Wilk의 검정
검정 통계량, Wilk의 람다는 다음과 같습니다.
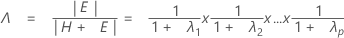
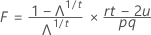
자유도가 pq 및 (rt – 2u)임.
표기법
| 용어 | 설명 |
|---|---|
| H | 가설 행렬 |
| E | 오차 행렬 |
| p | 반응값의 수 |
| q | 가설의 자유도 |
| v인 경우 | E의 자유도 |
| s | min (p, q) |
| m | .5 ( | p – q | – 1) |
| n | .5 (v – p – 1) |
| r | v – 0.5 (p – q + 1) |
| u | 0.25(pq – 2) |
| t | = Sqrt ([p2 q2 - 4] / p2 + q2 - 5, if p2 + q2 - 5 > 0 |
| t | 1 |
λ1≥λ2≥λ3≥ . . . ≥λp를 (E** - 1) * H의 고유값으로 설정합니다. 처음 세 검정 통계량은 H 및 E 또는 이러한 고유값으로 표현할 수 있습니다.
H 행렬은 대각선에 각 p 변수에 대한 "군간" 제곱합이 포함되는 p x p 행렬입니다. H 행렬은 다음과 같이 계산됩니다.

E 행렬은 대각선에 각 p 변수에 대한 "군내" 제곱합이 포함되는 p x p 행렬입니다. E 행렬은 다음과 같이 계산됩니다.
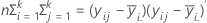
처음 세 검정에서 s = 1 또는 2이면 F 통계량이 정확하고, 그렇지 않은 경우에는 근사값이 됩니다. Minitab에서는 검정이 적절한 경우 알려줍니다.
Lawley-Hotelling 검정
검정 통계량, Lawley-Hotelling 궤적은 다음과 같습니다.

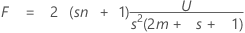
자유도가 s (2m + s + 1) 및 2 (sn + 1)임.
표기법
| 용어 | 설명 |
|---|---|
| H | 가설 행렬 |
| E | 오차 행렬 |
| p | 반응값의 수 |
| q | 가설의 자유도 |
| v | E의 자유도 |
| s | min (p, q) |
| m | .5 ( | p – q | – 1) |
| n | .5 (v – p – 1) |
| r | v – 0.5 (p – q + 1) |
| u | 0.25(pq – 2) |
| t | = Sqrt ([p2 q2 - 4] / p2 + q2 - 5, if p2 + q2 - 5 > 0 |
| t | 1 |
λ1≥λ2≥λ3≥ . . . ≥λp를 (E** - 1) * H의 고유값으로 설정합니다. 처음 세 검정 통계량은 H 및 E 또는 이러한 고유값으로 표현할 수 있습니다.
H 행렬은 대각선에 각 p 변수에 대한 "군간" 제곱합이 포함되는 p x p 행렬입니다. H 행렬은 다음과 같이 계산됩니다.

E 행렬은 대각선에 각 p 변수에 대한 "군내" 제곱합이 포함되는 p x p 행렬입니다. E 행렬은 다음과 같이 계산됩니다.
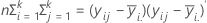
처음 세 검정에서 s = 1 또는 2이면 F 통계량이 정확하고, 그렇지 않은 경우에는 근사값이 됩니다. Minitab에서는 검정이 적절한 경우 알려줍니다.
Pillai의 검정
검정 통계량, Pillai의 궤적은 다음과 같습니다.

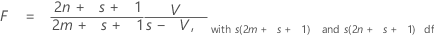
표기법
| 용어 | 설명 |
|---|---|
| H | 가설 행렬 |
| E | 오차 행렬 |
| p | 반응값의 수 |
| q | 가설의 자유도 |
| v | E의 자유도 |
| s | min (p, q) |
| m | .5 ( | p – q | – 1) |
| n | .5 (v – p – 1) |
| r | v – 0.5 (p – q + 1) |
| u | 0.25(pq – 2) |
| t | = Sqrt ([p2 q2 - 4] / p2 + q2 - 5, if p2 + q2 - 5 > 0 |
| t | 1 |
λ1≥λ2≥λ3≥ . . . ≥λp를 (E** - 1) * H의 고유값으로 설정합니다. 처음 세 검정 통계량은 H 및 E 또는 이러한 고유값으로 표현할 수 있습니다.
H 행렬은 대각선에 각 p 변수에 대한 "군간" 제곱합이 포함되는 p x p 행렬입니다. H 행렬은 다음과 같이 계산됩니다.

E 행렬은 대각선에 각 p 변수에 대한 "군내" 제곱합이 포함되는 p x p 행렬입니다. E 행렬은 다음과 같이 계산됩니다.
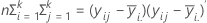
처음 세 검정에서 s = 1 또는 2이면 F 통계량이 정확하고, 그렇지 않은 경우에는 근사값이 됩니다. Minitab에서는 검정이 적절한 경우 알려줍니다.
Roy의 최대근 검정
가장 큰 고유값, λ1입니다. 검정을 완료하려면 Heck 관리도라고 하는 특수 관리도를 모수 s, m, n과 사용하여 유의 수준을 찾아야 합니다.
이 관리도에 대해서는 Heck1을 참조하십시오.
표기법
| 용어 | 설명 |
|---|---|
| s | min (p, q) |
| m | .5 ( | p – q | – 1) |
| n | .5 (v – p – 1) |
λ1≥λ2≥λ3≥ . . . ≥λp를 (E** - 1) * H의 고유값으로 설정합니다. 처음 세 검정 통계량은 H 및 E 또는 이러한 고유값으로 표현할 수 있습니다.
- D.L. Heck (1960), "Charts of Some Upper Percentage Points of the Distribution of the Largest Characteristic Root," The Annals of Statistics, 625–642.