正規性検定を解釈するには、次の手順を実行します。主要な結果には、p値、確率プロットが含まれます。
ステップ1: データが正規分布に従わないかどうかを判断する
データが正規分布に従わないかどうかを判断するには、p値を有意水準と比較します。通常は、有意水準(αまたはアルファとも呼ばれる)として0.05が適切です。有意水準が0.05の場合は、データが確かに正規分布に従うときに、そのデータは正規分布に従わないと結論付けるリスクが5%あることを示します。
- p値 ≤ α: データは正規分布に従いません(H0を棄却する)
- p値が有意水準以下の場合は、帰無仮説を棄却する決定を下し、データは正規分布に従わないと結論付けます。
- p値 > α: データは正規分布に従わないと結論付けることはできません(H0を棄却しない)
- p値が有意水準よりも大きい場合は、帰無仮説を棄却しない決定を下します。データは正規分布に従わないと結論付けるだけの十分な証拠はありません。
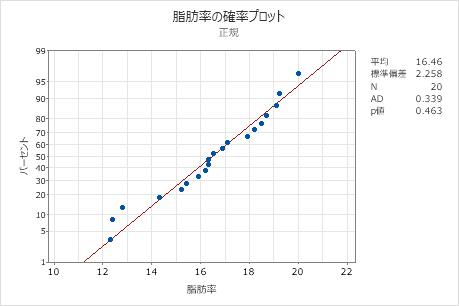
主要な結果: p値
この結果で、帰無仮説では、データが正規分布に従うと仮定します。p値が0.463で、有意水準0.05より大きいため帰無仮説を棄却できません。データが正規分布に従わないと結論付けることはできません。
ステップ2: 正規分布の適合性を視覚化する
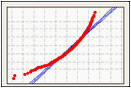
正規分布の適合度を視覚化するには、確率プロットを調べて、データ点が適合分布線にどの程度近いかを評価します。正規分布は、ほぼ直線になる傾向にあります。歪んだデータは曲線になります。
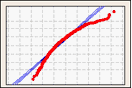
右方向に歪んだデータ
左方向に歪んだデータ
ヒント
Minitabでは、適合分布線の上にポインタを置くと、百分位数と値の図が表示されます。
この確率プロットで、データは近似的に線に沿った直線になっています。正規分布はデータに良く当てはまっているように見えます。