추정 방법
제한적 최대우도법(REML) 또는 최대우도법(ML)을 선택할 수 있습니다. 일반적으로 REML의 분산 성분 추정량은 대략 치우침이 없고 ML 추정량은 치우치기 때문에 제한적 최대우도법(REML)을 추정합니다. 그러나 표본 크기가 클수록 치우침이 작아집니다.
두 모형의 랜덤 항과 오차 분산 구조가 같은 경우 고정 효과 항이 더 작은 내포된 모형이 고정 효과 항이 더 많은 해당 기준 모형만큼 적절한지 여부를 검정해야 하면 최대우도법(ML)을 사용하십시오. 특히 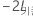 을 완전 모형의 -2 로그 우도,
을 완전 모형의 -2 로그 우도, 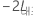 를 더 작은 모형의 -2 로그 우도로 설정하십시오.
를 더 작은 모형의 -2 로그 우도로 설정하십시오.
귀무 가설 하에서 점근적으로 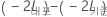 은 자유도가 기준 모형과 내포 모형 간 고정 효과 항에 대한 모수 수의 차이와 같은 카이-제곱 분포를 따릅니다. 우도 비 검정을 사용하여 고정 효과 항의 부분 집합을 기준 모형에서 제거할 수 있는지 여부를 평가하십시오. 우도 비 검정을 사용하여 고정 효과 항의 부분 집합을 기준 모형에서 제거할 수 있는지 여부를 평가하십시오.
은 자유도가 기준 모형과 내포 모형 간 고정 효과 항에 대한 모수 수의 차이와 같은 카이-제곱 분포를 따릅니다. 우도 비 검정을 사용하여 고정 효과 항의 부분 집합을 기준 모형에서 제거할 수 있는지 여부를 평가하십시오. 우도 비 검정을 사용하여 고정 효과 항의 부분 집합을 기준 모형에서 제거할 수 있는지 여부를 평가하십시오.
혼합 효과 모형에 있는 고정 모수의 우도 비 검정에 대한 자세한 내용은 B. T. West, K.B. Welch, and A.T. Gałecki (2007)을 참조하십시오. Linear Mixed Models: A Practical Guide Using Statistical Software, First Edition. Chapman and Hall/CRC (34–36).
고정 효과에 대한 검정 방법
일반적으로 계산에 작은 표본 크기의 치우침을 줄이는 조정이 포함되기 때문에 Kenward-Roger 근사을 사용합니다. Satterthwaite 근사을 사용할 수도 있습니다. 일반적으로 표본 크기가 클수록 두 방법 간의 차이가 작습니다.
가중치
가중치에 모든 반응 값에 대한 가중치의 숫자 열을 입력합니다. 반응 값 내 랜덤 오차의 분산이 일정하지 않으면 가중치을 사용하십시오. 대신, 각 반응 값에 대해 분산은 해당 가중치의 역수에 상수를 곱한 값과 같습니다.
가중치는 0 이상이어야 합니다. 가중치 열의 행 개수는 반응 열의 행 개수와 같아야 합니다.
모든 구간에 대한 신뢰 수준
결과의 모든 신뢰 구간에 대한 신뢰 수준을 입력합니다.
일반적으로 95%의 신뢰 수준이 잘 작동합니다. 95% 신뢰 수준은 관심 있는 모수에 대한 모집단에서 100개의 랜덤 표본을 추출할 경우 약 95개의 표본에 대한 신뢰 구간에 알 수 없는 모수의 실제 값이 포함된다는 것을 나타냅니다. 지정된 데이터 집합에 대해 신뢰 수준이 낮을수록 신뢰 구간이 좁아지고 신뢰 수준이 높을수록 구간이 넓어집니다.
참고
신뢰 구간을 표시하려면 결과 하위 대화 상자로 이동한 후 결과 표시에서 확장된 표을 선택해야 합니다.
신뢰 구간의 유형
양측 구간 또는 단측 구간을 선택할 수 있습니다. 동일한 신뢰 수준의 경우 한계가 구간보다 점 추정치에 더 가깝습니다. 상한은 하한이 될 수 있는 값을 제공하지 않습니다. 하한은 상한이 될 수 있는 값을 제공하지 않습니다.
- 양측
-
- 관심 있는 모수에 대한 상한 및 하한이 될 수 있는 값을 모두 추정하려면 양측 신뢰 구간을 사용합니다.
- 하한
-
- 관심 있는 모수에 대한 하한이 될 수 있는 값을 추정하려면 신뢰 하한을 사용합니다.
- 상한
-
- 관심 있는 모수에 대한 상한이 될 수 있는 값을 추정하려면 신뢰 상한을 사용합니다.
평균
주효과, 2원 교호작용 또는 모형의 모든 항에 대한 적합 평균을 결과에 표시할 수 있습니다. 또는 이러한 항의 부분 집합 또는 항이 없는 경우에 대한 평균을 표시할 수 있습니다.
지정된 항을 선택하는 경우 항에 대한 I = 항에 대한 평균 계산 단추를 사용하여 항을 식별하십시오. 리스트에서 항을 선택한 후 단추를 누르십시오. I은 항의 평균이 표시된다는 것을 의미합니다. 리스트에 표시되어야 할 항이 나타나지 않는 경우에는 항을 모형에 추가해야 합니다.