目的の方法または計算式を選択してください。
このトピックの内容
信頼区間(CI)
計算式
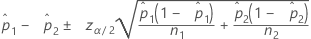
表記
| 用語 | 説明 |
|---|---|
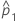 | 第1母集団比率の推定値 |
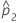 | 第2母集団比率の推定値 |
| n1 | 第1サンプルでの試行回数 |
| n2 | 第2サンプルでの試行回数 |
| zα/2 | 1 – α/2における標準正規分布の逆累積確率 |
| α | 1 – 信頼水準/100 |
正規近似検定
検定統計量Zの計算は、pを推定するために使用する方法によって異なります。
- pの個別の推定値
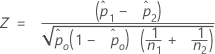
- デフォルトでは、Minitabは各母集団についてpの個別の推定値を使用し、Zを次のように計算します。
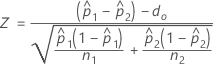
- pの併合推定値
- 仮定した検定する差が0で、検定についてpの併合推定値を使用することを選択した場合、MinitabはZを次のように計算します。
各対立仮説のp値は次のようになります。
- H1: p1 > p2 : p値 = P(Z1 ≥ z)
- H1: p1 < p2 : p値 = P(Z1 ≤ z)
- H1: p1 ≠ p2 : p値 = 2P(Z1 ≥ z)
標準正規分布でこれらの確率を計算します。
表記
| 用語 | 説明 |
|---|---|
| p1 | 第1母集団での事象の真の比率 |
| p2 | 第2母集団での事象の真の比率 |
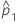 | 第1サンプルでの事象の観測された比率 |
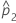 | 第2サンプルでの事象の観測された比率 |
| n1 | 第1サンプルでの試行回数 |
| n2 | 第2サンプルでの試行回数 |
| d0 | 第1と第2の比率間の仮説差 |
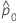 | 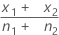 |
| x1 | 第1サンプルでの事象数 |
| x2 | 第2サンプルでの事象数 |
Fisherの正確検定
Minitabは、正規近似に基づいた検定に加えて、Fisherの正確検定を実行します。Fisherの正確検定はすべてのサンプルサイズで有効です。
計算式
この帰無仮説では、第1サンプルの事象数(x1)は次のパラメータを持つ超幾何分布になっています。
- 母集団サイズ = n1 + n2
- 母集団での事象数 = x1 + x2
- サンプルサイズ = n1
f( )とF( )はそれぞれ、この超幾何分布のPDFとCDFを示すとします。Modeはその最頻値を示すとします。各対立仮説のp値は次のようになります。
- H1: p1 < p2
p値 = F(x1)
- H1: p1 > p2
p値 = 1 – F(x1 – 1)
- H1: p1 ≠ p2
3つのケースが存在します。
- ケース1: x1 < Mode
p値 = p-lower + p-upper
用語 説明 p-lower F(x1) p-upper 1 – F(y – 1) y 最小の整数 > Mode、したがってf(y) <f(x1) 注
p-upperは0に等しい場合もあります。
- ケース2: x1 = Mode
p値 = 1.0
- ケース3: x1 > Mode
p値 = p-lower + p-upper
用語 説明 p-upper 1 – F(x1 – 1) p-lower F(y) y 最大の整数 < Mode、f(y) < f(x1) 注
p-lowerは0に等しい場合もあります。
- ケース1: x1 < Mode
表記
| 用語 | 説明 |
|---|---|
| p1 | 第1母集団での事象の真の比率 |
| p2 | 第2母集団での事象の真の比率 |
| x1 | 第1サンプルでの事象数 |
| x2 | 第2サンプルでの事象数 |
| n1 | 第1サンプルでの試行回数 |
| n2 | 第2サンプルでの試行回数 |