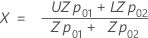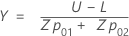표본 크기 n과 임계 거리 k는 지정된 규격 한계의 수 및 표준 편차가 알려져 있는지 여부에 따라 계산됩니다.
단일 규격 한계 및 알려진 표준 편차
표본 크기는 다음과 같이 지정됩니다.
임계 거리는 다음과 같이 지정됩니다.
설명:
표기법
용어
설명
Z1
표준 정규 분포의 (1 – p1) * 100 백분위수
p1
합격 품질 수준(AQL)
Z2
표준 정규 분포의 (1 – p2) * 100 백분위수
p2
불합격 품질 수준(RQL)
Zα
표준 정규 분포의 (1 – α) * 100 백분위수
α
생산자 위험
Zβ
표준 정규 분포의 (1 – β ) * 100 백분위수
β
소비자 위험
단일 규격 한계 및 알려져 있지 않은 표준 편차
표기법은 단일 규격 한계 및 알려진 표준 편차의 경우와 같습니다. 표본 크기는 다음과 같이 지정됩니다.
임계 거리는 다음과 같이 지정됩니다.
이중 규격 한계 및 알려진 표준 편차
아래 정의되지 않은 표기법은 단일 규격 한계 및 알려진 표준 편차의 경우와 같습니다. 먼저 Minitab은 z를 계산합니다.
그런 다음 Minitab에서는 표준 정규 분포에서 p*(z에 해당하는 위쪽 꼬리 영역)를 찾습니다. 이 값은 규격 한계 중 하나를 벗어나는 최소 불량 확률입니다.
Minitab에서 표본 크기 및 임계 거리 계산에 사용하는 방법은 이 p* 값에 따라 달라집니다.
p1 = AQL, p2 = RQL
2p* ≤ (p1/ 2)이면 두 사양이 비교적 멀리 떨어져 있고 계산이 단일 한계 계획을 따릅니다.
p1/ 2 < 2p* ≤ p1이면 두 사양이 비교적 멀리 떨어져 있지 않지만, 특정 평균 값에 대해 최소 불량 확률을 찾을 수 있을 정도로 아주 가깝지는 않습니다. Minitab에서는 표본 크기 및 임계 거리를 찾기 위해 반복을 수행합니다.
그러면
μ = μ0+ m * h, 여기서 h = σ/100
m = 1, 2, ...300입니다. 각 μ에 대해 다음을 계산합니다.
여기서 Φ는 표준 정규 분포의 누적분포함수입니다. Prob (X<L) + Prob (X>U)가 p1과 거의 같은 경우, Prob (X<L)과 Prob (X>U) 중 더 큰 값을 사용하여 표본 크기와 합격 수를 찾습니다.
Prob (X<L)가 더 크다고 가정하고 pL = Prob (X<L)이라고 설정합니다.
표본 크기는 다음과 같이 지정됩니다.
임계 거리는 다음과 같이 지정됩니다.
설명:
표준 정규 분포의 ZpL = (1 – pL) * 100 백분위수.
이미 모든 m 값을 사용하고 있지만 해당 확률에 p1이 포함되지 않으면 p1이 너무 크고, 따라서 측정값의 평균이 구간 [L, U]의 중점에서 멀리 떨어져 있는 것입니다. 이 경우 단일 규격 한계에 대한 방법을 사용할 수 있으며 ZpL = Z1입니다. Z1은 단일 규격 한계의 경우와 같이 정의됩니다.
p1 < 2p* < p2이면 두 규격 한계 및 표준 편차에 의해 결정된 최소 불량 확률이 합격 품질 수준 p1보다 크기 때문에 계획 규격을 다시 고려해야 합니다. 부지를 거부하거나 p1보다 결함이 약간 더 큰 계획을 고려할 수 있습니다.
2p* ≥ p2이면 로트를 불합격시켜야 합니다 두 규격 한계 및 표준 편차에 의해 결정된 최소 불량 확률이 불합격 품질 수준보다 큽니다. 제품을 검사하지 않고 로트를 불합격시킬 수 있습니다.
표기법
용어
설명
L
규격 하한
U
규격 상한
σ
알려진 표준 편차
이중 규격 한계 및 알려져 있지 않은 표준 편차(기본 절차)
표기는 이전 섹션과 동일합니다. Minitab에서는 임계 거리를 별도의 두 단일 한계 계획의 경우 지정된 값으로 설정합니다.
여기서 Beta는 형상 모수가 a 및 b인 베타 분포의 누적 분포 함수입니다. 여기에서, .
그런 다음,
여기서 Beta-1은 2단계의 베타 분포의 역 누적 분포 함수입니다.
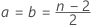
n ≤ 2이면 최대 표준 편차(MSD)를 계산할 수 없습니다.
이중 규격 한계 및 알려져 있지 않은 표준 편차(Wallis 절차)
표기는 이전 섹션과 동일합니다. 다음 절차는 Schilling의 도서에서 확인할 수 있습니다.2
먼저 Minitab에서는 임계 거리를 별도의 두 단일 한계 계획의 경우 지정된 값으로 설정합니다.
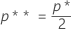
그런 다음 Minitab에서는 표준 정규 분포에서 k에 해당하는 위쪽 꼬리 영역 p*(백분위수) 및 p* / 2의 위쪽 꼬리 영역에 해당하는 백분위수 Zp**를 찾습니다.
최대 표준 편차(MSD)는 다음과 같이 지정됩니다.
추정 표준 편차는 다음과 같이 지정됩니다.
Minitab에서는 추정 표준 편차 s가 MSD보다 작거나 같은지 여부를 검정합니다.
추정 표준 편차 s가 MSD보다 작거나 같은 경우 표본 크기는 다음과 같이 지정됩니다.
추정 표준 편차 s가 MSD보다 작거나 같은 경우 표준 편차가 너무 커서 합격 기준과 일치하지 않으며 로트를 불합격시켜야 합니다.
표기법
용어
설명
Xi
i번째 측정값
실제 측정값의 평균
합격 확률
p를 OC 곡선 상에 있는 점의 x 값인 불량 확률로 설정합니다.
단일 규격 한계 및 알려진 표준 편차
단일 규격 하한 및 알려진 표준 편차
Prob (X < L) = p.
단일 규격 상한 및 알려진 표준 편차
Prob (X > L) = p.
단일 규격 한계 및 알려져 있지 않은 표준 편차
이중 규격 한계 및 알려진 표준 편차
먼저 Minitab은 z를 계산합니다.
그런 다음 표준 정규 분포에서 p*(z에 해당하는 위쪽 꼬리 영역)를 찾습니다. 이 값은 규격 한계 중 하나를 벗어나는 최소 불량 확률입니다.
Minitab에서 합격 확률에 사용하는 방법은 이 p* 값에 따라 달라집니다.
p1 = AQL, p2 = RQL로 설정합니다.
2p* ≤ (p1/ 2)이면 두 한계가 비교적 멀리 떨어져 있고 표본 크기 및 임계 거리가 단일 한계 계획을 따라 계산됩니다.
p1/ 2 < 2p* ≤ p1이면 두 규격이 비교적 멀리 떨어져 있지 않지만, 특정 평균 값에 대해 최소 불량 확률을 찾을 수 있을 정도로 아주 가깝지는 않습니다.
지정된 p에 대해 Minitab에서는 그리드 검색 알고리즘을 사용하여 측정값의 평균 μ를 찾습니다. 그런 다음,
이중 규격 한계 및 알려져 있지 않은 표준 편차
규격 상한과 규격 하한이 모두 있지만 표준 편차를 모르는 경우, Minitab에서는 단일 한계 계획에 대한 OC 곡선을 사용하여 이중 규격 한계 사례를 근사합니다. 지정된 p1, p2, α 및 β의 단일 한계 곡선에 대해 파생된 OC 곡선은 동일한 p1, p2, α 및 β의 양측 규격 계획에 대한 OC 곡선 구간의 하한이며, 대부분의 실제적인 경우 양측 계획에 대한 OC 곡선으로 사용할 수 있습니다. Duncan1을 참조하십시오.
Duncan (1986). Quality Control and Industrial Statistics, 5th edition.
표기법
용어
설명
n
표본 크기
k
임계 거리
σ
알려진 표준 편차
Zp
표준 정규 분포의 (1 - p)번째 백분위수
Φ
표준 정규 분포의 누적분포함수
T
는 자유도 = n – 1이고 비중심 모수
L
규격 하한
U
규격 상한
불합격 확률
불합격 확률(Pr)은 특정 표본 추출 계획 및 인입 불량 비율에 따라 특정 로트를 불합격시킬 확률입니다. 불합격 확률은 1 - 합격 확률입니다.
Pr = 1 – Pa
설명:
Pa = 합격 확률
평균 출검 품질(AOQ)
평균 출검 품질은 검사 후 제품의 품질 수준을 나타냅니다. 평균 출검 품질은 인입 부분 불량률이 달라짐에 따라 달라집니다.
표기법
용어
설명
Pa
합격 확률
p
인입 부분 불량률
N
로트 크기
n
표본 크기
평균 총검사량(ATI)
평균 총 검사량은 특정한 로트 내 품질 수준에 대한 평균 검사 항목 수를 나타냅니다.
표기법
용어
설명
Pa
합격 확률
N
로트 크기
n
표본 크기
합격 영역(AR) - 기본 절차
합격 영역은 두 규격이 모두 지정되고 표준 편차가 알려져 있지 않은 경우에만 계산됩니다.
n 및
k의 정의를 찾아보고 방정식의 표기법을 확인하려면 각각 표본 크기 및 임계 거리에 대한 절로 이동하십시오.
합격 영역 그림에서 x-축은 표본 평균이고 y-축은 표본 표준 편차입니다. 합격 영역은 최대 표준 편차(MSD) 외에 표본 표준 편차와
표본 평균의 세 함수로 구성됩니다. 표본 표준 편차가 MSD를 초과하는 표본 평균 값의 경우 합격 영역의 상한은 MSD입니다.
규격 상한 또는 하한 가까이에 있는 경우 합격 영역의 한계는 다음 두 함수로 계산됩니다.
표본 평균의 값이 규격 한계의 중간에 더 가까워짐에 따라 합격 영역의 상한의 좌표는 다음 단계에 따라 계산됩니다.
그러면 .
경우 여기서
Beta는 형상 모수가
a 및
b인 베타 분포의 누적 분포 함수입니다. 여기에서, .
p01 및
p02 비율 쌍을 정의하고, 이는 p02 + p01 = p*를 만족
다음으로
여기서
Beta-1은 2단계의 베타 분포의 역 누적 분포 함수입니다.
,
평균과 표준 편차 좌표는 다음 방정식으로 계산됩니다.
합격 영역(AR) - Wallis 절차
다음은 해석에 사양이 둘 모두 있지만 표준 편차가 알 수 없는 경우를 위한 것입니다. 절차는 Schilling의 도서에서 확인할 수 있습니다.2
이 그림에서 x축은 표본 평균값()을 표시하고 y축은 표준 편차의 값을 표시합니다. x축과의 조합으로 다음 선은 합격 삼각형을 형성합니다.
파선과 x축은 보다 정확한 영역을 형성합니다. 파선을 형성하려면 다음 단계를 사용하십시오.
표준 정규 분포에서 임계 거리에 해당하는 위쪽 꼬리 영역 p*를 백분위수로 합니다. P(Z > k).
p02 + p01 = p*를 만족하는 p01 및 p02의 값을 선택:
p01 = (p* / 100) * h
p02 = (p* / 100) * (100 - h)
여기서 h는 1에서 00까지의 값이 나옵니다.
다음 방정식을 사용하여 X 및 Y 좌표를 정의합니다.
표기법
용어
설명
L
규격 하한
U
규격 상한
k
임계 거리
Zp01
표준 정규 분포의 (1 - p01)* 100 백분위수
Zp02
표준 정규 분포의 (1 - p02)* 100 백분위수
p01
(p* / 100) * h
p02
(p* / 100) * (100 – h)
1 Duncan, A. J. (1986). Quality Control and Industrial Statistics (5th ed.). Homewood, Ill: Irwin.
2 Schilling and Neubauer (2009). Acceptance Sampling in Quailty Control (2nd ed.)
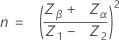

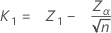
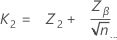
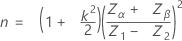
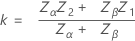
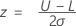
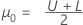

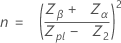


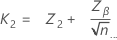
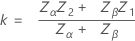
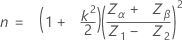
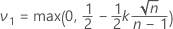

 .
.
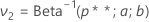


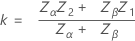
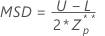
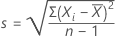
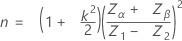
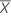




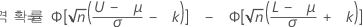

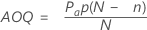

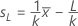

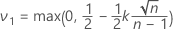 .
.
 여기서
Beta는 형상 모수가
a 및
b인 베타 분포의 누적 분포 함수입니다. 여기에서,
여기서
Beta는 형상 모수가
a 및
b인 베타 분포의 누적 분포 함수입니다. 여기에서, 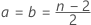 .
.


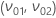 ,
평균과 표준 편차 좌표는 다음 방정식으로 계산됩니다.
,
평균과 표준 편차 좌표는 다음 방정식으로 계산됩니다. 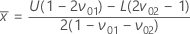
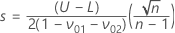
 )을 표시하고 y축은 표준 편차의 값을 표시합니다. x축과의 조합으로 다음 선은 합격 삼각형을 형성합니다.
)을 표시하고 y축은 표준 편차의 값을 표시합니다. x축과의 조합으로 다음 선은 합격 삼각형을 형성합니다.