適合度検定は帰無仮説を評価する 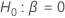 対立仮説 に対する
対立仮説 に対する
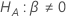 .テストの場合、
.テストの場合、
 は
p成分ベクトルです。
は
p成分ベクトルです。
クラスターのない分析では、Minitab統計ソフトウェアは、適合度検定を3つ提供します。
- グローバル・ウォルド・テスト
- 尤度比検定
- グローバルスコアテスト
クラスターを使用した解析では、クラスター内の観測値が独立していると仮定するため、グローバル尤度比検定は提供されません。
自由度
適合度検定の自由度は、モデル内の項の自由度の合計です。この合計は、モデル内のパラメータの数と等しくなります。
カイ二乗
F統計量の計算は、次のように、仮説検定によって変わります。応答変数に関連付けられた応答時間がない場合、スコアテストは既知のログランクテストと同じです。
帰無仮説では、検定の種類ごとに検定統計量は漸近カイ二乗分布を持ちます。漸近分布は、モデル内のパラメータの数と比較して、観測されたイベントの数が多い場合に有効です。カテゴリ予測変数の場合、各レベルのイベント数も十分に大きくなければなりません。
尤度比検定
尤度比検定での仮説は次のとおりです。 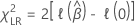
ここで、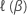 は、適切なモデルの部分対数尤度関数です。
は、適切なモデルの部分対数尤度関数です。
ワルド検定
Wald 検定の場合、検定統計量は次の形式になります。 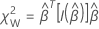
ここで、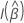 はフィッシャー情報行列です。
はフィッシャー情報行列です。


ここで、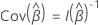 および
および  は、折りたたまれたスコア残差行列です。折りたたまれたスコア残差行列を取得するには、スコア残余行の各クラスターを残余行の合計で置き換えます。
は、折りたたまれたスコア残差行列です。折りたたまれたスコア残差行列を取得するには、スコア残余行の各クラスターを残余行の合計で置き換えます。
その後、Wald 検定統計量は次の形式になります。 
スコアテスト
スコアテストの場合、検定統計量は次の形式になります。 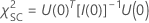
ここで、 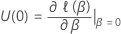
および 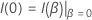
設計にクラスターがある場合、テスト統計には次の変更が加えられます。 
ここで、 は、折りたたまれたスコア残差行列です。
は、折りたたまれたスコア残差行列です。  .折りたたまれたスコア残差行列を取得するには、スコア残余行の各クラスターを残余行の合計で置き換えます。
.折りたたまれたスコア残差行列を取得するには、スコア残余行の各クラスターを残余行の合計で置き換えます。
p値
検定のp値 
ここで、 は、カイ二乗分布に続くランダム変数です。
は、カイ二乗分布に続くランダム変数です。  の自由度。
の自由度。
 は検定統計量です。
は検定統計量です。
1 Lin, D.Yからの堅牢な分散が使用されます。 &
Wei, L.J.(1989).The robust inference for the Cox proportional hazards
model.Journal of the American Statistical Association, 84(408),
1074-1078.
https://doi.org/10.1080/01621459.1989.10478874