계량형 포아송 공정의 사건 간 시간을 모형화하려면 지수 분포를 사용합니다. 일정한 비율로 독립 사건이 발생한다고 가정합니다.
이 분포는 제품 및 시스템, 대기열 이론 및 Markov 체인의 신뢰도 분석과 같은 광범위한 용도에 응용됩니다.
예를 들어 지수 분포는 다음을 모형화하는 데 사용할 수 있습니다.
- 전자 부품에 고장이 발생할 때까지 경과하는 시간
- 고객이 터미널에 도착하는 시간 간격
- 대기 중인 고객에게 서비스를 제공하는 시간
- 지불 불이행이 발생할 때까지 경과하는 시간(신용 위험 모형화)
- 방사성 원자핵이 붕괴될 때까지 경과하는 시간
2-모수 지수 분포는 척도 및 분계점 모수를 사용하여 정의됩니다. 분계점 모수 θ가 양수이면 분포가 θ 거리만큼 오른쪽으로 이동합니다. 예를 들어, θ = 5인 시스템의 고장을 연구하려고 합니다. 이것은 작동한지 5시간 후에만 고장이 발생하며 그 전에는 고장이 발생하지 않음을 의미합니다. 다음 그래프에서 분계점 모수 θ는 5와 같고 분포를 오른쪽으로 5 단위 이동합니다. 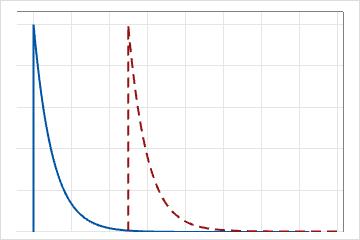
1-모수 지수 분포는 분계점 모수가 0이며 척도 모수를 사용하여 정의됩니다. 1-모수 지수 분포의 경우 척도 모수가 평균과 같습니다.
무기억성의 의미
지수 분포의 중요한 특성은 기억되지 않는다(무기억성)는 것입니다. 사건의 확률은 과거 시행에 종속되지 않습니다. 따라서 발생률이 일정하게 유지됩니다.
기억되지 않는다는 특성은 부품의 남은 수명이 현재까지의 사용 기간과 무관함을 나타냅니다. 예를 들어, 동전 던지기의 랜덤 시행은 이러한 특성을 나타냅니다. 마모되거나 균열이 발생하여 나중에 고장날 가능성이 더 많은 시스템은 기억되지 않는 특성이 없는 것입니다.