초기하 분포의 정의
초기하 분포는 표본이 추출된 모집단의 총 항목 수를 알고 있을 때 고정 표본 크기의 사건 수를 모형화하는 이산형 분포입니다. 각 표본 항목의 가능한 결과는 2개(사건 또는 비사건)입니다. 표본은 비복원이므로 표본의 모든 항목이 서로 다릅니다. 모집단에서 한 번 선택한 항목은 다시 선택할 수 없습니다. 따라서 아직 선택하지 않은 항목이 선택될 가능성은 매 시행마다 증가합니다.
초기하 분포는 비교적 작은 모집단에서 비복원으로 추출되는 표본에 사용됩니다. 예를 들어 초기하 분포는 두 비율 간의 차이를 검사하는 Fisher의 정확 검정과 유한한 크기의 고립된 로트에서 표본을 추출하는 계수형 합격 표본 추출에 사용됩니다.
초기하 분포는 3가지 모수, 즉 모집단 크기, 모집단 내 사건 카운트 및 표본 크기로 정의됩니다.
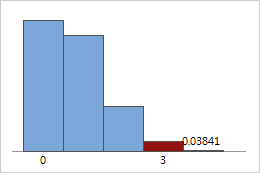
초기화 확률 계산 예제
시험 운전 가능한 차가 10대 있고(N = 10) 그 중 5대에 터보 엔진이 장착되어 있다고 가정합니다(x = 5). 3대를 시험 운전할 경우(n = 3) 3대 중 2대에 터보 엔진이 장착되어 있을 확률은 얼마입니까?
- 을 선택합니다.
- 확률을 선택합니다.
- 모집단 크기(N)에 10을 입력합니다. 모집단 내 사건 카운트(M)에, 5를 입력합니다. 표본 크기(n)에 3을 입력합니다.
- 입력 상수을 선택한 다음 2를 입력합니다.
- 확인을 클릭합니다.
10대 중에서 3대를 시험 운전할 때 터보 엔진이 있는 차 2대를 정확히 선택할 확률은 41.67%입니다.
초기하 분포와 이항 분포의 차이
초기하 분포와 이항 분포 모두 일정한 횟수의 시행에서 발생하는 사건의 횟수를 나타냅니다. 이항 분포의 경우 모든 시행에 대해 확률이 같습니다. 초기하 분포의 경우 비복원이기 때문에 각 시행의 결과에 따라 다음 시행의 확률이 바뀝니다.
모집단이 아주 크면 시행 결과는 다음 결과가 사건 또는 비사건일 확률에 거의 영향을 미치지 않기 때문에 이항 분포를 사용합니다. 예를 들어, 100,000명의 모집단에서 53,000명의 혈액형이 O+입니다. 표본에서 첫 번째로 랜덤하게 선택된 사람의 혈액형이 O+일 확률은 0.530000입니다. 표본의 첫 번째 사람의 혈액형이 O+이면 두 번때 사람의 혈액형이 O+일 확률은 0.529995입니다. 이러한 확률 간의 차이는 대부분 무시해도 좋을 만큼 작습니다.
모집단이 아주 작으면 시행 결과는 다음 결과가 사건 또는 비사건일 확률에 큰 영향을 미치기 때문에 초기하 분포를 사용합니다. 예를 들어, 10명의 모집단에서 7명의 혈액형이 O+입니다. 표본에서 첫 번째로 랜덤하게 선택된 사람의 혈액형이 O+일 확률은 0.70000입니다. 표본의 첫 번째 사람의 혈액형이 O+이면 두 번때 사람의 혈액형이 O+일 확률은 0.66667입니다. 표본 크기가 증가하면 차이가 증가할 수 있습니다. 이러한 확률 간의 차이는 대부분 너무 커서 무시할 수 없습니다.