1단계: 정규 분포의 적합도 보기
원래 데이터와 변환된 데이터가 얼마나 가깝게 정규 분포를 따르는지 평가하려면 정규 확률도를 사용합니다.
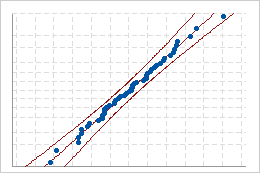
좋은 적합치
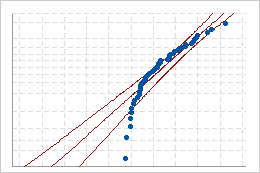
좋지 않은 적합치
참고
원래 데이터가 정규 분포를 따르는 경우 Minitab에서는 단일 확률도만 표시하며 Johnson 변환을 수행하지 않습니다.
2단계: 정규 분포의 적합도 평가
원래 데이터와 변환된 데이터가 정규 분포를 따른다고 가정할 수 있는지 여부를 평가하려면 p-값을 사용합니다.
- 알파보다 작은 p-값은 정규 분포가 적합하지 않다는 것을 나타냅니다.
- 알파보다 크거나 같은 p-값은 분포가 적합하지 않다는 충분한 증거가 없음을 나타냅니다. 데이터가 정규 분포를 따른다고 가정할 수 있습니다.
Johnson 변환이 효과적인 경우 변환된 데이터에 대한 p-값이 알파보다 큽니다.
중요
매우 작거나 매우 큰 표본으로부터의 결과를 해석하는 경우 주의하십시오. 표본이 너무 작으면 적합도 검정이 분포에서 유의한 편차를 탐지하기 위한 검정력이 충분하지 않을 수도 있습니다. 표본이 너무 크면 검정의 검정력이 매우 커서 분포에서 실제적으로 유의하지 않은 작은 편차도 탐지할 수도 있습니다. 분포 적합도를 평가하려면 p-값 외에 확률도를 사용하십시오.
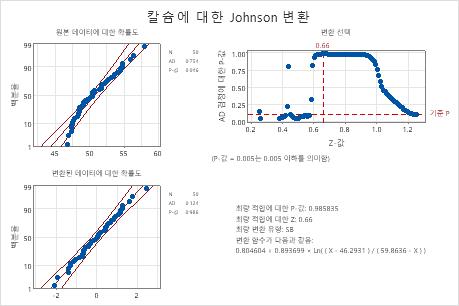
주요 결과: p-값
이 결과에서는 원래 데이터에 대한 p-값(0.046)이 알파(0.10)보다 작아 원래 칼슘 데이터가 정규 분포를 따르지 않는다는 것을 나타냅니다. 변환된 데이터의 경우 p-값(0.986)이 알파보다 큽니다. 따라서 변환된 데이터가 정규 분포를 따른다고 가정할 수 있습니다.
3단계: 변환 함수 조사
Minitab에서는 최량 적합치를 생성하는 Johnson 변환 함수의 모수를 표시합니다. Minitab에서는 이 함수를 사용하여 원래 데이터를 변환합니다.
예를 들어, Johnson 변환 함수가 0.762475 + 0.870902 × Ln((X – 46.3174 ) / (59.677 – X))라고 가정합니다. X에 대한 원래 데이터 값이 50인 경우 변환된 데이터 값 50은 0.762475 + 0.870902 × Ln((50 – 46.3174) / (59.677 – 50))으로 계산되며, 계산 결과는 –0.07893입니다.
참고
변환된 모든 데이터 값을 워크시트에 저장하려면 분석을 수행할 때 저장 열을 입력합니다.
Minitab에서 Johnson 변환 기능을 정의하기 위해 사용하는 알고리즘에 대한 자세한 내용을 보려면 개별 분포 식별의 변환에 대한 방법 및 공식에서 "Johnson 변환에 대한 방법 및 공식"을 참조하십시오.