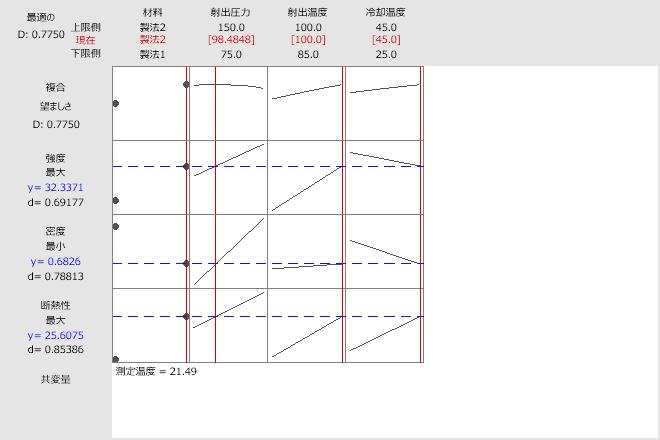
最適化プロット
最適化プロットでは、どの程度変数が予測応答に影響を与えるかを示します。最適化プロットが対話モードになると、セルには、対応する応答変数または複合的な望ましさが、その他のすべての変数が固定のままなのに対して、変数の1つの関数としてどの程度変化するかが表示されます。最適化プロットには予測変数設定の適合値が表示されます。
- 各変数(予測変数)の列
- グラフに引かれた垂直な赤い線は、現在の設定を表しています。
- 各応答変数の行。
- 水平な青い線は、現在の応答値を表しています。
- 複合的な望ましさ
- 上の行と左上隅にあるのは、複合的な望ましさ(D)です。
- 対話用のツールバー
- 現在の変数設定の予測を計算するツールバーの左上にある「予測」ボタン。
Minitabが表示する適合値の種類は、モデル内の応答変数の種類によって変わります。たとえば、Minitabでは、連続測定またはカウント測定、バイナリデータ、または 変動性の分析を使用するモデルがあるかどうかに応じて、平均、確率、または標準偏差が表示されます。
- 統計
- 最適化プロットをダブルクリックして対話モードに変更します。
- 予測分析モジュール
- プロットは常にインタラクティブです。
解釈
最適化プロットを使用して、指定したパラメータを条件とする予測変数の最適な設定を決定します。
- 材料:この列の各セルの 2 つの点は、カテゴリ変数の 2 つのレベルを表します。Formula1とFormula2。ここでは、製法2が最適材料であるように見えます。製法1に変更すると断熱度が下がり密度が上がってしまい、これはどちらも好ましくない変化です。ただし、材料は他の因子と交互作用があるため、この傾向は他の設定では見られないかもしれません。製法1の局所解が求められるかを検討してください。または、垂直バーを移動することで、グラフの製法1の設定値を直接変更することもできます。
- インジプレス: 射出圧力を上げると、3つの応答すべてが増加します。したがって、最適設定は因子水準範囲の中間にし(98.4848)、拮抗し合う各目的に対する妥協案とします。目標は、断熱度を最大化し、密度を最小化し、強度を最大にすることです。
- InjTemp: 射出温度を上げると、すべての応答も増加します。しかし、密度に対する効果は、断熱度に対する効果に比べてごくわずかです。このため、複合的な望ましさは射出温度を最大化することにより高めることができます。射出温度の最適設定は、実験での最大水準であることがわかります。この結果から、より高い温度で実験を行うべきであるということが示されます。
- クールテンプ: 冷却温度を上げると絶縁値は増加しますが、密度と強度の両方が低下します。射出温度と冷却温度の最適設定は、どちらも実験での最大水準になります。この結果から、より高い温度で実験を行うべきであるということが示されます。グラフからは、特に冷却温度を上げることは検討する価値があることがわかります。グラフの外挿が可能であれば、より高い冷却温度で断熱度と密度が改善される可能性もあります。ただし、強度は下がります。
線形回帰モデルの場合、予測区間を調べて、単一の将来値の予想値の範囲がプロセスの許容範囲内にあるかどうかを判断します。灰色の領域は、対応する応答の望特性が0となる場所を示します。
パラメータ
Minitabでは、各応答についての計画パラメータがパラメータ表に表示されます。これらの結果を確認して、表示された計画パラメータが正しいかどうか検証する必要があります。
計画について到達点、下限、目標、上限、および重みを選択すると、各応答の満足関数が定義されます。重要度パラメータは、満足関数が単一の複合的な望ましさの値に統合される方法を決定します。
解釈
- 強度の到達点は、強度の最大化です。38.1821の値は優れていると見なされ、19.2189未満の値は不可と見なされます。
- 密度の到達点は、密度の最小化です。0.4351の値は優れていると見なされ、1.60314以上の値は不可と見なされます。
- 断熱度の到達点は、断熱度の最大化です。27.7156の値は優れていると見なされ、13.2905未満の値は不可と見なされます。
すべての3つの応答の重要度は同じ値です。したがって、すべての3つの応答の複合的な望ましさへの影響は等しいです。
複数応答予測
| 変数 | 設定 |
|---|---|
| 材料 | 製法2 |
| 射出圧力 | 98.4848 |
| 射出温度 | 100 |
| 冷却温度 | 45 |
| 測定温度 | 21.4875 |
| 応答 | 適合値 | 適合値の標準誤差 | 95%信頼区間 | 95%予測区間 |
|---|---|---|---|---|
| 強度 | 32.34 | 1.04 | (29.45, 35.22) | (27.25, 37.43) |
| 密度 | 0.6826 | 0.0597 | (0.5167, 0.8484) | (0.3899, 0.9753) |
| 断熱性 | 25.608 | 0.268 | (24.863, 26.352) | (24.294, 26.921) |
応答予測
Minitabは、この表の変数設定を使用して、最適化手順に含まれる応答のすべての適合値を計算します。
応答の最適化機能を初めて実行すると、アルゴリズムが識別する最適な値が多重応答予測テーブルに表示されます。グラフの変数設定を変更し、ツールバーの 予測する ボタンをクリックすると、Minitabは新しい設定で表を作成します。
この表を使って、目的の分析が行われたかどうかを検証してください。
適合値(Fit)
適合する値は、適合値または . 適合値は、予測変数の値の平均応答の点推定です。予測変数の値は、X値とも呼ばれます。Minitabは回帰式と変数設定を使用して、適合値を計算します。
. 適合値は、予測変数の値の平均応答の点推定です。予測変数の値は、X値とも呼ばれます。Minitabは回帰式と変数設定を使用して、適合値を計算します。
Minitabに表示される適合値の種類は、モデル内の応答変数の種類によって変わります。たとえば、Minitabには、連続測定値または計数測定値、2値データ、または変動性の分析を使用するモデルのどれがあるのかによって、平均、確率、または標準偏差が表示されます。
解釈
適合値は、X値を応答変数のモデル式に入力することで計算されます。
たとえば、式がy = 5 + 10xの場合に、X値が2ならば、適合値は25(25 = 5 + 10(2))となります。
適合値の標準誤差(SE Fit)
適合値の標準誤差(SE Fit)は、特定の変数設定について推定される平均応答の変動を推定します。平均応答の信頼区間の計算には、適合値の標準誤差が使用されます。標準誤差は常に正数です。この解析では、 統計 メニューのモデルと 予測分析モジュールの 線形回帰 モデルと 2値ロジスティック回帰 モデルの標準誤差が計算されます。
解釈
適合値の標準誤差は、平均応答の推定値の精度を測定するために使用します。標準誤差が小さいほど、予測される平均応答の精度は高くなります。たとえば、分析者が配達時間を予測するモデルを開発するとします。変数設定のひとつのセットに、モデルは3.80日の平均配達時間を予測します。これらの設定の適合値の標準誤差は0.08日です。変数設定の2つめのセットに、モデルは適合値の標準誤差の0.02日で同じ平均配達時間を生成します。分析者は、変数設定の2つめのセットの平均配達時間が3.80日近くであるということに、より自信を持つことができます。
あてはめ値を使用すると、近似の標準誤差を使用して、平均応答の信頼区間を作成できます。たとえば、自由度の数に応じて、95% 信頼区間は、予測平均の上下に約 2 つの標準誤差を拡張します。配達時間の場合、標準誤差が 0.08 の場合の予測平均 3.80 日の 95% 信頼区間は (3.64, 3.96) 日です。これは、95%の信頼度で、母集団の平均がこの範囲に含まれることを意味します。標準誤差が 0.02 の場合、95% 信頼区間は (3.76, 3.84) 日です。変数設定の 2 番目のセットの信頼区間は、標準誤差が小さいため、より狭くなります。
95%信頼区間
近似の信頼区間は、予測変数の指定された設定が与えられた場合の平均応答の可能値の範囲を提供します。この分析では、 統計 メニューのモデルと、 予測分析モジュールの 線形回帰 と 2値ロジスティック回帰 のモデルの信頼区間が計算されます。
解釈
信頼区間を使用して、変数の観測値の適合値の推定値を評価します。
たとえば、95% の信頼水準では、信頼区間にモデル内の変数の指定された値の母平均が含まれていると 95% の信頼度を持つことができます。信頼区間は、結果の実際的な重要性を評価するのに役立ちます。専門知識を活用して、信頼区間に状況にとって実際的に重要な値が含まれているかどうかを判断します。信頼区間が広いということは、将来の値の平均について信頼が低くなる可能性があることを示します。信頼区間が広すぎて役に立たない場合、サンプルサイズを増加させることを検討します。
95%予測区間
予測区間は、選択した変数設定の組み合わせに対する単一の将来の応答を含む可能性が高い範囲です。この分析では、 統計 メニューのモデルと 予測分析モジュールの 線形回帰 モデルの予測区間が計算されます。
解釈
予測間隔 (PI) を使用して、予測の精度を評価します。予測区間から、結果の実質的な有意性を評価できます。 予測間隔が許容範囲外に広がると、予測が要件に対して十分に正確ではない可能性があります。
95% の PI では、指定した予測変数の設定が与えられた場合、1 つの応答が区間に含まれると 95% の確信を得ることができます。予測区間は、単一の応答と平均応答の予測に伴う不確実性が加わるため、常に信頼区間よりも広くなります。
たとえば、家具メーカーの材料エンジニアが、基板の密度からパーティクルボードの剛性を予測する単純な回帰モデルを開発します。エンジニアは、モデルが分析の仮定を満たすかどうかを検証します。次に、アナリストはモデルを使用して剛性を予測します。
たとえば、回帰式は、新しい観測値に対して予測される剛性が、密度が25のとき-21.53 + 3.541*25、つまり66.995であることを予測します。このような観測値の剛性が正確に 66.995 になる可能性は低いですが、予測区間は、エンジニアが実際の値が約 48 から 86 の間になると 95% 確信できることを示しています。
複合的な望ましさ
複合望ましさ (D) を使用して、設定が一連の応答を全体的にどの程度最適化するかを評価します。望特性の値の範囲は0~1です。1は理想的なケースを表し、0は、1つ以上の応答が許容限界の外にあることを表します。
多くの場合、応答が複数あると、すべての応答の望特性を同時に最大化する因子設定はありません。こうした理由から、Minitabは複合的な望ましさを最大化します。複合的な望ましさは、すべての応答変数に対する個別望特性を単一の測度にまとめたものです。その際、重要度の高い応答変数はより強調します。
詳細については、 個別の望ましさと複合的な望ましさとはを参照してください。
解釈
複合望ましさの値が 1 に近い場合は、設定がすべての応答に対して良好な結果を達成していることを示します。
平均的重要性
を使用すると、モデル図の結果と最適化の結果に平均重要度が含まれます。平均重要度を用いて、最適化分析においてすべてのモデルで最も重要な予測因子を評価します。平均重要度は相対的重要性の平均であり、値は0%から100%の間です。平均重要度が100%の変数は、分析のすべてのモデルで最も重要な変数です。
解釈
平均重要度が高いことは、分析対象のほとんどのモデルで変数が重要であることを示します。低い平均重要度には異なる意味があります。例えば、ある変数が多くのモデルのうちの一つで重要だったり、分析対象となるすべてのモデルで比較的重要度が低い変数があったりします。最適化プロットと相互作用する際の平均重要度を考慮してください。
性能
- R二乗: 連続応答
- R二乗はモデルが説明する応答の変動の割合です。値は1から残差平方和(モデルによって説明されない変動)の比を引いて全体平方和(モデルの変動の合計)まで計算されます。R二乗値が高いほど、モデルはあなたのデータに適合しやすいです。
- ROC曲線下の面積: 2値応答
- ROC曲線は、検出力とも呼ばれる真陽性率 (TPR) をy軸にプロットします。ROC曲線は、第1種の過誤とも呼ばれる偽陽性率 (FPR) をx軸にプロットします。ROC曲線下の面積は、分類木が適切な分類器であるかどうかを示します。
- 誤分類率: 多項応答
- 誤分類率は、モデルがイベントと非イベントを正確に分類する頻度を示します。値が小さいほど、パフォーマンスが高いことを示します。
ID
を使うと、モデル図の結果にはIDが含まれます。IDは Minitab統計ソフトウェアが社内の組織化に使用する番号です。Minitabの統計ソフトウェアのマクロでIDを使いましょう。