平均
一連の数字の中心として一般的に使用される測度。平均は平均値とも呼ばれます。これは、すべての観測値の和を(非欠損)観測値数で割ったものです。
計算式
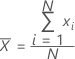
表記
| 用語 | 説明 |
|---|---|
| xi | i番目の観測値 |
| N | 非欠損観測値の数 |
標準偏差
サンプルの標準偏差により、データの広がりの測度が得られます。サンプル分散の平方根に等しくなります。
計算式
 の場合、サンプルの標準偏差は次のようになります。
の場合、サンプルの標準偏差は次のようになります。

表記
| 用語 | 説明 |
|---|---|
| x i | i番目の観測値 |
 | 観測値の平均 |
| N | 非欠損観測値の数 |
N
Anderson-Darling
A2は、(選択分布に基づいた)適合線と(プロット点に基づいた)ノンパラメトリックステップ関数の間のエリアを示します。この統計量は、分布の裾の方が重みの大きい二乗距離です。Anderson-Darlingの値が小さい場合、分布がデータにより良くあてはまることを示します。
Anderson-Darling正規性検定は次のように定義されます。
H0: データは正規分布に従う
H1: データは正規分布に従わない
計算式

正規性検定の結果をレポートするためのもう1つの定量的な測度はp値です。p値が小さいことは帰無仮説が偽であることを示します。

- もしA'2 > 13 > 0.600 ならば、p = exp(1.2937 - 5.709 *A'2 + 0.0186(A'2)2)
- もし0.600>A'2 >0.340ならp = exp(0.9177 - 4.279 *A'2 – 1.38(A'2)2)
- もし0.340>A'2 >0.200なら、p = 1 – exp(–8.318 + 42.796 *A'2 – 59.938(A'2)2)
- もしA'2 <0.200 then p = 1 – exp(–13.436 + 101.14 * A'2 – 223.73(A'2)2)
表記
| 用語 | 説明 |
|---|---|
| F(Yi) |  、これは標準正規分布の累積分布関数です 、これは標準正規分布の累積分布関数です |
| Yi | 順序付きデータ |
Ryan-Joiner
ライアン・ジョイナー検定は相関係数を提供し、データとデータのオーダー統計量の正規スコアとの相関を示します。相関係数が1に近い場合、データは正規確率プロットに近くなります。適切な棄却限界値より小さい場合、正規性の帰無仮説を棄却します。
計算式
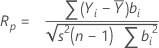

- もし n ≥ 50
-
- もし n ならば < 50
-
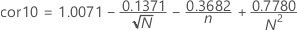





- Rp > cor10ならば p > 0.10。
- cor05 < Rp ≤ cor10ならば:

- cor01 < Rp ≤ cor05ならば:

- Rp ≤ cor01なら、 p < 0.01.
表記
| 用語 | 説明 |
|---|---|
| Yi | 順序付き観測値 |
| bi | 順序統計の正規スコア |
| s 2 | サンプル分散 |
| n | サンプルサイズ |
| i | 順序付けデータの順位 |
Kolmogorov-Smirnov
計算式
- H0: データは正規分布に従う
- H1: データは正規分布に従わない

p値を決定するために、Minitabはサンプルサイズ(n)を考慮した調整統計量(d*)を使用します。

d* を以下の臨界値と比較してp値を決定します。
- d* < 0.775, ならばp >0.15
- 0.775≤ d* < 0.819, tならば:
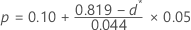
- 0.819≤ d* < 0.895, tならば:

- 0.895≤ d* < 0.995, tならば:

- 0.995≤ d* < 1.035, tならば:
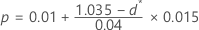
- d* ≥1.03ならば p < 0.01.
表記
| 用語 | 説明 |
|---|---|
| D+ | maxi {i / n – Z (i)} |
| D– | maxi {Z (i) – (I – 1) / n)} |
| Z | F(X(i)) |
| F(x) | 正規分布の確率分布関数 |
| X(i) | iは ランダムサンプルの統計量を1≤ i ≤ n の順序です |
| n | サンプルサイズ |
プロット点
一般に、点の位置が適合線に近ければ、適合度が高いといえます。Minitabでは、2つの適合度の測度を利用して、データへの分布の適合度を評価することができます。
計算式
| 分布 | x座標 | y座標 |
|---|---|---|
| 正規 | x | Φ–1 norm |
表記
| 用語 | 説明 |
|---|---|
| Φ–1 norm | 標準正規分布の逆累積分布関数によってpに返される値 |
確率プロット
入力データはx値としてプロットされます。Minitabは、分布を仮定せずに出現の確率を計算します。グラフのYスケールは、データが正規分布になっていると、確率プロットが直線になる正規確率紙のYスケールに似ています。