완전 내포 분산 분석 모형
두 개의 변량 요인(A와 B)이 포함된 균형 설계에 대한 내포 분산 분석 모형은 다음과 같습니다.
yijk = μ .. + α i+ β j(i) +εijk
여기서 α i, β j(i) , ε ijk는 기대값이 0이고 분산이 각각 σ2α, σ2β, σ2인 독립 정규 랜덤 변수입니다.
모수는 다음과 같이 추정됩니다.
μ .. = y̅...
α i = yi..− y̅...
β j(i) = yij.− y̅i..
여기서 y̅... = 모든 관측치의 평균, yi.. = 요인 A의 i 수준에서 관측치의 평균, yij. = 요인 B의 j번째 수준 및 요인 A의 i번째 수준에서 관측치의 평균입니다. 모수 β j(i)는 A가 i번째 수준에 있을 때 B의 특정 효과입니다.
- J. Neter, W. Wasserman and M.H. Kutner (1985). Applied Linear Statistical Models. Second Edition. Irwin, Inc.
순차 제곱합
거리 제곱의 합입니다. SS 전체는 데이터의 총 변동입니다. SS (A)와 SS (B)는 추정된 요인 수준 평균의 전체 평균으로부터의 변동량이며, 요인 A 또는 요인 B에 대한 제곱합이라고도 합니다. SS 오차는 관측치의 적합치로부터의 변동량입니다. 다음과 같이 계산됩니다.
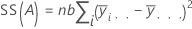
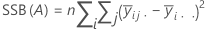



Minitab에서는 모형에 요인을 입력한 순서에 따라 달라지는 순차 제곱합을 제공합니다. 이전에 요인을 입력한 경우 SS 회귀 분석에서 한 요인만으로 설명되는 부분을 나타냅니다.
표기법
| 용어 | 설명 |
|---|---|
| a | 요인 A의 수준 수 |
| b | 요인 B의 수준 수 |
| n | 총 시행 횟수 |
| yi.. | 요인 A의 i번째 요인 수준의 평균 |
| y... | 모든 관측치의 전체 평균 |
| y.j. | 요인 B의 j번째 요인 수준의 평균 |
| yij. | 요인 A의 i번째 수준 및 요인 B의 j번째 수준에서 관측치의 평균 |
자유도(DF)
요인이 두 개인 완전 내포 분산 분석 모형의 자유도는 다음과 같습니다.


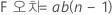
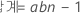
여기서 a = 요인 A의 수준 수, b = 요인 B의 수준 수, n은 시행 횟수입니다.
평균 제곱(MS)
공식

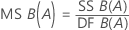

F
두 변량 요인이 포함된 모형의 F 통계량에 대한 공식은 다음과 같습니다.
공식
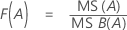

p-값 – 분산 분석표
p-값은 자유도(DF)가 다음과 같은 F 분포에서 계산되는 확률입니다.
- 분자 DF
- 검정의 항에 대한 자유도의 합
- 분모 DF
- 오차에 대한 자유도
공식
1 − P(F ≤ fj)
표기법
| 용어 | 설명 |
|---|---|
| P(F ≤ f) | F-분포의 누적분포함수 |
| f | 검정에 대한 f-통계량 |
분산 성분
변량 요인에 대해 계산됩니다. 두 변량 요인이 있는 내포 모형은 다음과 같습니다.
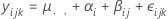
여기서 αi, βj(i), εijk는 독립 정규 랜덤 변수입니다. 이 변수들은 평균이 0이고 분산이 V(αi) = σ2α,V(βj) = σ2β, V(εijk) = σ2인 정규 분포를 따릅니다. 모든 bj(i)는 분산이 동일하다고 가정합니다. σ2β, σ2α, σ2β, σ2αβ, σ2는 분산 성분이라고 합니다.
기대 평균 제곱
두 변량 요인 A, B가 포함된 모형의 기대 평균 제곱은 다음과 같습니다.
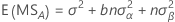


변량 요인이 포함된 모형에 대한 F-통계량
분산 분석 결과에서 F-통계량이 계산되는 방법
각 F-통계량은 평균 제곱의 비율입니다. 분자는 항에 대한 평균 제곱입니다. 분모는 분자 평균 제곱의 기대값이 분모 평균 제곱의 기대값과 중요한 효과만큼만 다르도록 선택됩니다. 랜덤 항에 대한 효과는 항의 분산 성분으로 표시됩니다. 고정된 항의 효과는 해당 항과 연관된 모형 성분의 제곱합을 자유도로 나눈 값으로 표시됩니다. 따라서 높은 F-통계량은 유의한 효과를 나타냅니다.
모형의 모든 항이 고정되어 있는 경우 각 F-통계량의 분모는 잔차의 평균 제곱(MSE)입니다. 그러나 랜덤 항을 포함하는 모형의 경우 MSE는 올바른 오차항이 아닐 수도 있습니다. 기대 평균 제곱(EMS)은 어느 항이 분모로 적절한지 확인하기 위해 사용할 수 있습니다.
예
| 출처 | 각 항에 대한 기대 평균 제곱 |
|---|---|
| (1) 화면 | (4) + 2.0000(3) + Q[1] |
| (2) 기술 | (4) + 2.0000(3) + 4.0000(2) |
| (3) 화면*기술 | (4) + 2.0000(3) |
| (4) 오차 | (4) |
괄호 안의 숫자는 출처 번호 옆에 나열된 항과 연관된 랜덤 효과를 나타냅니다. (2)는 '기술'의 랜덤 효과, (3)은 화면*기술 교호작용의 랜덤 효과, (4)는 '오차'의 랜덤 효과를 나타냅니다. '오차'에 대한 EMS는 오차항의 효과입니다. 또한 화면*기술에 대한 EMS는 오차항의 효과에 화면*기술 교호작용 효과의 두 배를 더한 것입니다.
화면*기술에 대한 F-통계량을 계산하기 위해 분자의 기대값(화면*기술에 대한 EMS = (4) + 2.0000(3))이 분모의 기대값(오차에 대한 EMS = (4))과 교호작용의 효과(2.0000(3))만큼만 다르도록 화면*기술에 대한 평균 제곱을 오차의 평균 제곱으로 나눕니다. 따라서 높은 F-통계량은 유의한 화면*기술 교호작용을 나타냅니다.
Q[ ] 안의 숫자는 출처 번호 옆에 나열된 항과 연관된 고정 효과를 나타냅니다. 예를 들어, Q[1]은 화면의 고정 효과입니다. 화면에 대한 EMS는 오차항 효과에 화면*기술 교호작용 효과의 두 배, 화면 효과의 상수 배를 더한 것입니다. Q[1]은 (b*n * sum((화면 수준에 대한 계수)**2))를 (a - 1)로 나눈 값입니다. 여기서 a와 b는 각각 화면과 기술의 수준 수이며 n은 반복실험의 수입니다.
화면에 대한 F-통계량을 계산하기 위해 분자의 기대값(화면에 대한 EMS = (4) + 2.0000(3) + Q[1])이 분모의 기대값(화면*기술에 대한 EMS = (4) + 2003(3))과 화면(Q[1])으로 인한 효과만큼만 다르도록 화면에 대한 평균 제곱을 화면*기술에 대한 평균 제곱으로 나눕니다. 따라서 높은 F-통계량은 유의한 화면 효과를 나타냅니다.
분산 분석 출력에서 분산 분석표의 p-값 옆에 "x" 및 "정확한 F-검정이 아님" 레이블이 표시되는 이유
항에 대한 정확한 F-검정은 분자 평균 제곱의 기대값이 분모 평균 제곱의 기대값과 분산 성분 또는 중요한 고정 요인만큼만 다른 검정입니다.
그러나 경우에 따라 이러한 평균 제곱을 계산할 수 없습니다. 이 경우 Minitab에서는 근사 F-검정을 생성하는 평균 제곱을 사용하고 F-검정이 정확하지 않다는 것을 나타내기 위해 p-값 옆에 "x"를 표시합니다.
| 출처 | 각 항에 대한 기대 평균 제곱 |
|---|---|
| (1) 첨가제 | (4) + 1.7500(3) + Q[1] |
| (2) 호수 | (4) + 1.7143(3) + 5.1429(2) |
| (3) 첨가제*호수 | (4) + 1.7500(3) |
| (4) 오차 | (4) |
첨가제에 대한 F-통계량은 첨가제에 대한 평균 제곱을 첨가제*호수 교호작용에 대한 평균 제곱으로 나눈 값입니다. 첨가제에 대한 효과가 아주 작으면 분자의 기대값이 분모의 기대값과 같습니다. 이것이 정확한 F-검정의 예입니다.
그러나 호수 효과가 아주 작은 경우에는 분자의 기대값이 분모의 기대값과 같게 되는 평균 제곱이 없습니다. 따라서 Minitab에서는 근사 F-검정을 사용합니다. 이 예에서는 호수에 대한 평균 제곱을 첨가제*호수에 대한 평균 제곱으로 나눕니다. 그 결과 호수 효과가 아주 작은 경우 분자의 기대값이 분모의 기대값과 거의 같게 됩니다.
"F-검정의 분모가 0이거나 정의되지 않았습니다" 메시지에 대한 정보.
- 오차에 대한 자유도가 1 이상이 아닙니다.
-
수정된 MS 값이 아주 작기 때문에 F-값과 p-값을 표시하기에 정밀도가 충분하지 않습니다. 해결 방법은 반응 열에 10을 곱하는 것입니다. 그런 다음 새 반응 열을 반응으로 사용하여 동일한 회귀 모형을 수행하십시오.
참고
반응 값에 10을 곱해도 Minitab에서 출력을 표시하는 F-값과 p-값은 영향을 받지 않습니다. 그러나 나머지 출력, 특히 순차 제곱합, 수정 SS, 수정 MS, 적합치, 적합치의 표준 오차 및 잔차 열의 경우 소숫점 위치는 영향을 받습니다.
분산 분석 결과에서 F-통계량이 계산되는 방법
각 F-통계량은 평균 제곱의 비율입니다. 분자는 항에 대한 평균 제곱입니다. 분모는 분자 평균 제곱의 기대값이 분모 평균 제곱의 기대값과 중요한 효과만큼만 다르도록 선택됩니다. 랜덤 항에 대한 효과는 항의 분산 성분으로 표시됩니다. 고정된 항의 효과는 해당 항과 연관된 모형 성분의 제곱합을 자유도로 나눈 값으로 표시됩니다. 따라서 높은 F-통계량은 유의한 효과를 나타냅니다.
모형의 모든 항이 고정되어 있는 경우 각 F-통계량의 분모는 잔차의 평균 제곱(MSE)입니다. 그러나 랜덤 항을 포함하는 모형의 경우 MSE는 올바른 오차항이 아닐 수도 있습니다. 기대 평균 제곱(EMS)은 어느 항이 분모로 적절한지 확인하기 위해 사용할 수 있습니다.
예
| 출처 | 각 항에 대한 기대 평균 제곱 |
|---|---|
| (1) 화면 | (4) + 2.0000(3) + Q[1] |
| (2) 기술 | (4) + 2.0000(3) + 4.0000(2) |
| (3) 화면*기술 | (4) + 2.0000(3) |
| (4) 오차 | (4) |
괄호 안의 숫자는 출처 번호 옆에 나열된 항과 연관된 랜덤 효과를 나타냅니다. (2)는 '기술'의 랜덤 효과, (3)은 화면*기술 교호작용의 랜덤 효과, (4)는 '오차'의 랜덤 효과를 나타냅니다. '오차'에 대한 EMS는 오차항의 효과입니다. 또한 화면*기술에 대한 EMS는 오차항의 효과에 화면*기술 교호작용 효과의 두 배를 더한 것입니다.
화면*기술에 대한 F-통계량을 계산하기 위해 분자의 기대값(화면*기술에 대한 EMS = (4) + 2.0000(3))이 분모의 기대값(오차에 대한 EMS = (4))과 교호작용의 효과(2.0000(3))만큼만 다르도록 화면*기술에 대한 평균 제곱을 오차의 평균 제곱으로 나눕니다. 따라서 높은 F-통계량은 유의한 화면*기술 교호작용을 나타냅니다.
Q[ ] 안의 숫자는 출처 번호 옆에 나열된 항과 연관된 고정 효과를 나타냅니다. 예를 들어, Q[1]은 화면의 고정 효과입니다. 화면에 대한 EMS는 오차항 효과에 화면*기술 교호작용 효과의 두 배, 화면 효과의 상수 배를 더한 것입니다. Q[1]은 (b*n * sum((화면 수준에 대한 계수)**2))를 (a - 1)로 나눈 값입니다. 여기서 a와 b는 각각 화면과 기술의 수준 수이며 n은 반복실험의 수입니다.
화면에 대한 F-통계량을 계산하기 위해 분자의 기대값(화면에 대한 EMS = (4) + 2.0000(3) + Q[1])이 분모의 기대값(화면*기술에 대한 EMS = (4) + 2003(3))과 화면(Q[1])으로 인한 효과만큼만 다르도록 화면에 대한 평균 제곱을 화면*기술에 대한 평균 제곱으로 나눕니다. 따라서 높은 F-통계량은 유의한 화면 효과를 나타냅니다.
분산 분석 출력에서 분산 분석표의 p-값 옆에 "x" 및 "정확한 F-검정이 아님" 레이블이 표시되는 이유
항에 대한 정확한 F-검정은 분자 평균 제곱의 기대값이 분모 평균 제곱의 기대값과 분산 성분 또는 중요한 고정 요인만큼만 다른 검정입니다.
그러나 경우에 따라 이러한 평균 제곱을 계산할 수 없습니다. 이 경우 Minitab에서는 근사 F-검정을 생성하는 평균 제곱을 사용하고 F-검정이 정확하지 않다는 것을 나타내기 위해 p-값 옆에 "x"를 표시합니다.
| 출처 | 각 항에 대한 기대 평균 제곱 |
|---|---|
| (1) 첨가제 | (4) + 1.7500(3) + Q[1] |
| (2) 호수 | (4) + 1.7143(3) + 5.1429(2) |
| (3) 첨가제*호수 | (4) + 1.7500(3) |
| (4) 오차 | (4) |
첨가제에 대한 F-통계량은 첨가제에 대한 평균 제곱을 첨가제*호수 교호작용에 대한 평균 제곱으로 나눈 값입니다. 첨가제에 대한 효과가 아주 작으면 분자의 기대값이 분모의 기대값과 같습니다. 이것이 정확한 F-검정의 예입니다.
그러나 호수 효과가 아주 작은 경우에는 분자의 기대값이 분모의 기대값과 같게 되는 평균 제곱이 없습니다. 따라서 Minitab에서는 근사 F-검정을 사용합니다. 이 예에서는 호수에 대한 평균 제곱을 첨가제*호수에 대한 평균 제곱으로 나눕니다. 그 결과 호수 효과가 아주 작은 경우 분자의 기대값이 분모의 기대값과 거의 같게 됩니다.
"F-검정의 분모가 0이거나 정의되지 않았습니다" 메시지에 대한 정보.
- 오차에 대한 자유도가 1 이상이 아닙니다.
-
수정된 MS 값이 아주 작기 때문에 F-값과 p-값을 표시하기에 정밀도가 충분하지 않습니다. 해결 방법은 반응 열에 10을 곱하는 것입니다. 그런 다음 새 반응 열을 반응으로 사용하여 동일한 회귀 모형을 수행하십시오.
참고
반응 값에 10을 곱해도 Minitab에서 출력을 표시하는 F-값과 p-값은 영향을 받지 않습니다. 그러나 나머지 출력, 특히 순차 제곱합, 수정 SS, 수정 MS, 적합치, 적합치의 표준 오차 및 잔차 열의 경우 소숫점 위치는 영향을 받습니다.