α(アルファ)
有意水準(αまたはアルファと表されます)は、帰無仮説が真であるときにその帰無仮説を棄却する(タイプIの誤り)のリスクの最大許容水準です。また、αは、帰無仮説(H0)が真の場合の検定の検出力とも解釈できます。通常、データを分析する前に有意水準を選択します。デフォルトの有意水準は0.05です。
解釈
有意水準を使用して、帰無仮説(H0)が真の場合の検定の検出力値を最小化します。有意水準の値が高いほど、検定の検出力が高くなりますが、真である帰無仮説を棄却してしまうタイプIの誤りを犯す可能性も高くなります。
観測の長さ
ポアソン工程では、時間、領域、量、項目数など指定された観測範囲にわたって特定の事象の発生数を数えます。観測の長さは、各観測範囲の規模、期間、またはサイズを表します。
解釈
Minitabでは、観測の長さを使用して、出現率を各自の状況に最適な形式に変換します。
たとえば、各サンプル観測値が1年間の事象数であれば、長さ1は年間の出現率を表し、長さ12は月間の出現率を表します。
- 検査者が122か所の欠陥を見つけたため、出現総数は122です。
- 検査者が50箱を抽出したため、サンプルサイズ(N)は50です。
- 各箱に10枚のタオルが入っているため、タオル1枚あたりの欠陥数を特定するには、観測の長さに10を使用します。1箱あたりの欠陥数を特定するには、観測の長さに1を使用します。
- 出現率は、(出現総数/N) / (観測の長さ) = (122/50) / 10 = 0.244となります。したがって、平均では各タオルに0.244か所の欠陥があります。
比較率
比較率とは、仮説の率と比較する値のことです。
解釈
比較率が計算されます。比較率と仮説の率の間の差は、各サンプルサイズに対して、指定した水準の検定力を達成できる最小の差です。サンプルサイズが大きくなるほど、小さな差を検出できます。用途に対して実質的に影響のある最小の差を検出できるようにする必要があります。
サンプルサイズと、指定された検出力における比較率の関係をより詳しく調べるには、検出力曲線を使用します。
サンプルサイズ
サンプルサイズとは、サンプルに含まれる観測値の合計数のことです。
解釈
サンプルサイズを使用して、仮説検定において、特定の差で特定の検出力値を得るために必要な観測値数を推定します。
仮説率と比較率の間の差を検出するために、指定した検出力の検定に必要なサンプルサイズが計算されます。サンプルサイズは整数であるため、検定の実際の検出力は、指定した検出力値よりもわずかに大きくなる場合があります。
サンプルサイズを大きくすると、検定の検出力も高くなります。適切な検出力を達成するには、サンプル内の観測値数が十分である必要があります。しかし、サンプルサイズを大きくしすぎて、不必要なサンプリングに時間と費用を浪費したり、重要でない差が統計的に有意であることを検出することは望ましくありません。
サンプルサイズと、指定された検出力における差の関係をより詳しく調べるには、検出力曲線を使用します。
検出力
仮説検定の検出力は、検定で帰無仮説が正しく棄却される確率です。仮説検定の検出力は、サンプルサイズ、差、データの変動性、検定の有意水準に影響されます。
詳細は、検出力とはを参照してください。
解釈
Minitabでは、特定の比較割合と標本の大きさに基づいて、検定の検出力が計算されます。検出力は通常、0.9で十分だと考えられます。0.9という値は、仮説割合と母集団比較割合の差が存在する場合に、差を90%の確率で検出できることを示します。検定の検出力が弱い場合、差を検出できず、何も存在しないという誤った結論を出す可能性があります。通常、標本の大きさまたは差が小さいほど、検定の差の検出力は弱くなります。
検定の比較率と検出力値を入力すると、Minitabでは、サンプルに必要とされるサイズが計算されます。またMinitabでは、そのサンプルサイズで検定を行う場合の実際の検出力も計算されます。サンプルサイズは整数であるため、検定の実際の検出力は、指定した検出力値よりもわずかに大きくなる場合があります。
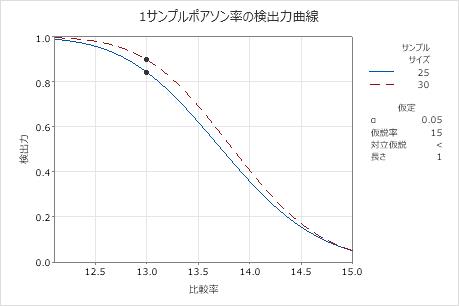
検出力曲線
この検出力曲線では、検定の検出力と比較率が対比されてプロットされます。
解釈
検出力曲線を使用して、検定に適したサンプルサイズと検出力を評価します。
この検出力曲線は、有意水準を一定に保って、各サンプルサイズに対する検出力と比較率のすべての組み合わせを表します。検出力曲線上の記号は、入力した値に基づいて計算された値を表します。たとえば、サンプルサイズと検出力の値を入力すると、それに対応する比較比率が計算され、計算された値がグラフ上に表示されます。
曲線上の値を調べることにより、特定の検出力値とサンプルサイズにおいて検出できる比較率と仮説率の差を決定できます。通常、検出力の値として0.9は適切であるとされます。ただし、分析者によっては、検出力の値として0.8が適切であると考えることもあります。仮説検定の検出力が低い場合、実際には有意である差を検出できない可能性があります。サンプルサイズを大きくすると、検定の検出力も高くなります。適切な検出力を達成するには、サンプル内の観測値数が十分である必要があります。しかし、サンプルサイズを大きくしすぎて、不必要なサンプリングに時間と費用を浪費したり、統計的に有意な重要でない差を検出することは望ましくありません。検出する差のサイズを小さくすると、検出力も低くなります。
このグラフでは、サンプルサイズ25の検出力曲線は、13の比較率に対して検定の検出力が約0.84であることを示しています。サンプルサイズ30の検出力曲線は、13の比較率に対して検定の検出力が約0.9であることを示しています。比較率が仮説の率(このグラフでは15)に近づくにつれて、検定の検出力は低下し、α(有意水準とも呼ばれます)に近づきます。αはこの分析では0.05です。