In This Topic
N
The sample size (N) is the total number of observations in the sample. The sample size affects the expected number of runs and the p-value.
K
K is the value of the comparison criterion. By default, K is the mean of the sample data. But you can also specify a different value, such as the median. Minitab uses K to calculate the observed number of runs.
≤ K and > K
The number of observations above K is the number of observations that are greater than the value of the comparison criterion, which is the mean by default. The number of observations below K is the number of observations that are less than or equal to the comparison criterion. Minitab uses these values to calculate the p-value.
Null hypothesis and alternative hypothesis
- Null hypothesis
- The order of the data is random.
- Alternative hypothesis
- The order of the data is not random.
Observed number of runs and expected number of runs
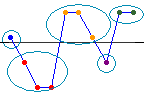
The expected number of runs is the mean of the sampling distribution of runs in a random series. If the number of observed runs is substantially greater than or less than the number of expected runs, it is likely that the data are not in random order. To determine whether the order of your data is random, compare the p-value to the significance level.
P-Value
The p-value is the probability that measures the evidence against the null hypothesis. Lower probabilities provide stronger evidence against the null hypothesis.
Interpretation
Use the p-value to determine whether the order of your data is random.
- P-value ≤ α: The order of the data is not random (Reject H0)
- If the p-value is less than or equal to the significance level, the decision is to reject the null hypothesis and conclude that the order of the data is not random.
- P-value > α: Cannot conclude the order of the data is not random (Fail to reject H0)
- If the p-value is greater than the significance level, the decision is to fail to reject the null hypothesis. You do not have enough evidence to conclude that the order of the data is not random.