확률도에서는 추정 누적 확률을 기준으로 각 관측치의 값(반복되는 값 포함)을 표시하여 표본에서 추정 누적분포함수(CDF)를 만듭니다.
Minitab에서는 에서 선택한 항목(기본값은 중위수 순위)에 따라 다음 공식 중 하나를 사용하여 추정 누적 확률을 계산합니다. 각 공식에서 n은 관측치 수와 같으며, i는 각 관측치의 순위와 같습니다. 즉, 가장 작은 값의 경우 i = 1이 되고 가장 큰 값의 경우 i = n이 됩니다.
- 중위수 순위(Benard)
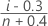
- 평균 순위(Herd-Johnson)

- 수정된 Kaplan-Meier(Hazen)
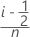
- Kaplan-Meier

참고
Kaplan-Meier 방법의 결과는 가장 큰 관측치에 대해 p = 1입니다. 결과 값을 그림에 사용할 수 없으므로, Minitab에서는 가장 큰 p를 이전 p와 1 간 거리의 90%로 대신 계산합니다.
적합 분포선은 선택한 이론적 분포에 대한 CDF를 지정된 모수(추정 모수 또는 과거 모수)로 나타냅니다. 과거 모수를 제공하지 않으면 Minitab은 최소 제곱(정규 또는 로그 정규 분포) 및 최대우도 추정 방법(기타 분포)을 사용하여 모수를 추정합니다.
y-값(경우에 따라 x-값)은 적합선이 선형이 될 수 있도록 변환됩니다. 그러나 눈금 레이블은 항상 변환되지 않은 값과 일치합니다. 따라서 데이터가 선택한 분포에 적합되는 경우에는 표시된 점도 직선 형태를 이룹니다.
다음 표에서는 각 분포에 사용되는 변환을 보여줍니다.
| 분포 | X 좌표 | Y 좌표(점수) |
|---|---|---|
| 정규 분포 | 데이터 | |
| 로그 정규 분포 | ln(데이터) | |
| 3-모수 로그 정규 분포 | ln(데이터 - 분계점) | |
| 감마 | ln(데이터) | G-1(p), k |
| 3-모수 감마 분포 | ln(데이터 - 분계점) | G-1(p), k |
| 지수 분포 | ln(데이터) | ln(-ln(1 - p)) |
| 2-모수 지수 분포 | ln(데이터 - 분계점) | ln(-ln(1 - p)) |
| 최소 극단값 분포 | 데이터 | ln(-ln(1 - p)) |
| Weibull 분포 | ln(데이터) | ln(-ln(1 - p)) |
| 3-모수 Weibull 분포 | ln(데이터 - 분계점) | ln(-ln(1 - p)) |
| 최대 극단값 분포 | 데이터 | -ln(-ln(p)) |
| 로지스틱 분포 | 데이터 |
 |
| 로그 로지스틱 분포 | ln(데이터) |
 |
| 3-모수 로그 로지스틱 분포 | ln(데이터 - 분계점) |
 |
중요
분계점에 맞게 수정되지 않은 데이터를 표시할 경우 분포 적합선은 직선으로 표시되지 않습니다.
표기법
| 용어 | 설명 |
|---|---|
| 데이터 | 관측치에 대한 데이터 값 |
| In(x) | x의 자연 로그 |
| 표준 정규 분포의 경우 역 누적분포함수에서 p에 대해 반환된 값. | |
| G-1(p),k | 형상 = k이고 척도 = 1인 감마 분포의 경우 역 CDF에서 p에 대해 반환된 값. 과거 값을 입력하지 않으면 Minitab에서는 추정된 형상 모수를 사용합니다. |