このトピックの内容
長さ
時系列に含まれる観測値の数。
欠損値の数
時系列内の欠損値の数。
適合されたトレンド式
| モデルのタイプ | 式 |
|---|---|
| 線形 | Yt = b0 + (b1 * t) |
| 2次 | Yt = b0+ b1 * t + (b2* t2) |
| 指数的成長 | Yt = b0 + (b1t) |
| S曲線(Pearl-Reedロジスティック) | Yt = (10a) / (b0 + b1 * b2t)。 |
- ytは変数です
- b0は定数です
- b1とb2は係数です
- tは時間単位の値です
MAPE
平均絶対パーセント誤差(MAPE)では、精度を誤差のパーセント値として表します。MAPEはパーセント値であるため、他の測度統計量よりも容易に理解できます。たとえば、MAPEが5の場合、予測値は平均で5%外れます。
ただし、データに対するモデルの適合度が高いように見える場合でも、MAPEの値が非常に大きくなることがあります。プロットを調べ、いずれかのデータ値が0に近いかどうか確認します。MAPEでは絶対誤差を実際のデータで除算するため、値が0に近いとMAPEの値が非常に大きくなります。
解釈
異なる時系列モデルの適合度を比較するために使用します。値が小さいほど適合性が高いことを示します。単一のモデルに、3つすべての精度の測度の最低値が含まれていない場合、通常はMAPEが優先される測定方法となります。
精度の測度は、1期間先の残差に基づいています。各時点でこのモデルを使用して、時系列における次の期間のY値を予測します。予測値(適合度)と実際のY値の差は、1期間先の残差です。このため、この精度の測度は、データの終わりから始まる1期間を予測する場合に期待される精度を示します。したがって、1期間より先の予測の精度を示すものではありません。予測でモデルを使用する場合は、精度の測度のみに基づいて決定しないでください。モデルの適合度も調べて、特に系列の終わりにおいてその予測とモデルがデータに密接に従うことを確認する必要があります。
MAD
平均絶対偏差(MAD)により、データと同じ単位で精度を表現し、誤差の量を概念化することができます。外れ値の影響は、MSDの場合よりMADの場合のほうが小さくなります。
解釈
異なる時系列モデルの適合度を比較する目的で使用します。値が小さいほど適合性が高いことを示します。
精度の測度は、1期間先の残差に基づいています。このモデルは、各時点において、時系列の次の期間におけるY値を予測する目的で使用します。予測値(適合度)と実際のY値の差は、1期間先の残差です。このため、この精度の測度は、データの終わりから始まる1期間について予測する場合に期待される精度を示します。したがって、1期間より先の予測の精度を示すものではありません。予測でモデルを使用する場合は、精度の測度のみに基づいて決定しないでください。モデルの適合度も調べ、特に系列の終わりに、その予測値とモデルがデータに密接に従うことを確認する必要があります。
MSD
平均平方偏差(MSD)により、当てはめられた時系列の値の精度を測定します。外れ値の影響は、MADの場合よりMSDの場合のほうが大きくなります。
解釈
異なる時系列モデルの適合度を比較する目的で使用します。値が小さいほど適合性が高いことを示します。
精度の測度は、1期間先の残差に基づいています。このモデルは、各時点において、時系列の次の期間におけるY値を予測する目的で使用します。予測値(適合度)と実際のY値の差は、1期間先の残差です。このため、この精度の測度は、データの終わりからの1期間を予測する場合に期待される精度を示します。したがって、1期間より先の予測の精度を示すものではありません。予測でモデルを使用する場合は、精度の測度のみに基づいて決定しないでください。モデルの適合度も調べて、特に系列の終わりにその予測とモデルがデータに密接に従うことを確認する必要があります。
トレンド
トレンド値は適合値とも呼ばれます。トレンド値は、時間(t)における変数の点推定です。
解釈
トレンド値は、データセットに含まれる観測値ごとの特定の時間値を時系列モデルに入力することによって計算されます。
たとえば、モデル方程式がy = 5 + 10xの場合、時間2におけるトレンド値は25(25 = 5 + 10(2))となります。
観測された値と非常に異なるトレンド値を含む観測値は、異常な観測値か、または影響力のある観測値である可能性があります。外れ値がある場合は、その原因を特定してください。データ入力や測定の誤差はすべて修正します。異常な1回だけの事象(特殊原因)に関連付けられたデータ値を除外することを検討してください。それから、分析を繰り返します。
トレンド除去
トレンド除去値は残差とも呼ばれます。トレンド除去値は、観測値とトレンド値の差です。
解釈
トレンド除去値をプロットして、モデルが適合するかどうか判断します。値を調べることにより、データに対するモデルの適合度に関して有用な情報を得ることができます。一般に、トレンド除去値は0付近にランダムに分布し、明確なパターンや異常値を示しません。
期間
Minitabには、予測を行う期間が表示されます。期間は、予測の時間単位です。予測は、デフォルトでデータの終わりに開始されます。
予測
予測値は、時系列モデルから得られる適合値です。Minitabには、指定する予測の数が表示されます。予測は、データの終わりか、指定する原点で開始されます。Minitabでは、原点の前のデータを使用して、適合トレンド方程式の係数を計算します。原点を指定すると、Minitabでは、予測のためにその行番号までのデータのみを使用します。
解釈
予測を使用して、指定した期間における変動を予測します。たとえば倉庫管理者は、過去60か月間の注文状況に基づいて、向こう3か月間の製品の発注量をモデル化することができます。
トレンド分析プロットの終わり、および予測を調べて、予測値の正確さを判断します。適合値は、特に系列の終わりにはデータに密接に従います。系列の終わりに適合値がデータからずれ始めた場合は、基本のトレンドが変化している可能性があります。トレンドが変化している場合は、そのモデルで正確な予測を行うことはできません。その場合は、データをさらに収集して、長期間におけるトレンドでは一貫性が低下するかどうか判断してください。
予測が正確なものに見える場合でも、3期間より先の予測は慎重に行ってください。短いスパンのデータで観測されるトレンドは、より大きなサイクルの一部になっていて長くは持続しない可能性があります。トレンドは急変する可能性があるため、通常は2~3期間先の範囲についてのみ予測してください。
トレンド分析プロット
トレンド分析プロットには、観測値と時間の関係が表示されます。このプロットには、適合されたトレンド式から計算される適合値、予測値、および精度の測度が含まれます。
解釈
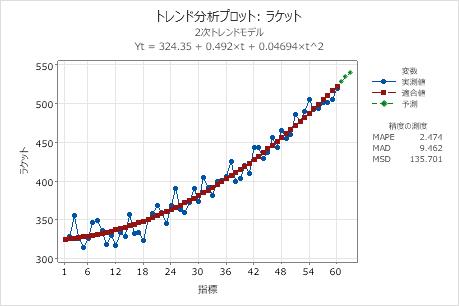
このトレンド分析プロットでは適合値がデータに密接に従っており、これは、そのモデルがデータに適合することを示しています。
曲線パラメータ
- 切片
- 時間 = 0でのモデルの値。切片は、10a / (β0 + β1) と等しくなります。
- 漸近線
- 時間が無限に増分するのに伴ってモデルが近付く値。漸近線は、10a / β0と等しくなります。
- 漸近率
- モデルが漸近線に近付く率。この値が小さいモデルは、漸近線に急速に接近します。漸近率は、β2と等しくなります。
残差のヒストグラム
残差のヒストグラムには、すべての観測値の残差の分布が表示されます。モデルがデータによく適合する場合は、平均が0のランダム分布になります。したがって、ヒストグラムは、0を中心とするほぼ対称な形になります。
残差の正規確率プロット
残差の正規プロットには、分布が正規分布する場合の残差と期待値の関係が表示されます。
解釈
残差の正規プロットを使用して、残差が正規分布かどうかを判断します。ただし、この分析には、正規分布した残差は不要です。
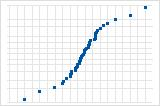
S曲線は、長い裾を持つ分布を示唆しています。
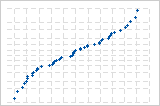
逆S曲線は、短い裾を持つ分布を示唆しています。
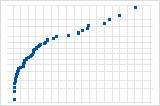
下向きの曲線は、右方向の歪みを示唆しています。
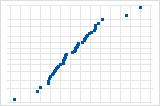
少数の点が直線から離れている場合は、外れ値のある分布を示唆しています。
残差対適合値
残差対適合値プロットでは、y軸に残差が、x軸に適合値が表示されます。
解釈
残差対適合値プロットを使用して、残差に偏りがなく、均一分散かどうかを判断します。理想的なのは、各点が0の両側にランダムにプロットされ、認識可能なパターンが存在しない状態です。
| パターン | パターンが示す意味 |
|---|---|
| 残差が適合値周辺に扇状または不均等に分散している | 不均一分散 |
| 曲線 | 高次の項の欠損 |
| ゼロから遠い点 | 外れ値 |
残差に不均一分散またはパターンがある場合、予測は正確ではない可能性があります。
残差対データ順序
残差対データ順序プロットには、データの収集順に残差が表示されます。
解釈
残差対データ順序プロットを使用して、観測期間に観測された値と比較した適合値の正確さを確認します。各点におけるパターンは、モデルがデータに適合しないことを示す可能性があります。理想的には、プロットの残差が中心線の周囲にランダムにプロットされます。
| パターン | パターンが示す意味 |
|---|---|
| 一貫した長期トレンド | モデルはデータに適合しない |
| 短期トレンド | パターンにおけるシフトまたは変化 |
| その他の点から遠い点 | 外れ値 |
| 点での突然のシフト | データの基本的なパターンが変更された |
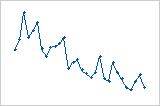
残差は、観測値の順序が左から右に向かって増加するにつれて体系的に減少します。
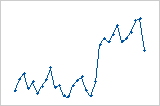
残差の値が低(左)から高(右)に急激に変化しています。
残差対変数
残差対変数プロットには、別の変数に対する残差の値が表示されます。
解釈
このプロットを使用して、変数が系統的に応答に影響するかどうかを判断します。残差にパターンがある場合、その他の変数が応答に関連付けられます。この情報は、追加調査の基本として参考にすることができます。
トレンド線間の比較
注
Minitabでは、新しい線を使用して予測値を計算します。