N
표본에 있는 비결측값의 개수입니다. N은 모든 관측치의 수입니다.
| 합계 | N | N* |
|---|---|---|
| 149 | 141 | 8 |
해석
표본 크기를 평가하려면 N을 사용합니다.
중요
매우 작거나 매우 큰 표본으로부터의 결과를 해석하는 경우 주의하십시오. 표본이 너무 작으면 적합도 검정이 분포에서 유의한 편차를 탐지하기 위한 검정력이 충분하지 않을 수도 있습니다. 표본이 너무 크면 검정의 검정력이 매우 커서 분포에서 실제적으로 유의하지 않은 작은 편차도 탐지할 수도 있습니다. 분포 적합도를 평가하려면 p-값 외에 확률도를 사용하십시오.
N*
표본에 있는 결측값의 개수입니다. N*은 워크시트에서 결측값 기호 *가 포함된 셀의 수입니다.
| 합계 | N | N* |
|---|---|---|
| 149 | 141 | 8 |
평균
평균은 모든 관측치의 합을 관측치 수로 나눈, 데이터의 평균으로 계산됩니다.
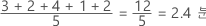
해석
데이터 중심을 나타내는 하나의 값으로 표본을 설명하려면 평균을 사용하십시오. 많은 통계 분석에서 평균을 표준 기준점으로 사용합니다.
대칭 분포의 경우 평균과 중위수
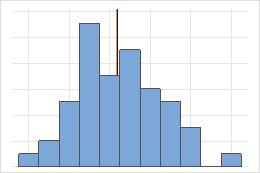
비대칭 분포의 평균과 중위수
대칭 분포의 경우 평균(파란색 선)과 중위수(주황색 선)가 거의 같습니다. 따라서 선들이 겹치고 서로 구별할 수 없습니다. 비대칭 분포의 경우, 데이터가 오른쪽으로 치우쳐 평균 값이 중위수보다 크게 됩니다.
표준 편차
표준 편차는 산포, 즉 데이터가 평균을 중심으로 퍼져 있는 정도를 나타내는 가장 일반적인 측도입니다. 모집단의 표준 편차를 나타내는 데는 σ(시그마) 기호를 자주 사용하고, 표본의 표준 편차를 사용하는 데는 s를 사용합니다.
해석
데이터가 평균을 중심으로 퍼져 있는 정도를 확인하려면 표준 편차를 사용하십시오. 표본 표준 편차가 클수록 데이터가 평균 주위로 더 넓게 퍼져 있다는 것을 나타냅니다.
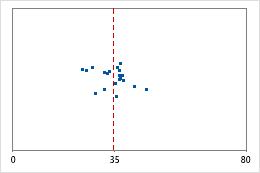
병원 1
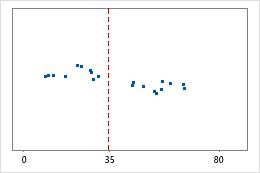
병원 2
병원 퇴원 시간
관리자들이 두 개 병원의 응급실 부서에서 치료한 환자의 퇴원 시간을 추적하고자 합니다. 평균 퇴원 시간은 동일하지만(35분) 표준 편차는 유의하게 다릅니다. 병원 1의 표준 편차는 약 6이며, 평균적으로 환자의 퇴원 시간은 평균(대시선)에서 약 6분 정도 멀어집니다. 병원 2의 표준 편차는 약 20이며, 평균적으로 환자의 퇴원 시간은 평균(대시선)에서 약 20분 정도 멀어집니다.
중위수
중위수는 데이터 집합의 중간점입니다. 중간점 값은 관측치의 반이 이 값보다 크고 관측치의 반이 이 값보다 작은 점입니다. 중위수는 관측치 순위를 매기고 순위가 [N + 1] / 2인 관측치를 찾는 방법으로 결정됩니다. 관측치의 수가 짝수이면 중위수는 순위가 N / 2과 [N / 2] + 1인 관측치 사이의 값입니다.
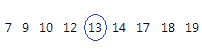
이 순서 데이터의 경우 중위수는 13입니다. 즉, 값의 반은 13보다 작거나 같고, 값의 반은 13보다 크거나 같습니다.
해석
대칭 분포의 경우 평균과 중위수
비대칭 분포의 경우 평균과 중위수
대칭 분포의 경우 평균(파란색 선)과 중위수(주황색 선)가 거의 같습니다. 따라서 선들이 겹치고 서로 구별할 수 없습니다. 비대칭 분포의 경우 데이터가 오른쪽으로 치우쳐 평균 값이 중위수보다 크게 됩니다.
최소값
가장 작은 데이터 값.
이 데이터에서 최소값은 7입니다.
| 13 | 17 | 18 | 19 | 12 | 10 | 7 | 9 | 14 |
해석
가능한 특이치를 식별하려면 최소값을 사용합니다. 값이 비정상적으로 작으면 데이터 입력 오류나 측정 오차 등 가능한 원인을 조사하십시오.
데이터 산포를 평가하는 가장 간단한 방법은 최소값과 최대값을 비교하여 범위를 결정하는 것입니다. 범위는 데이터 집합의 최대값과 최소값의 차이입니다. 데이터 산포를 평가할 때는 표준 편차와 같은 다른 측도도 고려하십시오.
최대값
가장 큰 데이터 값.
이 데이터에서 최대값은 19입니다.
| 13 | 17 | 18 | 19 | 12 | 10 | 7 | 9 | 14 |
해석
가능한 특이치를 식별하려면 최대값을 사용합니다. 값이 비정상적으로 크면 데이터 입력 오류나 측정 오차 등 가능한 원인을 조사하십시오.
데이터의 산포를 평가하는 가장 간단한 방법은 최소값과 최대값을 비교하여 범위를 결정하는 것입니다. 범위는 데이터 집합의 최대값과 최소값의 차이입니다. 데이터의 산포를 평가할 때는 표준 편차와 같은 다른 측도도 고려하십시오.
왜도
왜도는 데이터가 대칭이 아닌 정도입니다.
해석
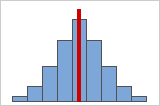
그림 A: 대칭이고 정규 분포를 따르는 데이터
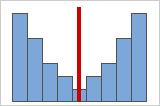
그림 B: 대칭이고 정규 분포를 따르지 않는 데이터
대칭 분포 또는 치우치지 않은 분포
데이터가 대칭에 가까울수록 왜도값이 0에 가까워집니다. 그림 A는 정의상 왜도가 없는, 정규 분포를 따르는 데이터를 보여줍니다. 정규 데이터의 히스토그램 가운데에 있는 선은 양면이 서로 거울에 비친 이미지라는 것을 보여줍니다. 그러나 왜도 부족만으로 정규성을 의미하지 않습니다. 그림 B는 분포의 양면이 서로 거울에 비추는 이미지이지만 데이터가 정규 분포를 따르지 않는다는 것을 보여줍니다.
양의 방향 또는 오른쪽으로 치우친 분포
양의 방향으로 치우친 데이터는 분포의 "꼬리"가 오른쪽을 가리키기 때문에 오른쪽으로 치우친 데이터라고도 합니다. 양의 방향으로 치우친 데이터는 왜도 값이 0보다 큽니다. 급여 데이터는 보통 양의 방향으로 치우칩니다. 회사 내 많은 직원의 급여가 상대적으로 적은 반면 점점 더 적은 사람들이 매우 많은 급여를 받습니다.
음의 방향 또는 왼쪽으로 치우친 분포
음의 방향으로 치우친 데이터는 분포의 "꼬리"가 왼쪽을 가리키기 때문에 왼쪽으로 치우친 데이터라고도 합니다. 음의 방향으로 치우친 데이터는 왜도 값이 0보다 작습니다. 고장률 데이터는 보통 음의 방향으로 치우칩니다. 예를 들어, 즉시 연소되는 전구는 거의 없고 대부분의 전구는 오랫동안 연소되지 않습니다.
첨도
첨도는 분포의 꼬리가 정규 분포와 어떻게 다른지 나타냅니다.
해석
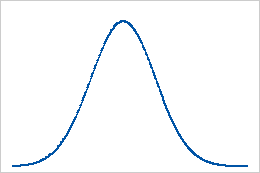
기준선: 0의 첨도 값
완전히 정규 분포를 따르는 데이터의 첨도 값은 0입니다 정규 분포를 따르는 데이터가 첨도의 기준선을 설정합니다. 첨도가 0으로부터 유의하게 벗어나면 데이터가 정규 분포를 따르지 않는다는 것을 나타냅니다.
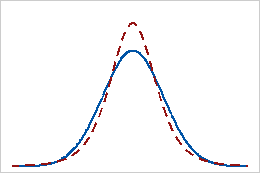
양의 첨도
분포의 첨도 값이 양수이면 분포의 꼬리가 정규 분포보다 두껍다는 것을 나타냅니다. 예를 들어, t-분포를 따르는 데이터의 첨도 값은 양수입니다. 실선은 정규 분포, 점선은 첨도 값이 양수인 t-분포를 보여줍니다.
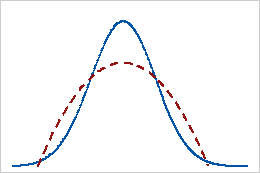
음의 첨도
분포의 첨도 값이 음수이면 분포의 꼬리가 정규 분포보다 얇다는 것을 나타냅니다. 예를 들어, 첫 번째와 두 번째 형상 모수가 2인 베타 분포를 따르는 데이터의 첨도 값은 음수입니다. 실선은 정규 분포, 점선은 첨도 값이 음수인 베타 분포를 보여줍니다.