데이터는 표본이 작은 경우(20보다 작은 값) p-값의 유효성에 영향을 미칠 수 있습니다. 데이터가 심하게 치우쳐 있고 표본이 작은 경우 표본 크기를 늘리는 것을 고려해 보십시오.
- 특이치
-
다른 데이터 값에서 멀리 떨어져 있는 데이터 값인 특이치는 결과에 크게 영향을 미칠 수 있습니다. 일반적으로 상자 그림에서 특이치를 식별하기가 가장 쉽습니다.
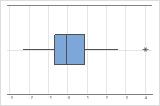
상자 그림에서는 별표(*)가 특이치를 나타냅니다.
특이치의 원인을 식별해 보십시오. 모든 데이터 입력 또는 측정 오류를 수정하십시오. 비정상적인 일회성 사건에 대한 데이터 값을 삭제하십시오(특수 원인). 그런 다음 분석을 반복하십시오.