帰無仮説と対立仮説
- 帰無仮説
- 帰無仮説では、すべてのデータ値が同じ正規分布から取得されたと仮定します。
- 対立仮説
- 対立仮説では、最小または最大のデータ値が外れ値であると仮定します。
有意水準
有意水準(αまたはアルファで示される)とは、帰無仮説が正しいにもかかわらず帰無仮説を棄却するリスク(第1種の過誤)の最大許容水準です。デフォルト値は0.05です。
解釈
有意水準を使用して、帰無仮説(H0)を棄却するか棄却できないかを決定します。ある事象が発生する確率が有意水準より低い場合、通常は、結果が統計的に有意であり、H0を棄却できると解釈します。
- 存在する可能性がある差がより確実に検出されるようにするには、0.10などの高い値の有意水準を選択します。たとえば、品質エンジニアが新しいボールベアリングの安定性を現行のベアリングの安定性と比較するとします。ボールベアリングが不安定だと大事故が発生する可能性があるため、エンジニアは、新しいボールベアリングの安定性について強い確信を持っている必要があります。この場合エンジニアは、ボールベアリングの安定性における潜在的な差がすべて確実に検出されるよう、有意水準として0.10を選択します。
- 実際に存在する差のみが確実に検出されるようにするには、0.01などの低い値の有意水準を選択します。たとえば、製薬会社の科学者は、会社の新薬によって症状が著しく緩和されるという主張について、非常に強い確信を持っている必要があります。この場合科学者は、症状における有意差が確かに存在することを示すため、有意水準として0.001を選択します。
N
サンプルサイズ(N)は、サンプルに含まれる観測値の総数です。
平均
平均値は、データの平均であり、すべての観測値の和を観測値の数で割って求められる値です。

解釈
データの中心を表す1つの値でサンプルを表すのに、平均を使います。多くの統計分析では、平均がデータ分布の中央の標準測度として使用されます。
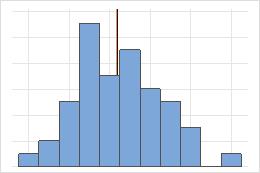
対称
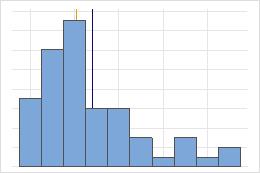
非対称
対称分布の場合、平均値(青い線)と中央値(オレンジ色の線)は非常によく似ているため、両方の線を簡単に確認することはできません。ただし、非対称分布は右側に歪んでいます。
標準偏差
標準偏差とは、散布度、つまり平均を中心としたデータの広がり方を表す最も一般的な測度です。記号σ(シグマ)は、母集団の標準偏差を示す場合によく使用されますが、sはサンプルの標準偏差を示す場合にも使用されます。多くの場合、工程に対してランダム(自然)な変動は雑音と呼ばれます。
標準偏差の単位はデータの単位と同じであるため、通常は、分散よりも解釈が簡単です。
解釈
標準偏差を使用して、平均からのデータの拡散程度を判断します。 標準偏差の値が高いほど、データの広がりが大きいことを示します。 正規分布の経験則によれば、値のおよそ68%が平均の1つの標準偏差の範囲内にあり、値の95%が2つの標準偏差の範囲内にあり、値の99.7%が3つの標準偏差の範囲内にあります。
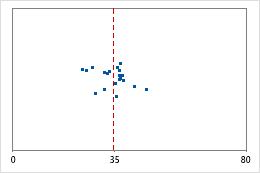
病院1

病院2
退院時間
管理者が、2つの病院の救急部門で処置を受けた患者の退院時間を追跡するとします。平均退院時間はほぼ同じ(35分)ですが、標準偏差には有意差があります。病院1の標準偏差はおよそ6です。平均すると、患者の退院時間は平均(点線)から約6分離れています。病院2の標準偏差はおよそ20です。平均すると、患者の退院時間は平均(点線)から約20分離れることになります。
最大値
最大値とは、最大のデータ値を指します。
このデータで、最大値は19です。
| 13 | 17 | 18 | 19 | 12 | 10 | 7 | 9 | 14 |
解釈
最大値を使用して、外れ値の可能性がある値またはデータ入力ミスを識別します。データの広がりを最も簡単に評価する方法の1つは、最小値と最大値を比較することです。データの中心、広がり、形状を検討する場合であっても、最大値が非常に大きい場合、極端な値の原因を調査してください。
最小値
最小値とは、最小のデータ値を指します。
このデータで、最小値は7です。
| 13 | 17 | 18 | 19 | 12 | 10 | 7 | 9 | 14 |
解釈
最小値を使用して、外れ値の可能性がある値またはデータ入力ミスを識別します。データの広がりを最も簡単に評価する方法の1つは、最小値と最大値を比較することです。データの中心、広がり、形状を検討する場合であっても、最小値が非常に小さい場合、極端な値の原因を調査してください。
外れ値
外れ値とは、異常に大きいまたは小さい観測値を指します。外れ値の原因を特定する必要があります。データ入力や測定の誤差を修正します。異常な1回きりの事象(特別原因)のデータ値は除外することを検討します。
行
外れ値が含まれるワークシートの行。この値は、外れ値が存在する場合のみ表示されます。
x[i]とx[N-i]
Dixonの比検定を使用する場合、Minitabでは検定表に最小値と最大値の他にいくつかの観測値が表示されます。角括弧で囲まれた値は、他の値に関連した観測値のサイズを示しています。たとえば、x[2]は2番目に小さい観測値であることを示し、x[N-1]は2番目に大きい観測値であることを示します。
G
Grubbsの検定統計量(G)とは、サンプル平均と最小または最大のデータ値の差を標準偏差で割ったものです。MinitabはGrubbsの検定統計量を使用してp値を計算します。p値とは、帰無仮説が真であるにもかかわらず帰無仮説を棄却する確率を指します。
P
p値は帰無仮説を棄却するための証拠を測定する確率です。p値が小さいほど、帰無仮説を棄却するための強力な証拠となります。
解釈
p値を使用して、外れ値が存在するかどうかを判断します。
- P値 ≤ α: 外れ値が存在します(H0を棄却する)
- p値が有意水準以下の場合は、帰無仮説を棄却する決定を下し、外れ値が存在すると結論付けます。外れ値がある場合は、その原因を特定します。データ入力誤差や測定誤差はすべて修正します。異常な1回だけの事象(特殊原因)に関連付けられたデータ値を除外することを検討してください。
- P値 > α: 外れ値が存在すると結論付けることはできません(H0を棄却しない)
- p値が有意水準値より大きい場合は、外れ値が存在すると結論付けるだけの十分な証拠がないため、帰無仮説を棄却しない決定を下します。外れ値を検出するのに十分な検出力が検定にあることを確認してください。詳細は、検出力の増加を参照してください。
外れ値プロット
外れ値プロットは個別値プロットに似ています。外れ値プロットを使用して、データ内の外れ値を視覚的に識別します。 外れ値が存在する場合は、プロットに赤い四角で表示されます。 外れ値の原因を特定する必要があります。データ入力や測定の誤差を修正します。異常な1回きりの事象(特別原因)のデータ値は除外することを検討します。
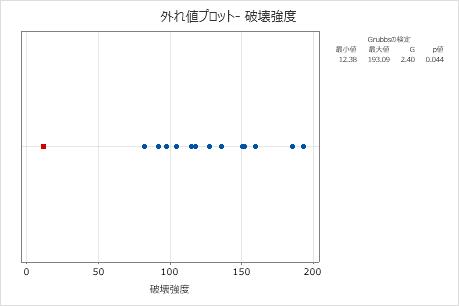
この結果で、最小値12.38は外れ値です。