相対リスクの増分
一部の予測変数では、予測変数の 1 単位の変更に対する既定の相対リスクは役に立ちません。たとえば、1 日の変更に対する相対的なリスクが小さすぎる場合は、365 と入力して、1 年の変更に対する相対的なリスクを確認します。
- 連続予測変数
- モデル内の連続予測変数の名前をすべて表示します。この列に対して入力を行うことはできません。
- 増分
- Minitabがオッズ比を計算するために使用する連続予測変数の変化量を入力します。
カテゴリ変数のコード化
- カテゴリ予測変数のコード化
- 分析を実行する場合は、2つの方法のうち1つを使用して、カテゴリ予測変数を再コード化する必要があります。予測変数の水準を基線または参照水準と比較したいかどうかによって、方法の変更を検討します。コード体系によって、予測変数の全体的な影響の検定が変更されることはありません。詳細については、カテゴリ予測変数のコード化方式 を参照してください。
- (-1、0、+1): 1 つのグループ レベルの個人がベースライン レベルの個人に対して相対的にイベントを発生するリスクを比較する場合に選択します。
- (1、0): 1 つのグループレベルの個人が、参照グループレベルの個人に対して相対的にイベントを発生するリスクを比較する場合に選択します。(0, 1)のコード化スキームを選択した場合、ダイアログボックスの参照水準表がアクティブになります。
- 参照水準表
-
- カテゴリ予測変数
- 表のこの列は、モデル内のすべてのカテゴリ予測変数名を示します。この列に対して入力を行うことはできません。
- 参照水準
-
非参照水準が参照水準と比較されます。参照水準を変更しても全体の有意性には影響しませんが、係数はより解釈する意義のある値となる可能性があります。
たとえば、患者の血小板数が正常であるかどうかに関するカテゴリ予測変数には、レベル "はい" と "いいえ" があります。応答イベントは、患者が死亡することです。
参照事象はオッズ比の分母です。参照水準を変更するときにオッズ比は逆数になります。参照水準が「いいえ」のとき、オッズ比は次のようになります。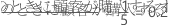 参照水準が「はい」のとき、オッズ比は次のようになります。
参照水準が「はい」のとき、オッズ比は次のようになります。
参照水準を変更するときに係数の符号は変わります。参照水準が「はい」のとき、係数は-1.6です。係数が負の場合、因子の参照水準ではシリアルを購入する可能性が高くなることを示しています。参照水準が「いいえ」のとき、係数の符号は変わり、1.6になります。係数が正の場合、因子の参照水準ではシリアルを購入する可能性が低くなることを示しています。
連続予測変数の標準化
モデル内にある連続予測変数を標準化するために選択できます。標準化予測変数は、モデルを適合させるためのみに使用するので、このワークシートには保存されません。
連続予測変数を標準化すると、モデルの解釈を指定条件に合わせて改善できます。
- 平均値を差し引くことにより、連続予測変数を中央に寄せます。この方法は、多重共線性を低下させるのに役立ち、係数推定値の精度を向上させます。このモデルは、モデルに相関の高い予測変数、高次項、交互作用項が含まれているときにも役立ちます。各係数は、元の測定スケールを使用して、予測変数の単位当たり変化に相当する、応答の期待変化を表します。
- 標準偏差で除算することにより、連続予測変数のスケールを標準化します。この方法により、予測変数の範囲はより均一になり、係数の大きさを比較できるようになります。この手法は、スケールの差を抑えながら、どの予測変数が大きな影響を与えているかを知りたいときに役立ちます。ただし、各係数は、予測変数の標準偏差の変化に相当する応答の期待変化を表します。
以下の方法の1つを使用して、連続予測変数を標準化できます。
- 標準化しない: 連続予測変数に元データを使用します。
- 最低水準と最高水準を指定して、-1および+1としてコード化: 予測変数を中央に寄せたり、予測変数を比較できるスケールにしたりするために使用します。この方法は実験計画法(DOE, Design of experiments)で使用します。指定した最小値と最大値の範囲内に分布するすべてのデータ値は、-1~+1の範囲内に分布されるように変換されます。表では、最小値と最大値を入力するか、サンプルに設定されているデフォルトの最大値と最小値を使用します。
- 連続予測変数
- 連続予測変数すべての名前が表示されます。この列に対して入力を行うことはできません。
- 下限側
- -1のコードとなる値入力します。サンプルの最小値がデフォルトです。
- 上限側
- +1のコードとなる値を入力します。サンプルの最大値がデフォルトです。
- 平均を引き、標準偏差で割る: 予測変数を中央に寄せたり、予測変数を比較できるスケールにしたりするために使用します。
- 平均を引く: 予測変数を中央に寄せるために使用します。
- 標準偏差で割る: 予測変数を比較できるスケールにするために使用します。
- 指定した値を引き、別の値で割る: サンプルの平均値や標準偏差推定値を使用する代わりに他の値を指定します。
- 連続予測変数
- 連続予測変数すべての名前が表示されます。この列に対して入力を行うことはできません。
- 引く
- 各連続予測変数から差し引く値を入力します。
- 次で割る
- 減算結果を除算するために使用される値を入力します。