한 영양 보충제 회사의 품질 엔지니어가 비타민 캡슐의 칼슘 함유량을 평가하려고 합니다. 엔지니어는 캡슐의 랜덤 표본을 수집하여 칼슘 함유량을 기록합니다. 과거의 경험으로부터 엔지니어는 데이터가 오른쪽으로 치우쳐 있다는 것을 알고 있습니다.
엔지니어는 Johnson 변환을 수행하여 데이터를 정규 분포를 따르도록 변환하고 변환된 값을 추가 분석을 위해 워크시트에 저장합니다.
- 표본 데이터칼슘함유량.MWX을(를) 엽니다.
- 을 선택합니다.
- 데이터 배열 형식에서 단일 열을 선택한 다음 칼슘을 입력합니다.
- 변환 데이터 저장 위치 아래 단일 열에 C2를 입력합니다.
- 확인을 클릭합니다.
결과 해석
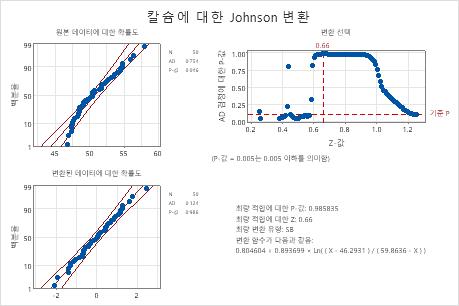
Minitab에서는 원래 데이터와 변환 데이터에 대한 정규 확률도와 p-값을 표시합니다. 데이터가 정규 분포를 따르는 경우에는 확률도의 점들이 거의 직선을 따르며 p-값이 알파 수준보다 큽니다. 분포 적합성을 확인하기 위해 보통 0.05 또는 0.10의 알파 수준이 사용됩니다.
원래 데이터의 경우, 확률도의 데이터 점들이 직선을 따르지 않으며 p-값(0.046)이 알파보다 작아, 원래 칼슘 데이터가 정규 분포를 따르지 않는다는 것을 나타냅니다. 변환 데이터의 경우, 확률도의 데이터 점들이 직선을 따르며 p-값(0.986)이 알파보다 큽니다. 따라서 변환된 칼슘 데이터가 정규 분포를 따른다고 가정할 수 있습니다.