평균
평균 표에는 하나 이상의 범주형 변수를 기반으로 그룹 내 관측치의 적합 평균이 표시됩니다. 적합 평균은 균형 설계의 평균 반응 값을 예측하기 위해 최소 제곱을 사용합니다.
해석
적합 평균은 다른 요인의 수준에 걸쳐 평균을 낸 상태에서 한 요인의 여러 수준에서의 평균 반응을 추정합니다.
평균 표를 사용하면 데이터의 요인 수준 간의 통계적으로 유의한 차이를 파악할 수 있습니다. 각 그룹의 평균은 각 모평균의 추정치를 제공합니다. 통계적으로 유의한 항에 대한 그룹 평균 간의 차이를 찾아보십시오.
주효과의 경우 표에는 각 요인 내 그룹 및 그룹의 평균이 표시됩니다. 교호작용 효과의 경우 표에는 그룹의 모든 가능한 조합이 표시됩니다. 교호작용 항이 통계적으로 유의하면 교호작용 효과를 고려하지 않고 주효과를 해석하지 마십시오.
이 결과에서 평균 표는 평균 유용성 및 품질 등급이 방법, 공장 및 방법*공장 교호작용에 따라 어떻게 달라지는지 보여줍니다. 방법 및 교호작용 항은 0.10 수준에서 통계적으로 유의합니다. 표는 방법 1과 방법 2가 각각 평균 유용성 등급 4.819 및 6.212와 연관되어 있다는 것을 보여줍니다. 이러한 평균 간의 차이는 품질 등급에 해당하는 평균 간의 차이보다 큽니다. 이는 고유 분석 해석을 확인합니다.
그러나 방법*공장 교호작용 항도 통계적으로 유의하므로 교호작용 효과를 고려하지 않고 주효과를 해석하지 마십시오. 예를 들어, 교호작용 항에 대한 표는 방법 1의 경우, 공장 C가 가장 높은 유용성 등급 및 가장 낮은 품질 등급과 연관된다는 것을 보여줍니다. 그러나 방법 2의 경우, 공장 A가 가장 높은 유용성 등급 및 가장 높은 품질 등급과 거의 같은 품질 등급과 연관되어 있습니다.
반응에 대한 최소 제곱 평균
| 유용성 등급 | 품질 등급 | |||
|---|---|---|---|---|
| 평균 | 평균의 표준 오차 | 평균 | 평균의 표준 오차 | |
| 방법 | ||||
| 방법 1 | 4.819 | 0.165 | 5.242 | 0.193 |
| 방법 2 | 6.212 | 0.179 | 6.026 | 0.211 |
| 공장 | ||||
| 공장 A | 5.708 | 0.192 | 5.833 | 0.226 |
| 공장 B | 5.493 | 0.232 | 5.914 | 0.273 |
| 공장 C | 5.345 | 0.206 | 5.155 | 0.242 |
| 방법*공장 | ||||
| 방법 1 공장 A | 4.667 | 0.272 | 5.417 | 0.319 |
| 방법 1 공장 B | 4.700 | 0.298 | 5.400 | 0.350 |
| 방법 1 공장 C | 5.091 | 0.284 | 4.909 | 0.334 |
| 방법 2 공장 A | 6.750 | 0.272 | 6.250 | 0.319 |
| 방법 2 공장 B | 6.286 | 0.356 | 6.429 | 0.418 |
| 방법 2 공장 C | 5.600 | 0.298 | 5.400 | 0.350 |
평균의 표준 오차
평균의 표준 오차(SE 평균)는 같은 모집단에서 표본을 반복 추출하는 경우 얻게 될 적합 평균 간의 변동성을 추정합니다.
예를 들어, 312개의 배송 시간 랜덤 표본에서 평균 배송 시간이 3.80일이고 표준 편차가 1.43일입니다. 이 숫자로 0.08일의 평균에 대한 표준 오차가 산출됩니다(1.43을 312 제곱근으로 나눈 값). 동일한 크기의 여러 랜덤 표본을 동일한 모집단에서 추출한 경우 서로 다른 표본 평균의 표준 편차는 약 0.08일이 됩니다.
해석
평균의 표준 오차를 사용하여 적합 평균이 모평균을 얼마나 정확하게 추정하는지 확인할 수 있습니다.
평균의 표준 오차 값이 작을수록 모집단 평균의 더 정확한 추정치를 나타냅니다. 일반적으로 표준 편차가 클수록 평균의 표준 오차가 더 크고 추정치가 덜 정확합니다. 표본 크기가 클수록 평균의 표준 오차가 더 작고 모집단 평균의 추정치가 더 정확하게 됩니다.
평균(공변량)
공변량 평균은 모든 관측치의 합을 관측치 수로 나눈 데이터의 평균입니다. 평균은 데이터 중심을 나타내는 단일 값을 사용하여 표본 값을 요약합니다.
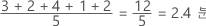
해석
데이터 중심을 나타내는 하나의 값으로 공변량을 설명하려면 평균을 사용하십시오.
표준 편차
표준 편차는 산포, 즉 데이터가 평균을 중심으로 퍼져 있는 정도를 나타내는 가장 일반적인 측도입니다. 모집단의 표준 편차를 나타내는 데는 일반적으로 기호 σ(시그마)가 사용됩니다. 표본의 표준 편차를 나타내는 데는 일반적으로 기호 s가 사용됩니다.
해석
- 값의 약 68%가 평균의 1 표준 편차 내에 포함됩니다.
- 값의 95%가 2 표준 편차 내에 포함됩니다.
- 값의 99.7%가 3 표준 편차 내에 포함됩니다.
그룹의 표본 표준 편차는 해당 그룹의 모집단 표준 편차의 추정치입니다. 표준 편차는 신뢰 구간과 p-값을 계산하기 위해 사용됩니다. 표본 표준 편차가 클수록 신뢰구간이 덜 정확하고(더 넓고) 통계적 검정력이 더 낮습니다.
분산 분석에서는 모든 수준에서의 모 표준 편차가 같다고 가정합니다. 등분산을 가정할수 없으면 Minitab Statistical Software에서 사용 가능한 일원 분산 분석 옵션인 Welch의 분산 분석을 사용하십시오.