이 항목의 내용
Cohen의 카파 통계량(표준을 알 수 없는 경우)
- 평가자 내 - 평가자당 시행 횟수가 정확히 두 번입니다.
- 평가자 간 - 시행 횟수가 한 번뿐인 평가자가 정확히 두 명 있습니다.
특정 반응 값에 대해 반응 값과 같지 않은 모든 반응을 하나의 범주로 축약하여 카파를 계산할 수 있습니다. 그런 다음, 2X2 표를 사용하여 카파를 계산할 수 있습니다.
공식
실제 표준이 알려져 있지 않은 경우 Minitab에서는 다음 공식을 사용하여 Cohen의 카파를 추정합니다.

| 시행 B(또는 평가자 B) | |||||
| 시행 A(또는 평가자 A) | 1 | 2 | ... | k | 합계 |
| 1 | p11 | p12 | ... | p1k | p1+ |
| 2 | p21 | p22 | ... | p2k | P2+ |
| .... | |||||
| k | pk1 | pk2 | ... | pkk | pk+. |
| 합계 | p.+1 | p.+2 | ... | p.+k | 1 |
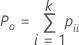
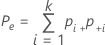
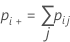
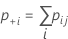

표기법
| 용어 | 설명 |
|---|---|
| Po | 합치도의 관측 비율 |
| pii | 이원 표의 대각선에 있는 각 값 |
| Pe | k명의 평가자가 일치하는 횟수의 기대 비율 |
| nij | i번째 행과 j번째 열의 표본 개수 |
| N | 총 표본 개수 |
Cohen의 카파 통계량(표준을 알고 있는 경우)
분류가 명목형인 경우 Cohen의 카파 통계량을 사용하십시오. 표준을 알고 있고 Cohen의 카파를 사용하기로 한 경우 Minitab에서는 아래 공식을 사용하여 통계량을 계산합니다.
알려진 표준을 사용한 시행의 합치도에 대한 카파 계수는 이러한 카파 계수의 평균입니다.
공식
실제 표준을 알고 있는 경우, 먼저 각 시행의 데이터 및 알려진 표준을 사용하여 카파를 계산합니다.

| 표준 | |||||
| 시행 A | 1 | 2 | ... | k | 합계 |
| 1 | p11 | p12 | ... | p1k | p1+ |
| 2 | p21 | p22 | ... | p2k | P2+ |
| .... | |||||
| k | pk1 | pk2 | ... | pkk | pk+. |
| 합계 | p.+1 | p.+2 | ... | p.+k | 1 |
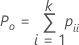
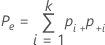
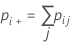
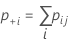

표기법
| 용어 | 설명 |
|---|---|
| Po | 합치도의 관측 비율 |
| pii | 이원 표의 대각선에 있는 각 값 |
| Pe | k명의 평가자가 일치하는 횟수의 기대 비율 |
| nij | i번째 행과 j번째 열의 표본 개수 |
| N | 총 표본 개수 |
Cohen의 카파의 유의성 검정
등급이 독립적(카파 = 0)이라는 귀무 가설을 검정하려면 다음 공식을 사용하십시오.
z = 카파 / 카파의 SE
이 검정은 단측 검정입니다. 귀무 가설 하에서 z는 표준 정규 분포를 따릅니다. z가 α 임계값보다 유의하게 크면 가설을 기각합니다.
공식
각 시행 및 표준에 대한 카파의 표준 오차는 다음과 같습니다.
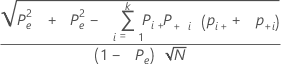
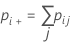
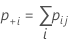
표기법
| 용어 | 설명 |
|---|---|
| Pe | k명의 평가자가 일치하는 횟수의 기대 비율 |
| N | 총 표본 개수 |
Fleiss의 카파 통계량(표준을 알 수 없는 경우)
- 경우 1 - 각 평가자 내 합치도
- 각 평가자 내 합치도를 나타내는 카파 통계량을 계산합니다.
- 경우 2 - 모든 평가자 간 합치도
- 모든 평가자 간 합치도를 나타내는 카파 계수를 계산합니다.
전체 카파를 위한 공식
xij를 범주 j 내 표본 i에 대한 등급 수로 정의합니다. 여기서 i는 1부터 - n까지, j는 1부터 k까지입니다.
전체 카파 계수는 다음 공식에 의해 정의됩니다.
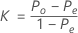
설명:
Po는 m번의 시행 간 쌍별 합치도의 관측 비율입니다.
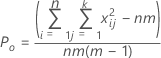
Pe는 각 시행에서 평가된 등급이 서로 독립적인 경우 기대 합치도 비율입니다.
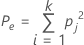
pj는 범주 j 내 등급의 전체 비율을 나타냅니다.
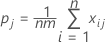
Po 및 Pe를 K로 대체하면 전체 카파 계수는 다음 공식에 의해 추정됩니다.
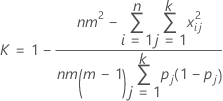
| 용어 | 설명 |
|---|---|
| k | 총 범주 수 |
| m | 시행 횟수. 경우 1에서 m = 각 평가자에 대한 시행 횟수이고, 경우 2에서 m = 모든 평가자에 대한 시행 횟수입니다. |
| n | 표본 개수 |
| xij | 범주 j 내 i 표본에 대한 등급의 수 |
단일 범주의 카파에 대한 공식
k개 범주 중 단일 범주, 예를 들어 j번째 범주로 분류와 관련된 합치도를 측정하기 위해 현재 관심의 대상이 되는 범주를 제외한 모든 범주를 단일 범주로 결합한 후 위의 방정식을 적용할 수 있습니다. 그 결과 j번째 범주의 카파 통계량에 대한 공식은 다음과 같습니다.
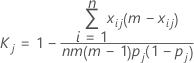
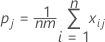
설명:
| 용어 | 설명 |
|---|---|
| k | 총 범주 수 |
| m | 시행 횟수. 경우 1에서 m = 각 평가자에 대한 시행 횟수이고, 경우 2에서 m = 모든 평가자에 대한 시행 횟수입니다. |
| n | 표본 개수 |
| xij | 범주 j 내 i 표본에 대한 등급의 수 |
Fleiss의 카파의 유의성 검정(표준을 알 수 없는 경우)
귀무 가설, H0: 카파 = 0. 대립 가설, H1: 카파 > 0.
귀무 가설 하에서 Z는 근사적으로 정규 분포를 따르며 p-값을 계산하는 데 사용됩니다.
공식
카파 > 0인지 여부를 검정하려면 다음 Z 통계량을 사용하십시오.

Var (K)는 다음 공식에 의해 계산됩니다.
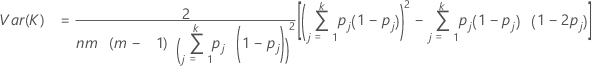
j번째 범주에 대해 카파 > 0인지 여부를 검정하려면 다음 Z 통계량을 사용하십시오.

Var (Kj)는 다음 공식에 의해 계산됩니다.

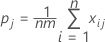
표기법
| 용어 | 설명 |
|---|---|
| K | 전체 카파 통계량 |
| Kj | j번째 범주에 대한 카파 통계량 |
| k | 총 범주 수 |
| m | 시행 횟수. 경우 1에서 m = 각 평가자에 대한 시행 횟수이고, 경우 2에서 m = 모든 평가자에 대한 시행 횟수입니다. |
| n | 표본 개수 |
| xij | 범주 j 내 i 표본에 대한 등급의 수 |
Fleiss의 카파 통계량(표준을 알고 있는 경우)
각 표본에 대한 표준 등급을 알고 있는 경우 전체 카파 및 특정 범주에 대한 카파를 계산하려면 다음 단계를 수행하십시오.
시행 횟수가 m번이라고 가정합니다.
참고
Fleiss의 카파 통계량(표준을 알 수 없는 경우)의 공식을 참조하십시오.
- 각 시행에 대해 시행에서 평가한 등급 및 표준에 의해 지정된 등급을 사용하여 카파를 계산합니다. 즉, 표준을 다른 시행으로 간주하고 두 번의 시행에 대한 카파 공식(표준을 알 수 없는 경우)을 사용하여 카파를 추정합니다.
- m번의 모든 시행에 대해 계산을 반복합니다. 이제 m개의 전체 카파 값과 특정 범주 값에 대한 m개의 카파 값이 있습니다.
표준을 알고 있는 전체 카파는 m개의 전체 카파 값의 평균과 같습니다.
마찬가지로 표준을 알고 있는 특정 범주에 대한 카파는 특정 범주 값에 대한 m개의 모든 카파에 대한 평균과 같습니다.
Fleiss의 카파의 유의성 검정(표준을 알고 있는 경우)
귀무 가설, H0: 카파 = 0. 대립 가설, H1: 카파 > 0.
귀무 가설 하에서 Z는 근사적으로 정규 분포를 따르며 p-값을 계산하는 데 사용됩니다.

여기서 K는 카파 통계량, Var(K)는 카파 통계량의 분산입니다.
참고
Fleiss의 카파 통계량(표준을 알 수 없는 경우)의 공식을 참조하십시오.
시행 횟수가 m번이라고 가정합니다.
- 각 시행에 대해 시행에서 평가한 등급 및 표준에 의해 지정된 등급을 사용하여 카파의 분산을 계산합니다. 즉, 표준을 두 번째 시행으로 간주하고, 두 번의 시행에 대한 카파의 분산 공식(표준을 알 수 없는 경우)을 사용하여 분산을 계산합니다.
- m번의 모든 시행에 대해 계산을 반복합니다. 이제 전체 카파에 대해 m개의 분산을 계산하고 특정 범주의 카파에 대해 m개의 분산을 계산했습니다.
표준을 알고 있는 경우 전체 카파의 분산은 전체 카파에 대한 m개 분산의 합을 m2로 나눈 값과 같습니다.
마찬가지로, 표준을 알고 있는 경우 특정 범주에 대한 카파의 분산은 특정 범주의 카파에 대한 m개 분산의 합을 m2로 나눈 값과 같습니다.