平均
ポアソン平均は、各カテゴリの合計にそのカテゴリでの観測値の数を乗算してから、観測値の合計数で除算した値です。
N
サンプルにおける非欠損値の数。
| 合計数 | N | N* |
|---|---|---|
| 149 | 141 | 8 |
N*
サンプルにおける欠損値の数。欠損値の数は、欠損値記号*を含むセルを参照します。
| 合計数 | N | N* |
|---|---|---|
| 149 | 141 | 8 |
ポアソン確率分布
データがポアソン分布に従い、平均がデータから計算されるポアソン平均に等しいことを前提とした、各カテゴリの確率。Minitabは、ポアソン確率を使用して期待値を計算します。
観測値と期待値
観測値とは、カテゴリに属するサンプル内の実際の観測値の数です。
期待値とは、ポアソン確率が真の場合に期待される観測値の数です。Minitabは、各カテゴリのポアソン確率に総サンプルサイズを掛けることで、期待度数を計算します。
カテゴリの期待度数(期待頻度)が5より小さい場合は、検定の結果が正しくない可能性があります。カテゴリの期待度数が低すぎる場合、最小限の期待度数を得るために、隣接するカテゴリと結合できることもあります。
たとえば、ある財務部門では、請求の延滞日数を分類するために、15日以下、16~30日、31~45日、46~60日、61日以上の5つのカテゴリを設定しているとします。61日以上のカテゴリの期待度数が小さいため、財務部門では、これを46~60日のカテゴリと組み合わせて46日以上のカテゴリを作成します。
解釈
観測値と期待値は、出力表または棒グラフを使用して比較できます。観測値と期待値の差が大きい場合、データがポアソン分布に従わないことを示します。
方法
| 観測値の度数 |
|---|
記述統計量
| N | 平均 |
|---|---|
| 300 | 0.536667 |
欠陥数に対する観測度数と期待度数
| 欠陥数 | ポアソン確率分布 | 観測度数 | 期待度数 | カイ二乗への寄与度 |
|---|---|---|---|---|
| 0 | 0.584694 | 213 | 175.408 | 8.056 |
| 1 | 0.313786 | 41 | 94.136 | 29.993 |
| 2 | 0.084199 | 18 | 25.260 | 2.086 |
| >=3 | 0.017321 | 28 | 5.196 | 100.072 |
カイ二乗検定
| 帰無仮説 | H₀: データはポアソン分布に従っている |
|---|---|
| 対立仮説 | H₁: データはポアソン分布に従っていない |
| 自由度 | カイ二乗 | p値 |
|---|---|---|
| 2 | 140.208 | 0.000 |
カイ二乗への寄与度
合計のカイ二乗統計量のうちどれだけが各カテゴリの相違に起因するかを定量化するには、個別のカテゴリの寄与度を使用します。
Minitabでは、各カテゴリのカイ二乗統計量への寄与度が、そのカテゴリの期待値で割った、カテゴリの観測値と期待値の差の平方として計算されます。カイ二乗統計量はすべてのカテゴリのこれらの値の和です。
解釈
観測値と期待値の差が大きいカテゴリは、全体のカイ二乗統計量への寄与度が大きくなります。
方法
| 観測値の度数 |
|---|
記述統計量
| N | 平均 |
|---|---|
| 300 | 0.536667 |
欠陥数に対する観測度数と期待度数
| 欠陥数 | ポアソン確率分布 | 観測度数 | 期待度数 | カイ二乗への寄与度 |
|---|---|---|---|---|
| 0 | 0.584694 | 213 | 175.408 | 8.056 |
| 1 | 0.313786 | 41 | 94.136 | 29.993 |
| 2 | 0.084199 | 18 | 25.260 | 2.086 |
| >=3 | 0.017321 | 28 | 5.196 | 100.072 |
カイ二乗検定
| 帰無仮説 | H₀: データはポアソン分布に従っている |
|---|---|
| 対立仮説 | H₁: データはポアソン分布に従っていない |
| 自由度 | カイ二乗 | p値 |
|---|---|---|
| 2 | 140.208 | 0.000 |
この結果で、各カテゴリのカイ二乗値の和が全体のカイ二乗統計量である140.208となります。寄与度が最大となっているのは、欠陥が3個以上のカテゴリです。この結果は、観測度数と期待度数の差が最大となるのは、欠陥が3個以上のカテゴリであることを示しています。観測度数と期待度数の差が最小となるのは、欠陥の数が2個のカテゴリです。
帰無仮説と対立仮説
- 帰無仮説
- 帰無仮説では母集団が特定の分布に従うと仮定します。帰無仮説とは多くの場合、前回の分析や専門知識を基にした最初の主張を指します。
- 対立仮説
- 対立仮説では、母集団が特定の分布に従わないと仮定します。
自由度
自由度(DF)とは、統計に関する独立した情報の数です。ポアソンの適合度検定の自由度は、カテゴリ数 – 2となります。
解釈
Minitabは、自由度を使用して検定統計量を判断します。分析に使用するカテゴリの数が多いほど、自由度が高くなります。
カイ二乗
カイ二乗統計量はサンプルデータの分布と期待されるポアソン分布との間の逸脱量を測定する検定統計量です。
解釈
そのカイ二乗統計量を使用して、帰無仮説を棄却するかどうかを判断できます。とはいえ、解釈するのが容易なため、p値のほうが頻繁に使用されます。p値は、データがポアソン分布に従う場合に、サンプルから計算された値と同程度以上の極端な検定統計量(カイ二乗統計量など)が得られる確率です。
帰無仮説を棄却するかどうかを判断するには、カイ二乗統計量を棄却限界値と比較します。カイ二乗統計量が棄却限界値より大きい場合、帰無仮説を棄却します。Z値の絶対値が棄却値より大きい場合、帰無仮説を棄却します。Minitabで棄却限界値を計算することも、ほとんどの統計に関する書籍に掲載されているカイ二乗分布表で棄却限界値を見つけることもできます。詳細は、逆累積分布関数(ICDF)の使用に進み、「ICDFを使用して重要な値を計算」をクリックします。
Minitabでは、カイ二乗統計量を使用してp値を計算します。
p値
p値は帰無仮説を棄却するための証拠を測定する確率です。p値が小さいほど、帰無仮説を棄却するための強力な証拠となります。
解釈
p値を使用して、データがポアソン分布に従わないかどうかを判断します。
- p値 ≤ α: データはポアソン分布に従いません(H0を棄却する)
- p値が有意水準以下の場合は、帰無仮説を棄却する決定を下し、データはポアソン分布に従わないと結論付けます。
- p値 > α: データはポアソン分布に従わないと結論付けることはできません(H0を棄却しない)
- p値が有意水準より大きい場合は、データはポアソン分布に従わないと結論付けるだけの十分な証拠がないため、帰無仮説を棄却しない決定を下します。
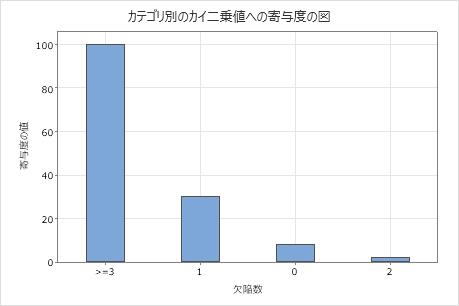
カテゴリ別のカイ二乗値への寄与度の図
この棒グラフでは、各カテゴリのカイ二乗統計量への寄与度をプロットしています。寄与度が最大のものから最小のものへカテゴリを並べる図を選択できます。
解釈
観測値と期待値の差が大きいカテゴリは、全体のカイ二乗統計量への寄与度が大きくなります。
この棒グラフは、期待値と観測値の差が最大となるのは、欠陥が3個以上のカテゴリであることを示しています。
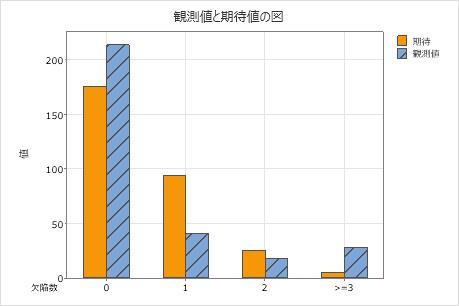
観測値と期待値の図
観測値と期待値の棒グラフを使用して、各カテゴリで観測値数が期待値数と異なるかどうかを判断します。観測値と期待値の差が大きい場合は、データがポアソン分布に従っていないことを意味します。
この棒グラフは、欠陥数が0、1、および3を超える場合の観測値が期待値と異なることを示してします。したがって、データがポアソン分布に従っていないとp値が示していることを棒グラフで視覚的に確認できます。