X-スコア
X-スコアはモデル内の項の線形の組み合わせで、主要成分のスコアに似ています。X-スコアは、相関のない列のn × m行列を形成します。X-スコアは、PLS成分に対する観測値の射影です。PLS適合値は、最小二乗推定を使用して、データ内の元の項の代わりにX-スコアを適合させます。
計算式
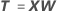
表記
| 用語 | 説明 |
|---|---|
| n | 観測値数 |
| m | 成分の数 |
| i | 1からnまでの観測値 |
| j | 1からpまでの項 |
| X | 計画行列 |
| W | X-重み行列 |
X-因子負荷量
X-因子負荷量は、項をX-スコアに関連付ける線形係数であり、主成分分析の固有ベクトルに似ています。X-因子負荷量は、m番目の成分に対応する応答の重要度を示します。X-因子負荷量はp × m行列を形成します。
計算式
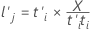
表記
| 用語 | 説明 |
|---|---|
| p | 項の数 |
| m | 成分数 |
| i | 1からnまでの観測値 |
| j | 1からpまでの項 |
| t | X-スコア |
| X | 予測変数 |
X-重み
X-重みは項と応答の間の共分散を説明します。アルゴリズムでは、この重みは、X-スコアが直交型であること、つまり互いに関係を持たないことを確実にするので、X-スコアを計算するために使用します。X-重みはp × m行列を形成します。
計算式
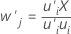
重みのベクトルは、ベクトルの長さが1になるようにスケールされます。
表記
| 用語 | 説明 |
|---|---|
| p | 項の数 |
| m | 成分の数 |
| i | 1からnまでの観測値 |
| j | 1からpまでの項 |
| X | X-残差行列 |
| u | Y-スコア |
X-残差
X-残差には、PLSモデルによって説明されない予測変数の分散が含まれます。比較的大きなX-残差を持つ観測値は、X-空間の外れ値であり、モデルによって良好に説明されないことを示します。
X-残差は、予測変数の実際の値とX-計算値との差であり、スケールは元の予測変数と同じです。X-残差行列は、元のX-行列と同様に、n × pの行列です。
X-残差行列は、標準化されたX-行列に初期化されます。m番目の成分を計算して、X-スコアのベクトルとX-因子負荷量のベクトルを取得した後、X-残差が計算されます。
計算式

その後、標準化X-残差に予測変数値の標準偏差を掛けることで、非標準化X-残差を計算します。
表記
| 用語 | 説明 |
|---|---|
| n | 観測値数 |
| p | 項の数 |
| i | 1からnまでの観測値 |
| j | 1からpまでの項 |
| t | X-スコア |
| l | X-因子負荷量 |
X-計算値
X-計算値はX-スコアの線形の組み合わせであり、PLSモデルによって説明される予測変数の分散が含まれます。比較的小さなX-計算値を持つ観測値は、X-空間の外れ値であり、モデルによって良好に説明されません。
X-計算行列は、元のX-行列と同様に、n × pの行列(nは観測値の数に等しく、pは予測変数の数に等しい)です。X-計算値のスケールは、予測変数と同じです。
X-計算行列は、ゼロ行列に初期化されます。m番目の成分を計算して、X-スコアのベクトルとX-因子負荷量のベクトルを取得した後、X-計算値が計算されます。成分の数が予測変数の数と同じ場合、X-計算値は元のX-値と等しくなります。
計算式
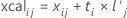
その後、標準化X-計算値に予測変数値の標準偏差を掛けて、平均を足すことで、非標準化X-残差を計算します。
表記
| 用語 | 説明 |
|---|---|
| n | 観測値数 |
| p | 予測変数の数 |
| i | 1からnまでの観測値数 |
| j | 1からpまでの予測変数の数 |
| t | X-スコア |
| l | X-因子負荷量 |
Y-スコア
Y-スコアは応答変数の線形の組み合わせです。Y-スコアはn × m行列を形成します。Y-スコアは、PLS成分に対する観測値の射影です。
計算式
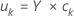
表記
| 用語 | 説明 |
|---|---|
| n | 観測値数 |
| m | 成分の数 |
| k | 1からpまでの応答数 |
| Y | Y-行列 |
| c | Y-因子負荷量 |
Y-因子負荷量
Y-因子負荷量は、応答をY-スコアに関連付ける線形係数です。この因子負荷量は、m番目の成分に対応する応答の重要度を示します。Y-因子負荷量はp × m行列を形成します。
計算式

表記
| 用語 | 説明 |
|---|---|
| r | 応答数 |
| m | 成分数 |
| i | 1からnまでの観測値 |
| k | 1からrまでの応答 |
| Y | 応答 |
| t | X-スコア |
Y-残差
Y-残差には、PLSモデルによって説明されない、応答の残りの分散が含まれます。比較的大きなY-残差を持つ観測値は、Y-空間の外れ値であり、モデルによって良好に説明されないことを示します。
Y-残差は、実際の応答値とY-計算値との差であり、スケールは元の応答と同じです。Y-残差行列は、元のY-行列と同様に、n × pの行列です。
Y-残差行列は、標準化されたY-行列に初期化されます。m番目の成分を計算して、X-スコアとY-因子負荷量のベクトルを取得した後、標準化Y-残差が決定されます。
計算式

その後、標準化Y-残差に、対応する応答値の標準偏差を掛けることで、非標準化Y-残差を計算します。
表記
| 用語 | 説明 |
|---|---|
| n | 観測値数 |
| r | 応答数 |
| i | 1からnまでの観測値 |
| k | 1からrまでの応答 |
| t | X-スコア |
| c | Y-因子負荷量 |
Y-計算値
Y-計算値はX-スコアの線形の組み合わせであり、PLSモデルによって説明される応答の分散が含まれます。比較的小さなY-計算値を持つ観測値は、Y-空間の外れ値であり、モデルによって良好に説明されません。
Y-計算行列は、元のY-行列と同様に、n × pの行列です。Y-計算行列は、ゼロ行列に初期化されます。m番目の成分を計算して、X-スコアとY-因子負荷量のベクトルを取得した後、標準化Y-計算値が決定されます。
計算式
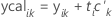
その後、標準化Y-計算値に、対応する応答の標準偏差を掛けて、平均を足すことで、非標準化Y-計算値を計算します。
表記
| 用語 | 説明 |
|---|---|
| n | 観測値数 |
| r | 応答数 |
| i | 1からnまでの観測値 |
| k | 1からrまでの応答 |
| t | X-スコア |
| c | Y-因子負荷量 |