방법
평균 분석은 개별 요인 수준 평균이 총 평균(한 요인의 모든 관측치의 평균)과 다른지 여부를 확인하기 위한 절차입니다. Minitab에서 일원 모형에 대한 평균 분석 결과를 계산하기 위해 사용하는 단계가 아래에 나열되어 있습니다.
- 각 요인 수준에서 평균, y̅i. (i = 1, …, r)를 계산합니다.
- 모든 관측치의 총 평균, y를 계산합니다...
- 관측치 표준 편차의 추정치 sp를 계산합니다.
- 검정을 위해 선택된 유의 수준에 해당하는 값이고 상위 및 하위 결정 선에 사용되는 hα 값을 결정합니다.
- 상위 및 하위 결정 한계(UDL 및 LDL)를 계산합니다.
- 각 요인 수준의 평균을 상위 및 하위 기준선 및 총 평균의 중심선과 함께 표시합니다.
평균
공식
각 요인 수준에서 관측치의 평균입니다. Minitab에서는 각 요인 수준에 대한 평균을 그래프에 표시합니다.
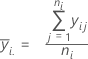
표기법
| 용어 | 설명 |
|---|---|
| ni | 요인 수준 i에서의 관측치 수 |
| yij | i번째 요인 수준에서 j번째 관측치의 값 |
총 평균(중심선)
공식
전체 요인 수준에 걸친 모든 관측치의 평균입니다. Minitab에서는 총 평균을 그래프의 중심선으로 사용합니다.
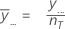
표기법
| 용어 | 설명 |
|---|---|
| y... | 표본 내 모든 관측치의 합 |
| nT | 총 관측치 수 |
표준 편차
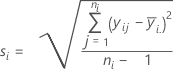
표기법
| 용어 | 설명 |
|---|---|
| yij | i번째 요인 수준에서의 관측치 |
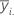 | i번째 요인 수준에서 관측치의 평균 |
| ni | i번째 요인 수준에서의 관측치 수 |
합동 표준 편차
모든 요인 수준에 걸친 변동의 추정치입니다. 합동 표준 편차는 결정 한계를 계산하기 위해 사용됩니다.
공식
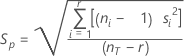
표기법
| 용어 | 설명 |
|---|---|
| r | 수준 수 |
| nT | 총 관측치 수 |
상위 및 하위 결정 한계
결정 한계는 요인 수준 평균이 총 평균과 다른지 여부를 나타냅니다. 상위 결정 한계(UDL) 또는 하위 결정 한계(LDL)를 벗어나 있는 점은 총 평균과 통계적으로 다릅니다.
상위 및 하위 결정 한계는 요인의 수준 수 및 각 수준에서의 관측치 수에 따라 다르게 계산됩니다.
각 수준에서의 관측치 수가 같은 2-수준 요인
- UDL = y.. + hα sp* Sqrt(1/ nT)
- LDL = y.. - hα sp* Sqrt(1/ nT)
여기서 hα = 절대값(t(a / 2, nT - 2)), sp = 합동 표준 편차, nT = 총 관측치 수입니다.
각 수준에서의 관측치 수가 같은 수준이 3개 이상인 요인
- UDL = y.. + hα sp* Sqrt[(r-1) / (rn1)]
- LDL = y.. - hα sp* Sqrt[(r-1) / (rn1)]
여기서 r = 요인의 수준 수, n1 = 각 수준에서의 관측치 수입니다.
자유도는 (n1- 1) * r입니다.
0.001과 0.1의 범위를 벗어나는 알파 값의 경우, 결정 한계는 다음과 같습니다.
- UDL = y.. + hα sp* Sqrt[(nT - n1) / (nT* n1)]
- LDL = y.. - hα sp* Sqrt[(nT - n1) / (nT* n1)]
여기서 hα = 절대값(t(α2, df)), α2 = (1- (1- a )** (1 / r)) / 2, df = nT - r입니다.
0.001과 0.1 사이의 α 값에 대한 hα를 얻으려면 Nelson1을 참조하십시오.
각 수준에서의 관측치 수가 같지 않은 수준이 3개 이상인 요인
- UDLi = y.. + hα sp* Sqrt[(nT - ni) / (nT* ni)]
- LDLi = y.. - hα sp* Sqrt[(nT - ni) / (nT* ni)]
- L.S. Nelson (1983). "Exact Critical Values for Use with the Analysis of Means", Journal of Quality Technology, 15, 40-44.