히스토그램
히스토그램은 표본 값을 여러 구간으로 나누고 각 구간 내 데이터 값의 빈도를 막대로 나타냅니다.
해석
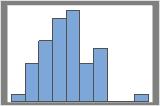
50개의 재표본
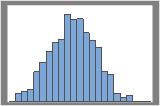
1000개의 재표본
보통 분포는 재표본이 더 많을 때 확인하기 더 쉽습니다. 예를 들어, 이러한 데이터에서 분포는 50개의 재표본에 대해 여러 가지로 해석할 수 있습니다. 재표본이 1000개인 경우 형상은 거의 정규 분포에 가깝습니다.
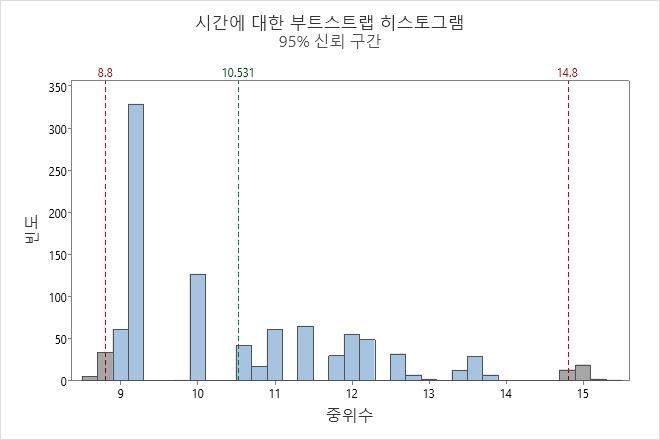
이 히스토그램에서 부트스트랩 분포가 정규 분포처럼 나타나지 않습니다. 원본 표본에는 데이터 점이 16개뿐입니다. 신뢰할 수 있는 신뢰 구간을 얻으려면 더 큰 표본을 수집하여 분석을 다시 수행해야 합니다.
개별 값 그림
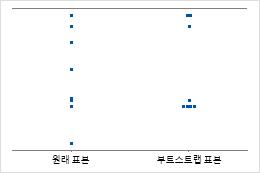
개별 값 그림은 표본 내 개별 값을 표시합니다. 각 원은 하나의 관측치를 나타냅니다. 개별 값 그림은 관측치 수가 비교적 적고 각 관측치의 영향도 평가해야 하는 경우 특히 유용합니다.
참고
Minitab은 재표본을 하나만 가져온 경우 개별 값 그림만 표시합니다. Minitab은 원래 데이터와 재표본 데이터를 모두 표시합니다.
해석
표본 8의 크기
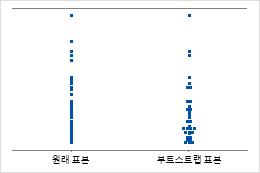
표본 50의 크기
막대 차트
막대 차트는 각 범주의 발생 비율을 나타냅니다.
참고
Minitab은 재표본을 하나만 가져온 경우 막대 차트를 표시합니다. Minitab은 원래 데이터와 재표본 데이터를 모두 표시합니다.
해석
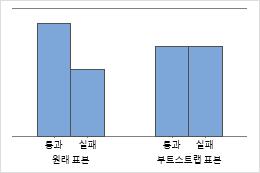
표본 8의 크기
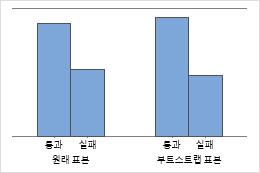
표본 50의 크기
재표본 수
재표본 수는 Minitab이 원래 데이터 집합에서 복원으로 랜덤 표본을 가져오는 횟수입니다. 보통 많은 수의 재표본이 가장 적합한 방법입니다. 각 재표본의 표본 크기는 원래 데이터 집합의 표본 크기와 같습니다. 재표본 수는 히스토그램에 있는 관측치 수와 같습니다.
평균
평균은 재표본 수로 나눈 부트스트래핑 표본의 선택한 통계량에 대한 합입니다.
해석
Minitab은 관측 표본 값과 부트스트랩 분포 값(평균) 이렇게 선택한 통계량의 두 차이 값을 표시합니다. 이 두 값 모두 모집단 모수의 추정치이며 보통 비슷합니다. 이 두 값 사이에 차이가 클 경우 원래 표본의 표본 크기를 늘려야 합니다.
평균은 전체 모집단이 아니라 표본 데이터를 기반으로 하기 때문에 평균이 모집단 모수와 같을 가능성은 없습니다. 모집단 모수를 더 잘 추정하려면 신뢰 구간을 사용하십시오.
표준 편차(부트스트랩 표본)
부트스트랩 표본의 표준 편차(부트스트랩 표준 오차라고도 함)는 선택한 통계의 표본 추출 분포에 대한 표준 편차 추정치입니다.
해석
부트스트랩 표본에서 선택한 통계가 전체 평균을 중심으로 퍼져 있는 정도를 확인하려면 표준 편차를 사용합니다. 표준 편차 값이 클수록 더 퍼져 있다는 것을 나타냅니다.
부트스트랩 표본의 표준 편차를 사용하여 부트스트랩 통계가 모수를 얼마나 정확하게 추정하는지 확인할 수 있습니다. 값이 작을수록 모수 백분위수의 더 정확한 추정치를 나타냅니다. 표본 크기가 클수록 부트스트랩 표준 오차가 더 작고 모수 백분위수의 추정치가 더 정확하게 됩니다.
신뢰 구간(CI) 및 한계
신뢰 구간은 통계량의 표본 추출 분포를 근거로 합니다. 통계량에 모수 추정량으로의 치우침이 없는 경우 해당 표본 추출 분포는 모수의 참 값 중심에 위치합니다. 부트스트래핑 분포는 통계량에 대한 표본 추출 분포와 근사합니다. 따라서 부트스트래핑 분포 값의 중간 95%는 모수에 대한 95% 신뢰 구간을 제공합니다. 신뢰 구간은 추정치의 실제 유의성을 평가하는 데 도움이 됩니다. 해당 상황에 실제적으로 유의한 값이 신뢰 구간에 포함되는지 여부를 확인하려면 전문 지식을 이용하십시오.
참고
Minitab은 재표본 수가 너무 작아서 정확한 신뢰 구간을 얻을 수 없는 경우 신뢰 구간을 계산하지 않습니다.
관측된 표본
| 변수 | N | 평균 | 표준 편차 | 분산 | 합 | 최소값 | 중위수 | 최대값 |
|---|---|---|---|---|---|---|---|---|
| 시간 | 16 | 11.331 | 3.115 | 9.702 | 181.300 | 7.700 | 10.050 | 16.000 |
평균에 대한 부트스트랩 표본
| 재표본 개수 | 평균 | 표준 편차 | μ에 대한 95% CI |
|---|---|---|---|
| 1000 | 11.3095 | 0.7625 | (9.8562, 12.8562) |
이 결과에서 모수 차이에 대한 추정치는 11.3입니다. 모집단 비율이 대략 9.9와 12.9 사이에 있다고 95% 확신할 수 있습니다.