このトピックの内容
Anderson-Darling統計量 (A2)
A2は、(選択分布に基づいた)適合線と(プロット点に基づいた)ノンパラメトリックステップ関数の間のエリアを示します。この統計量は、分布の裾の方が重みの大きい二乗距離です。Anderson-Darlingの値が小さい場合、分布がデータにより良くあてはまることを示します。
Anderson-Darling正規性検定は次のように定義されます。
H0: データは正規分布に従う
H1: データは正規分布に従わない
計算式

表記
| 用語 | 説明 |
|---|---|
| F(Yi) |  、これは標準正規分布の累積分布関数です 、これは標準正規分布の累積分布関数です |
| Yi | 順序付きデータ |
Anderson-Darling正規性検定のp値
Anderson-Darling正規性検定の結果を報告するための定量的な測度はp値です。p値が小さい場合、帰無仮説が誤っていることを示します。
A 2がわかっている場合、p値を計算できます。
次のように定義します。
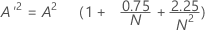
- 13 > A'2 > 0.600の場合は、p = exp(1.2937 - 5.709 * A'2 + 0.0186(A'2)2)
- 0.600 > A'2 > 0.340の場合は、p = exp(0.9177 - 4.279 * A'2 – 1.38(A'2)2)
- 0.340 > A'2 > 0.200の場合は、p = 1 – exp(–8.318 + 42.796 * A'2 – 59.938(A'2)2)
- A'2 < 0.200の場合は、p = 1 – exp(–13.436 + 101.14 * A'2 – 223.73(A'2)2)
非欠損値の数(N)
サンプルにおける非欠損値の数。
標準偏差
サンプルの標準偏差により、データの広がりの測度が得られます。サンプル分散の平方根に等しくなります。
計算式
 の場合、サンプルの標準偏差は次のようになります。
の場合、サンプルの標準偏差は次のようになります。

表記
| 用語 | 説明 |
|---|---|
| x i | i番目の観測値 |
 | 観測値の平均 |
| N | 非欠損観測値の数 |
分散
分散は、平均を中心としたデータの広がり方を測定します。分散は、標準偏差の二乗に等しくなります。
計算式
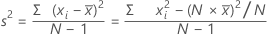
表記
| 用語 | 説明 |
|---|---|
| xi | i番目の観測値 |
 | 観測値の平均 |
| N | 非欠損観測値の数 |
歪度
歪度は、非対称性の測度です。負の値は左に歪んでいることを示し、正の値は右に歪んでいることを示します。0の値は対称を示しているとは限りません。
計算式
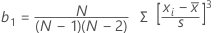
表記
| 用語 | 説明 |
|---|---|
| xi | i番目の観測値 |
 | 観測値の平均 |
| N | 非欠損観測値の数 |
| s | サンプルの標準偏差 |
尖度
尖度は、分布が正規分布からどれだけ異なっているかを示す測度の1つです。正の値は、通常、分布に正規分布と比べて鋭いピークがあることを示します。負の値は、分布に正規分布と比べて平坦なピークがあることを示します。
計算式

表記
| 用語 | 説明 |
|---|---|
| xi | i番目の観測値 |
 | 観測値の平均 |
| N | 非欠損観測値の数 |
| s | サンプルの標準偏差 |
平均
一連の数字の中心として一般的に使用される測度。平均は平均値とも呼ばれます。これは、すべての観測値の和を(非欠損)観測値数で割ったものです。
計算式
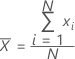
表記
| 用語 | 説明 |
|---|---|
| xi | i番目の観測値 |
| N | 非欠損観測値の数 |
最小値
データセットにおける最小の値。
最大値
データセットにおける最大の値。
第1四分位数(Q1)
サンプル観測値の25%が第1四分位数の値以下になります。そのため、第1四分位数は第25百分位数とも呼ばれます。
計算式

表記
| 用語 | 説明 |
|---|---|
| y | wの切り捨てた整数値 |
| w | 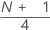 |
| z | 切り捨てられたwの小数部分 |
| xj | サンプルデータを最小から最大の順に並べたリストのj番目の観測値 |
注
wが整数の場合、y = w、z = 0、Q1 = xyになります。
中央値
サンプル中央値は、データの中央にあります。観測値の少なくとも半分は中央値以下、少なくとも半分は中央値以上になります。
N個の値がある列があるとします。中央値を計算するには、最初にデータ値を最小から最大の順に並べます。Nが奇数の場合は、サンプル中央値は中央にある値です。Nが偶数の場合は、サンプル中央値は中央の2つの値の平均です。
たとえば、N = 5でデータx1、x2、x3、x4、およびx5がある場合、中央値 = x3です。
N = 6で順序付きデータx1、x2、x3、x4、x5、およびx6がある場合、次のようになります。

ここで、x3とx4は3番目と4番目の観測値です。
第3四分位数(Q3)
サンプル観測値の75%が第3四分位数の値以下になります。そのため、第3四分位数は第75百分位数とも呼ばれます。
計算式

表記
| 用語 | 説明 |
|---|---|
| y | wの切り捨てた値 |
| w |
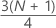 |
| z | 切り捨てられたwの小数部分 |
| xj | サンプルデータを最小から最大の順に並べたリストのj番目の観測値 |
注
wが整数の場合、y = w、z = 0、Q3 = xyになります。
平均の信頼区間
計算式

表記
| 用語 | 説明 |
|---|---|
 | 平均 |
| s | サンプルの標準偏差 |
| N | 非欠損値の数 |
| t N, α | 1 – α / 2における自由度N – 1のt分布の逆累積確率(α = 1 – 信頼水準 / 100) |
中央値の信頼区間
Minitabは、真の中央値の信頼区間を計算するために非線形補間法を使用します1。この方法は、正規分布、Cauchy分布、一様分布を含む幅広い対称な分布の非常に優れた近似となります。非対称な分布の例では、必ず線形補間法よりもかなり正確な結果が十分に示されます。
標準偏差の信頼区間
Minitabは、母標準偏差σの(1 – α) 100%信頼区間を計算します。信頼区間は、データが正規であるという前提に対して非常に敏感です。正規性からの偏差が小さくても、信頼区間は誤解を招く場合があります。
計算式
信頼区間は次のように計算されます。
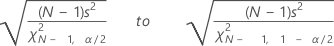
表記
| 用語 | 説明 |
|---|---|
| s | 標準偏差 |
| N | 非欠損値の数 |
| χ2N, α | 1 – α / 2における自由度Nのχ2の逆累積確率(α = 1 – 信頼水準 / 100) |