포아송 분포의 정의
포아송 분포는 람다(λ)라는 하나의 모수로 지정됩니다. 이 모수는 평균과 분산이 같습니다. 람다가 충분히 큰 값으로 증가하면 정규 분포 (λ, λ)가 포아송 분포를 근사시키기 위해 사용될 수 있습니다.
포아송 분포는 한정된 관측 공간에서 사건이 발생하는 횟수를 설명하기 위해 사용합니다. 예를 들어, 포아송 분포는 비행기 기계 시스템의 결점 수나 콜 센터에 대한 시간당 통화 수를 설명합니다. 품질 관리, 신뢰성/생존 연구 및 보험에 포아송 분포가 자주 사용됩니다.
- 데이터는 사건 횟수(상한이 없는 음수가 아닌 정수)입니다.
- 모든 사건은 독립적입니다.
- 해당 기간 동안 평균 비율은 변경되지 않습니다.
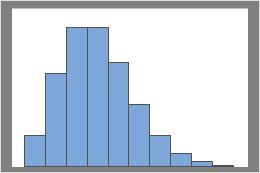
람다 = 3
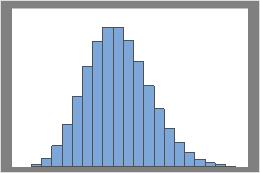
람다 = 10
발생률의 정의
발생률은 평균(λ)을 관측 공간 크기로 나눈 값입니다. 발생률은 여러 관측 공간에서 수집된 포아송 카운트를 비교하는 데 유용합니다. 예를 들어, 교환대 A는 5시간 동안 50통의 전화를 수신하고 교환대 B는 10시간 동안 80통의 전화를 수신합니다. 이 값들은 관측 공간이 서로 다르기 때문에 직접 비교할 수 없습니다. 이 카운트를 비교하려면 발생 비율을 계산해야 합니다. 교환대 A의 비율은 (50통/5시간) = 10통/1시간입니다. 교환대 B의 비율은 (80통/10시간) = 8통/1시간입니다.
포아송 분포와 이항 분포의 차이
포아송 분포는 이항 분포와 비슷합니다. 둘 다 사건 횟수를 모형화하기 때문입니다. 그러나 포아송 분포의 경우 유한한 관측 공간에서 이 카운트에 대해 상한을 설정하지 않는 데, 교환대에서 하루 동안 수신할 수 있는 전화 수에 제한이 없으므로 포아송 분포의 요구 사항을 위반하지 않습니다. 반대로, 이항 분포에서는 카운트의 상한을 설정하므로, 관측하는 사건의 수가 시행 횟수보다 클 수 없습니다.