1단계: 모형 관계 검색 및 관계의 강도 평가
어느 모형 관계가 데이터에 가장 적합한지 확인하고 관계의 강도를 평가합니다.
팁
특정 모형이 데이터에 적합한 정도를 더 효과적으로 시각화하려면 적합 회귀선을 사용하여 산점도를 생성합니다.
관계 유형
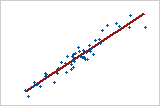
선형: 양
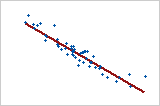
선형: 음
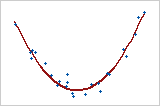
곡선: 2차
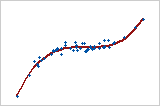
곡선: 3차

아무런 관계도 없음
데이터가 모형에 적합한 것으로 보이면 회귀 분석을 사용하여 관계를 조사할 수 있습니다.
관계의 강도
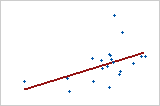
약한 관계
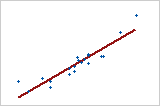
강한 관계
선형(직선) 관계의 강도를 수량화하려면 상관 분석을 사용하십시오.
2단계: 비정규 또는 비정상 데이터의 지시자 확인
치우친 데이터 및 다봉 데이터는 데이터가 비정규 데이터일 수도 있다는 것을 나타냅니다. 특이치는 데이터의 다른 조건을 나타낼 수도 있습니다.
치우친 데이터
데이터가 치우쳐 있으면 대부분의 데이터가 그래프의 높은 쪽이나 낮은 쪽에 위치합니다. 왜도는 데이터가 정규 분포를 따르지 않을 수도 있음을 나타냅니다. 주변 분포도에서 여백의 그래프에 치우친 데이터가 표시되는지 확인합니다.
- 히스토그램
-
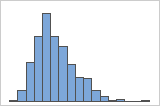
오른쪽으로 치우침
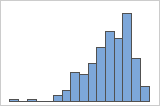
왼쪽으로 치우침
- 점도표
-

오른쪽으로 치우침

왼쪽으로 치우침
- 상자 그림
-
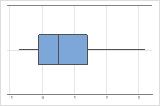
오른쪽으로 치우침
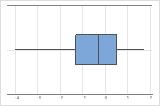
왼쪽으로 치우침
데이터가 자연스럽게 치우쳐 있지 않다는 것을 알고 있으면 가능한 원인을 조사하십시오. 심하게 치우친 데이터를 분석하려면 분석에 대한 데이터 고려 사항을 읽어보고 정규 분포를 따르지 않는 데이터를 사용할 수 있는지 확인하십시오.
특이치
다른 데이터 값에서 멀리 떨어져 있는 데이터 값인 특이치는 결과에 크게 영향을 미칠 수 있습니다. 주변 분포도에서 여백의 산점도와 그래프에 특이치가 있는지 확인합니다.
- 산점도
-
산점도에서는 고립된 점이 특이치를 나타냅니다.

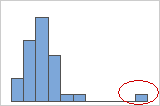
- 히스토그램
-
히스토그램에서는 양쪽 끝의 고립된 막대가 특이치를 나타냅니다.
- 점도표
-
점도표에서는 비정상적으로 낮거나 높은 데이터 값이 가능한 특이치를 나타냅니다.

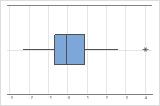
- 상자 그림
-
상자 그림에서 특이치는 별표(*)로 표시됩니다.
특이치의 원인을 식별해 보십시오. 모든 데이터 입력 또는 측정 오류를 수정하십시오. 비정상적인 일회성 사건과 연관된 데이터 값을 삭제해 보십시오(특수 원인). 그런 다음 분석을 반복하십시오.
다봉 데이터
다봉 데이터에는 봉우리가 두 개 이상 있습니다. (봉우리는 데이터 집합의 최빈값을 나타냅니다.) 다봉 데이터는 일반적으로 두 개 이상의 공정이나 조건(예: 두 개 이상의 온도)에서 데이터가 수집되는 경우 발생합니다.
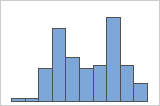
히스토그램

점도표
관측치를 그룹으로 분류할 수 있는 추가 정보가 있는 경우 이 정보를 사용하여 그룹 변수를 만들 수 있습니다. 그런 다음, 그룹으로 히스토그램 또는 점도표를 생성하여 그룹 변수가 데이터의 봉우리를 설명하는지 여부를 확인할 수 있습니다.
3단계: 그룹 관련 패턴 확인
그래프에서 데이터에 그룹이 포함되었다는 것을 나타내는 패턴을 찾을 수 있습니다. 관측치 그룹 간 x-y 관계의 차이를 확인합니다. 의미 있는 그룹을 찾으면 데이터를 더 정확하게 설명할 수 있습니다.
다음 그래프는 그룹 관련 패턴의 예입니다.
- 기울기가 서로 다른 그룹
- 그룹의 기울기가 가파를수록 x-값의 변화가 y-값의 더 큰 변화와 연관됩니다.
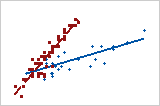
- 위치가 서로 다른 그룹
- 한 그룹의 특정 각 x-값에 대한 y-값이 다른 그룹보다 일관되게 더 높습니다.

- 군집의 그룹
- 이 산점도의 세 군집은 세 그룹을 나타냅니다.

- 그룹 관련 패턴 없음
- 이 두 그룹은 서로 다른 것으로 보이지 않습니다.
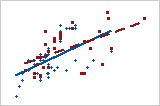
데이터에 그룹이 포함되어 있다고 생각되면 그룹을 사용하여 산점도를 생성하여 그룹을 시각화할 수 있습니다.