サンプルはランダムである必要があります
ランダムサンプルとは、指定されたサイズのサンプルすべてが等しい確率で生じるようにするプロセスによって選択された母集団のサブセットです。統計では、ランダムサンプルを使用して母集団についての一般化または推定を行います。
ただし、母集団全体を正確に表すには、サンプルをランダムに収集する必要があります。サンプルがランダムになるように、データ収集の工程を慎重に計画する必要があります。さらに、工程またはデータを収集する母集団が安定している必要もあります。
選択の偏りをなくすために、サンプルはランダムである必要があります。選択の偏りとは、一部のサブジェクトが他のサブジェクトよりもサンプルに頻繁に現れることを意味します。サンプルが偏っている場合、母集団全体についてではなく、サンプルのサブジェクトについてしか推測を行うことができません。
新しい広告キャンペーンを立ち上げようと思いますが、顧客に訴える最善の媒体として、チラシ、ラジオ、またはテレビのどれを使用するか迷っているとします。顧客のすべてについて調査することは実用的な方法つまり費用対効果に優れた方法ではありませんが、ランダムサンプルで調査することは可能です。まず、割り戻し通知に返信してきた顧客のみを調査することにします。それらの顧客は、調査に応じる確率が高いからです。ただし、各顧客が選択される確率が均一ではないため、このサンプルは母集団全体を表してはいません。そのため、ビジネス上の意思決定を誤るおそれがあります。代わりに、全顧客のアルファベット順のリストから顧客をランダムに選択することを決定します。このデータからは、顧客ベースに関する推測を行い、広告費を割り当てる最適な方法を判断できます。
連検定を使用したサンプルがランダムであるかどうか判断する
データを収集した後で、データがランダムかどうかを確認する方法の1つとして、連検定を使用して時間の経過に伴うデータのパターンを調べます。Minitabで連検定を実行するには、を選択します。
その他のグラフでサンプルがランダムかどうかを識別することもできます。
時系列プロットを使用してデータがランダムでないことを判断する例
インタビュアがランダムに30名の人々を選出して、それぞれに4つの回答の選択肢のある質問をするとします。被験者を0、1、2、3とコード化します。インタビュアは時系列プロットを作成して回答のランダム性を確認します。
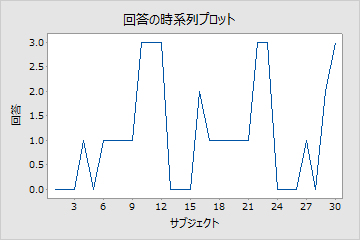
回答の時系列プロット
データのパターンは、データがランダムでないことを示しています。インタビュアは、質問の表現または被験者の選択に偏りがないかどうかを調べます。