1단계: 주요 특성 평가
분포의 봉우리와 산포를 조사합니다. 표본 크기가 점도표의 모양에 어떻게 영향을 미칠 수 있는지 평가합니다.
봉우리 및 산포
가장 많은 점이 있는 빈인 봉우리를 표시합니다. 봉우리는 표본에서 가장 일반적인 값을 나타냅니다. 데이터의 변동성을 확인하려면 표본의 산포를 평가하십시오.
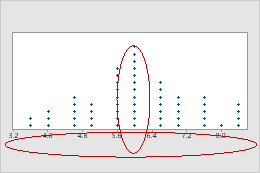
점도표의 갑작스럽거나 바람직하지 않은 특성을 조사합니다. 예를 들어, 고객 대기 시간의 점도표는 예상보다 더 넓은 산포를 보여줍니다. 조사 결과 컴퓨터의 소프트웨어 업데이트에 따라 고객 대기 시간이 불안정해지고 지연되었습니다.
표본 크기(n)
표본 크기가 그래프 모양에 영향을 미칠 수 있습니다.

n = 20
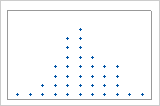
n = 100
점도표는 표본 크기가 약 50보다 작을 때 가장 적합합니다. 표본 크기가 50 이상이면 하나의 점이 두 개 이상의 관측치를 나타낼 수 있습니다. 분포의 특성을 더 쉽게 식별할 수 있도록 점도표 외에 상자 그림 또는 히스토그램을 사용하는 것을 고려해 보십시오.
2단계: 비정규 또는 비정상 데이터의 지시자 확인
치우친 데이터 및 다봉 데이터는 데이터가 비정규 데이터일 수도 있다는 것을 나타냅니다. 특이치는 데이터의 다른 조건을 나타낼 수도 있습니다.
치우친 데이터
데이터가 치우쳐 있으면 대부분의 데이터가 그래프의 높은 쪽이나 낮은 쪽에 위치합니다. 왜도는 데이터가 정규 분포를 따르지 않을 수도 있음을 나타냅니다. 일반적으로 히스토그램이나 상자 그림에서 왜도를 탐지하기가 가장 쉽습니다.
이 점도표는 치우친 데이터를 보여줍니다. 오른쪽으로 치우친 데이터의 점도표는 대기 시간을 보여줍니다. 대부분의 대기 시간이 비교적 짧고 몇 개의 대기 시간만 깁니다. 왼쪽으로 치우친 데이터의 점도표는 수명 데이터를 보여줍니다. 몇 개의 품목이 즉시 고장나고 더 많은 품목이 나중에 고장납니다.

오른쪽으로 치우침

왼쪽으로 치우침
데이터가 자연스럽게 치우쳐 있지 않다는 것을 알고 있으면 가능한 원인을 조사하십시오. 심하게 치우친 데이터를 분석하려면 분석에 대한 데이터 고려 사항을 읽어보고 정규 분포를 따르지 않는 데이터를 사용할 수 있는지 확인하십시오.
특이치
다른 데이터 값에서 멀리 떨어져 있는 데이터 값인 특이치는 결과에 크게 영향을 미칠 수 있습니다. 일반적으로 상자 그림에서 특이치를 식별하기가 가장 쉽습니다.

팁
데이터 점을 식별하려면 특이치 위에 포인터를 놓으십시오.
특이치의 원인을 식별해 보십시오. 모든 데이터 입력 또는 측정 오류를 수정하십시오. 비정상적인 일회성 사건과 연관된 데이터 값을 삭제해 보십시오(특수 원인). 그런 다음 분석을 반복하십시오.
다봉 데이터
다봉 데이터에는 봉우리가 두 개 이상 있습니다. (봉우리는 데이터 집합의 최빈값을 나타냅니다.) 다봉 데이터는 일반적으로 두 개 이상의 공정이나 조건(예: 두 개 이상의 온도)에서 데이터가 수집되는 경우 발생합니다.
예를 들어, 이 점도표는 같은 데이터의 그래프입니다. 단순 점도표에는 두 개의 봉우리가 있지만, 봉우리가 무엇을 의미하는 지는 확실하지 않습니다. 그룹이 표시된 점도표는 봉우리가 두 그룹에 해당한다는 것을 보여줍니다.

단순
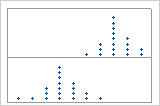
그룹 표시
관측치를 그룹으로 분류할 수 있는 추가 정보가 있는 경우 이 정보를 사용하여 그룹 변수를 만들 수 있습니다. 그런 다음, 그룹으로 그래프를 생성하여 그룹 변수가 데이터의 봉우리를 설명하는지 여부를 확인할 수 있습니다.
팁
기존 그래프에 그룹 변수를 추가하려면 그래프에서 데이터 표시를 두 번 클릭한 다음 그룹 탭을 클릭하십시오.
3단계: 그룹 평가 및 비교
점도표에 그룹이 있으면 그룹의 중심과 산포를 평가하고 비교합니다.
중심
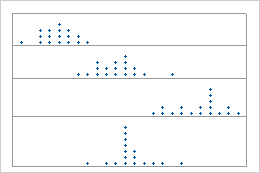
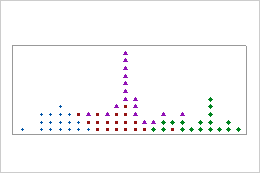
산포
그룹의 산포 간 차이를 확인합니다.
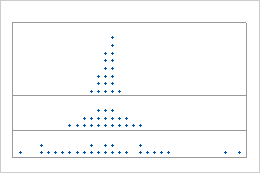
여러 패널로 표시되는 점도표
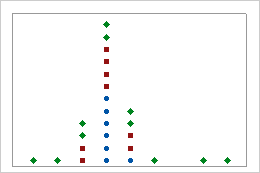
쌓인 점도표
- 그룹이 두 개뿐인 경우 두 표본 분산 검정을 사용합니다.
- 그룹이 세 개 이상인 경우 등분산 검정을 사용합니다.