差に対する検出力
出力の最初の行は、同等性検定に対してどのように仮説が指定されているかを示します。
「差に対する検出力」は、検定の母平均と参照母平均との差(検定平均 - 参照平均)に関して仮説が指定されていることを示します。
比に対する検出力
出力の最初の行は、同等性検定に対してどのように仮説が指定されているかを示します。
「比に対する検出力」は、対数変換による検定の母平均と参照母平均との比(検定平均 / 参照平均)に関して仮説が指定されていることを示します。
帰無仮説と対立仮説
- 帰無仮説
- Minitabでは、選択された対立仮説に応じて、以下の帰無仮説の一方または両方を検定します。
- 検定母集団の平均と参照母集団の平均の差(または比)は、上側同等性限界以上である。
- 検定母集団の平均と参照母集団の平均の差(または比)は、下側同等性限界以下である。
- 対立仮説
- 対立仮説は、以下のいずれかまたは両方です。
- 検定母集団の平均と参照母集団の平均の差(または比)は、下側同等性限界より小さい。
- 検定母集団の平均と参照母集団の平均の差(または比)は、下側同等性限界より大きい。
解釈
帰無仮説と対立仮説を使用して、同等性基準が正当で、検定する適切な対立仮説が選択されていることを確認します。
方法
| 差に対する検出力: | 検定する平均 - 基準平均 |
|---|---|
| 帰無仮説: | -0.425以下または0.425以上の差 |
| 対立仮説: | -0.425 < 差 < 0.425 |
| α水準: | 0.05 |
これらの結果では、2つの帰無仮説の検定を行っています。
- 検定の母平均と参照母平均との差は、下側同等性限界である0.425以下である。
- 検定の母平均と参照母平均との差は、上側同等性限界である0.425以上である。
α(アルファ)
有意水準(アルファまたはαと表されます)は、帰無仮説が真であるときにその帰無仮説を棄却する(タイプIの誤り)のリスクの最大許容水準です。たとえば、デフォルトの仮説を使用して同等性検定を実行する場合、0.05のαは、検定平均と参照平均の差が実際には同等性限界内にない場合に同等であると判断するリスクが5%であることを示します。
同等性検定のα水準により、信頼区間に対する信頼水準も決定されます。デフォルトでは、信頼水準は(1 – α) × 100%です。信頼区間の計算に代替方法を使用する場合、信頼水準は(1 – 2α) x 100%です。
解釈
有意水準を使用して、帰無仮説(H0)が真の場合の検定の検出力値を最小化します。有意水準の値が高いほど、検定の検出力が高くなりますが、真である帰無仮説を棄却してしまうタイプIの誤りを犯す可能性も高くなります。
仮定された被験者内標準偏差
被験者内標準偏差とは、同じ参加者からの複数の応答値の標準偏差のことです。この標準偏差の測度は、同じ参加者からの応答測定値から処理効果、時期効果、およびその他の系統的な効果を除外した後のランダム誤差の規模を推定するものです。値が高いほど、各参加者の応答値の変動性が高いことを示します。
解釈
差に関する同等性検定のための検出力分析を実行する場合、被験者内標準偏差を入力する必要があります。この仮定された被験者内標準偏差は、母標準偏差の推定値です。
Minitabでは、検定の検出力を計算するために、仮定された被験者内標準偏差が使用されます。被験者内標準偏差の値が高いほど、データの変動または「雑音」が大きいことを示し、検定の検出力は低くなります。
仮定された被験者内変動係数
被験者内変動係数とは、同じ参加者からの複数の応答値の変動係数のことです。変動係数は、標準偏差を平均で割ったものです。
この変動の測度は、同じ参加者からの応答測定値から処理効果、時期効果、およびその他の系統的な効果を除外した後のランダム誤差の規模を推定するものです。値が高いほど、各参加者の応答値の変動性が高いことを示します。
解釈
比に関する同等性検定のための検出力分析を実行する場合、被験者内変動係数を入力する必要があります。この仮定された被験者内変動係数は、母変動係数の推定値です。
Minitabでは、検定の検出力を計算するために、仮定された被験者内変動係数が使用されます。被験者内変動係数の値が高いほど、データの変動または「雑音」が大きいことを示し、検定の検出力は低くなります。
差
この値は、検定の母平均と参照母平均との差を表します。
注
このトピックでの定義および解釈は、デフォルトの対立仮説(下側限界 < 検定平均値 - 参照平均値 < 上側限界)を使用する標準同等性検定に適用されます。
解釈
サンプルサイズと検定の検出力を入力すると、指定した検出力とサンプルサイズで検定に使用できる差が計算されます。サンプルサイズを大きくするほど、差が同等性限界に近づきます。
サンプルサイズと、指定された検出力において検定で使用できる差の関係をより詳しく調べるには、検出力曲線を使用します。
方法
| 差に対する検出力: | 検定する平均 - 基準平均 |
|---|---|
| 帰無仮説: | -0.425以下または0.425以上の差 |
| 対立仮説: | -0.425 < 差 < 0.425 |
| α水準: | 0.05 |
結果
| サンプルサイズ | 検出力 | 差 |
|---|---|---|
| 4 | 0.9 | -0.278474 |
| 4 | 0.9 | 0.278474 |
| 8 | 0.9 | -0.329164 |
| 8 | 0.9 | 0.329164 |
| 12 | 0.9 | -0.348248 |
| 12 | 0.9 | 0.348248 |
これらの結果は、サンプルサイズが大きくなるにつれて、指定された検出力水準において使用できる差のサイズがどのように大きくなるかを示しています。
- 各系列に4人の参加者がいる場合、検定の検出力が0.9以上になるのは、差が約−0.278~0.278のときです。
- 各系列に8人の参加者がいる場合、検定の検出力が0.9以上になるのは、差が約−0.329~0.329のときです。
- 各系列に12人の参加者がいる場合、検定の検出力が0.9以上になるのは、差が約−0.348~0.348のときです。
比
この値は、参照母平均に対する検定の母平均の比を表します。比に対する検定力を計算するには、検定平均値 / 参照平均値 (比、対数変換を使用)に関する仮説を選択する必要があります。
注
このトピックでの定義および解釈は、比についてのデフォルトの対立仮説(下側限界 < 検定平均値 / 参照平均値 < 上側限界)を使用する同等性検定に適用されます。
解釈
サンプルサイズと検定の検出力を入力すると、指定した検出力とサンプルサイズで検定に使用できる最小比と最大比が計算されます。サンプルサイズを大きくするほど、比が同等性限界に近づきます。
サンプルサイズと、指定された検出力において検定で使用できる比の関係をより詳しく調べるには、検出力曲線を使用します。
方法
| 比に対する検出力: | 検定する平均 / 基準平均 |
|---|---|
| 帰無仮説: | 0.9以下または1.1以上の比 |
| 対立仮説: | 0.9 < 比 < 1.1 |
| α水準: | 0.05 |
結果
| サンプルサイズ | 検出力 | 比 |
|---|---|---|
| 10 | 0.9 | 0.91749 |
| 10 | 0.9 | 1.07903 |
| 20 | 0.9 | 0.91207 |
| 20 | 0.9 | 1.08544 |
これらの結果は、サンプルサイズが大きくなるにつれて、指定された検出力水準において検定で使用できる比の範囲がどのように大きくなるかを示しています。
- 各系列の観測値が10個ある場合、検定の検出力が0.9以上になるのは、比が約0.92~1.08のときです。
- 各系列の観測値が20個ある場合、検定の検出力が0.9以上になるのは、比が約0.91~1.09のときです。
サンプルサイズ
サンプルサイズとは、サンプルに含まれる観測値の合計数のことです。2x2交差分析の場合、サンプルサイズとは、分析の各系列の参加者数を指します。
解釈
サンプルサイズを使用して、同等性定検において、特定の差で特定の検出力値を得るために必要な観測値数を推定します。
検定での差(または比)と検出力値を入力すると、必要なサンプルサイズが計算されます。サンプルサイズは整数であるため、検定の実際の検出力は、指定した検出力値よりもわずかに大きくなる場合があります。
サンプルサイズを大きくすると、検定の検出力も高くなります。適切な検出力を達成するには、サンプル内の観測値数が十分である必要があります。しかし、サンプルサイズを大きくしすぎて、不必要なサンプリングに時間と費用を浪費したり、重要でない差が統計的に有意であることを検出することは望ましくありません。
サンプルサイズと、指定された検出力において検定で使用できる差(または比)の関係をより詳しく調べるには、検出力曲線を使用します。
方法
| 差に対する検出力: | 検定する平均 - 基準平均 |
|---|---|
| 帰無仮説: | -0.425以下または0.425以上の差 |
| 対立仮説: | -0.425 < 差 < 0.425 |
| α水準: | 0.05 |
結果
| 差 | サンプルサイズ | 目標検出力 | 実際の検出力 |
|---|---|---|---|
| 0.0 | 2 | 0.9 | 0.978589 |
| 0.1 | 2 | 0.9 | 0.931544 |
| 0.2 | 3 | 0.9 | 0.972795 |
| 0.3 | 6 | 0.9 | 0.943646 |
| 0.4 | 107 | 0.9 | 0.900500 |
これらの結果は、差のサイズが大きくなって同等性限界値に近づくにつれて、指定された検定力を達成するために、より大きなサンプルサイズが必要になることを示しています。差が0.1の場合、検出力0.9を達成するために必要な各連続の参加者は2人だけです。差が0.4の場合、検出力0.9を達成するには、各連続に107人以上の参加者が必要です。
検出力
同等性検定の検出力は、検定で差が同等性限界内にあることを示す確率です。同等性検定の検出力は、サンプルサイズ、差、同等性限界、データの変動性、検定の有意水準に影響されます。
詳細は、同等性検定の検出力を参照してください。
解釈
Minitabでは、サンプルサイズと差(割合)を入力すると、検定の検出力が計算されます。検出力は通常、0.9以上で十分だと考えられます。0.9の検出力とは、母平均の差(または割合)が実際に同等性限界内にある場合に、同等性を90%の確率で示すことができるということです。同等性検定の検出力が弱い場合、検定平均と参照平均が同等であっても、同等性を示すことができない可能性があります。
通常、サンプルサイズが小さいまたは差(または割合)が同等性限界に近いほど、検定の同等性を主張する検出力は弱くなります。
方法
| 差に対する検出力: | 検定する平均 - 基準平均 |
|---|---|
| 帰無仮説: | -0.425以下または0.425以上の差 |
| 対立仮説: | -0.425 < 差 < 0.425 |
| α水準: | 0.05 |
結果
| 差 | サンプルサイズ | 検出力 |
|---|---|---|
| 0.3 | 8 | 0.984946 |
| 0.3 | 12 | 0.999089 |
| 0.4 | 8 | 0.189487 |
| 0.4 | 12 | 0.244815 |
これらの結果において、差が0.3の場合、検定の検出力はサンプルサイズが8のときにおよそ0.98、サンプルサイズが15のときにおよそ0.99になっています。差が0.4の場合、検出力はサンプルサイズが8のときにおよそ0.19、サンプルサイズが12のときにおよそ0.24になっています。
検出力曲線
この検出力曲線では、検定の検出力に対して検定平均と参照平均の間の差がプロットされます。
解釈
検出力曲線を使用して、検定に適したサンプルサイズと検出力を評価します。
この検出力曲線は、有意水準と標準偏差(または変動係数)を一定に保って、各サンプルサイズに対する検出力と差(または比)のすべての組み合わせを表します。検出力曲線上の記号は、入力した値に基づいて計算された値を表します。たとえば、サンプルサイズと検出力の値を入力すると、それに対応する差(または比)が計算され、計算された値がグラフ上に表示されます。
曲線上の値を調べることにより、特定の検出力値とサンプルサイズにおいて使用できる検定平均と参照平均の差(または比)を決定できます。通常、検出力の値として0.9は適切であるとされます。ただし、分析者によっては、検出力の値として0.8が適切であると考えることもあります。同等性検定の検出力が低い場合、母集団平均が同等であるにもかかわらず、同等性を示すことができない可能性があります。サンプルサイズを大きくすると、検定の検出力も高くなります。適切な検出力を達成するには、サンプル内の観測値数が十分である必要があります。しかし、サンプルサイズを大きくしすぎて、不必要なサンプリングに時間と費用を浪費したり、統計的に有意な重要でない差を検出することは望ましくありません。通常、差(または比)が同等性限界に近くなるほど、同等性を示すために必要な検出力が高くなります。
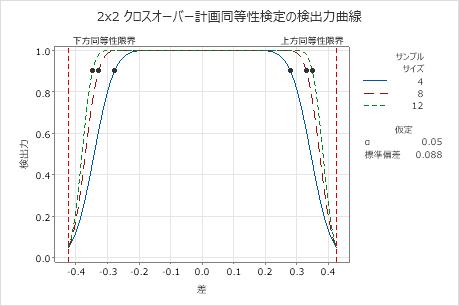
このグラフでは、すべてのサンプルサイズの検出力曲線は、約±0.25までの差に対して検定の検出力が適切(0.9以上)であることを示しています。サンプルサイズとは、各系列の参加者数を表します。サンプルサイズ4の検出力曲線は、約±0.28の差に対して検定の検出力が0.9であることを示しています。サンプルサイズ12の検出力曲線は、約±0.33の差に対して検定の検出力が0.9であることを示しています。サンプルサイズを12まで増やしても、検出力0.9で使用できる差はわずかに増加するだけであることに注目してください。各曲線において、差が下側同等性限界または上側同等性限界に近づくにつれて、検定の検出力は低下し、α(アルファ。同等でない場合に同等であるとするリスク)に近づきます。