GLM 모형
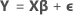
표기법
| 용어 | 설명 |
|---|---|
| Y | 반응값의 벡터 |
| X | 설계 행렬 |
| β | 모수의 벡터 |
| ε | 독립 정규 랜덤 변수의 벡터 |
설계 행렬
일반 선형 모형에서는 회귀 분석 방법을 사용하여 사용자가 지정한 모형을 적합시킵니다. Minitab에서는 먼저 요인과 공변량으로 설계 행렬을 만들고 사용자가 지정한 모형을 만듭니다. 이 행렬의 열은 회귀 분석을 위한 예측 변수가 됩니다.
설계 행렬에는 n개의 행(여기서 n = 관측치 수)과 모형의 항에 해당하는 여러 개의 열 블럭이 있습니다. 첫 번째 블럭은 상수 블럭이며 모두 1로 구성된 열 하나만을 포함하고 있습니다. 공변량 블럭에도 공변량 열 자체를 나타내는 하나의 열이 있습니다. 요인에 대한 열 블럭은 r개의 열(여기서 r = 요인에 대한 자유도)을 포함하며 다음 예에 표시된 것과 같이 코드화됩니다.
요인 A에 4개의 수준이 있다고 가정합니다. 이 경우 자유도는 3이고 이 블럭에는 A1, A2, A3이라는 3개의 열이 포함됩니다.
| A 수준 | A1 | A2 | A3 |
|---|---|---|---|
| 1 | 1 | 0 | 0 |
| 2 | 0 | 1 | 0 |
| 3 | 0 | 0 | 1 |
| 4 | –1 | –1 | –1 |
요인 B는 수준이 3개이며 요인 A의 각 수준 내에 내포된다고 가정합니다. 그러면 이 블럭에는 (3 - 1) x 4 = 8개의 열(B11, B12, B21, B22, B31, B32, B41, B42)이 포함되며 이 블럭은 다음과 같이 코드화됩니다.
| A 수준 | B 수준 | B11 | B12 | B21 | B22 | B31 | B32 | B41 | B42 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 2 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 3 | –1 | –1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 2 | 2 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 2 | 3 | 0 | 0 | –1 | –1 | 0 | 0 | 0 | 0 |
| 3 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 3 | 2 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 3 | 3 | 0 | 0 | 0 | 0 | –1 | –1 | 0 | 0 |
| 4 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 4 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 4 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | –1 | –1 |
교호작용 항에 대한 열을 계산하려면 교호작용의 요인 및/또는 공변량에 대한 모든 해당 열을 곱하면 됩니다. 예를 들어, 요인 A의 수준이 6개이고, 요인 C의 수준이 3개이고, 요인 D의 수준이 4개이며, 요인 Z와 W가 공변량이라고 가정합니다. 이 경우 A * C * D * Z * W * W 항에는 5 x 2 x 3 x 1 x 1 x 1 = 30개의 열이 있습니다. 이러한 더미 변수를 구하려면 A의 각 열과 C의 각 열, D의 각 열을 곱하고, 공변량 Z를 한 번, 공변량 W를 두 번 곱하면 됩니다.
Box-Cox 변환
Box-Cox 변환은 아래와 같이 잔차 제곱합을 최소화하는 람다 값을 선택합니다. 결과 변환은 λ ≠ 0일 때 Y λ, λ = 0일 때 ln(Y)입니다. λ < 0인 경우 Minitab에서는 변환되지 않은 반응의 순서를 유지하기 위해 변환된 반응에 −1을 곱합니다.
Minitab은 -2와 2 사이의 최적 값을 검색합니다. 이 구간을 벗어나는 값의 결과는 더 적합하지 않을 수 있습니다.
Y'가 데이터 Y의 변환인 일반적인 변환의 몇 가지 예는 다음과 같습니다.
| 람다(λ) 값 | 변환 |
|---|---|
| λ = 2 | Y′ = Y 2 |
| λ = 0.5 | Y′ = |
| λ = 0 | Y′ = ln(Y ) |
| λ = −0.5 | |
| λ = −1 | Y′ = −1 / Y |
가중 회귀 분석
가중 최소 제곱법은 분산이 일정하지 않은 관측치를 처리하기 위한 방법입니다. 분산이 일정하지 않으면 관측치는 다음과 같은 경우 중 하나로 처리됩니다.
- 큰 분산에는 상대적으로 작은 가중치를 부여해야 합니다.
- 작은 분산에는 상대적으로 큰 가중치를 부여해야 합니다.
일반적으로 반응의 순수 오차 변동의 역이 가중치로 선택됩니다.
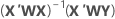
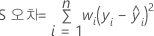
표기법
| 용어 | 설명 |
|---|---|
| X | 설계 행렬 |
| X' | 설계 행렬의 전치 |
| W | 대각선에 가중치가 있는 n x n 행렬 |
| Y | 반응 값의 벡터 |
| n | 관측치 수 |
| wi | i번째 관측치에 대한 가중치 |
| yi | i번째 관측치에 대한 반응 값 |
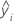 | i번째 관측치에 대한 적합치 |
Minitab이 일반 선형 모형 적합의 회귀 방정식에서 높은 상관 관계가 있는 예측 변수를 제거하는 방법
- Minitab에서 X-행렬에 대해 QR 분해를 수행합니다.
참고
QR 분해를 사용하여 R2을 계산하는 것이 최소제곱법을 사용하는 것보다 빠릅니다.
- Minitab에서 하나의 예측 변수를 다른 모든 예측 변수에 대해 회귀 분석하고 R2 값을 계산합니다. 1 – R2 < 4 * 2.22e-16인 경우 예측 변수는 검정을 통과하지 못하며 모형에서 제거됩니다.
- Minitab에서 나머지 예측 변수에 대해 1, 2단계를 반복합니다.
예
- Minitab에서 X5를 X1-X4에 대해 회귀 분석합니다. 1 – R2이 4 * 2.22e-16보다 크면 X5가 방정식에 남아 있게 됩니다. X5는 검정을 통과하고 방정식에 남아 있습니다.
- Minitab에서 X1, X2, X3, X5에 대해 X4를 회귀 분석합니다. 이 회귀 분석에 대한 1 – R2이 4 * 2.22e-16보다 크고 방정식에 남아 있다고 가정합니다.
- Minitab에서 X1, X2, X4, X5에 대해 X3을 회귀 분석하고 R2 값을 계산합니다. X3은 검정을 통과하지 못하며 방정식에서 제거됩니다.
- Minitab에서 X-행렬에 대해 새로운 QR 분해를 수행하고 나머지 예측 변수 X1, X4, X5에 대해 X2를 회귀 분석합니다. X2는 검정을 통과합니다.
- Minitab에서 X2, X4, X5에 대해 X1을 회귀 분석합니다. X1은 검정을 통과하지 못하며 방정식에서 제거됩니다.
Minitab에서 X2, X4, X5에 대해 Y를 회귀 분석합니다. 예측 변수 X1 및 X3을 추정할 수 없으며 모형에서 제거되었다는 메시지가 표시됩니다.
참고
TOLERANCE 하위 명령을 GLM 세션 명령과 함께 사용하여 Minitab에서 다른 예측 변수와 높은 상관 관계가 있는 예측 변수를 모형에 유지하도록 할 수 있습니다. 그러나 공차를 낮추는 것은 위험하며 숫자가 부정확해질 수 있습니다.