あるワインの生産者が、ワインに含まれる化学成分と感覚に与える影響の関係を調査したいと考えています。37種類のピノ・ノワール種ワインのサンプルについて、それぞれのワインに含まれる17種類の元素(カドミニウム(Cd)、モリブデン(Mo)、マンガン(Mn)、ニッケル(Ni)、銅(Cu)、アルミニウム(Al)、バリウム(Ba)、クロム(Cr)、ストロンチウム(Sr)、鉛(Pb)、ホウ素(B)、マグネシウム(Mg)、ケイ素(Si)、ナトリウム(Na)、カルシウム(Ca)、リン(P)、カリウム(K))の濃度と審査員団によるワインの芳香の得点が記録されています。ワインの生産者は17元素から芳香の得点を予測したいと考えています。データ元は次の通りです。I.E. Frank、B.R. Kowalski (1984). "Prediction of Wine Quality and Geographic Origin from Chemical Measurements by Partial Least-Squares Regression Modeling," Analytica Chimica Acta, 162, 241 − 251.
ワイン生産者は、すべての濃度と、カドミニウム(Cd)が含まれる二元交互作用のすべてをモデル内に含めたいと考えています。サンプルと予測変数の比率が低いので、生産者は偏最小二乗回帰を使用することを決めます。
- サンプルデータを開く ワイン芳香.MWX.
- を選択します。
- 応答に芳香を入力します。
- モデルに、Cd-KCd*MoCd*MnCd*NiCd*CuCd*AlCd*BaCd*CrCd*SrCd*PbCd*BCd*MgCd*SiCd*NaCd*CaCd*PCd*Kを入力します。
- オプションをクリックします。
- 交差検証で、観測値を1つずつ省略を選択します。OKをクリックします。
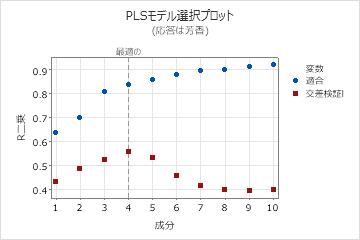
- グラフをクリックします。モデル選択プロットを選択します。応答プロットおよび係数プロットを選択解除します。
- 各ダイアログボックスでOKをクリックします。
結果を解釈する
モデル選択プロットでは、4つの成分を持つモデルが予測R2の値が最も大きいため、このモデルを最適モデルとみなします。プロット上の予測R2の値は交差検証を使用して計算されます。モデル選択および検証表により、最適モデルの予測R2の値はおよそ0.56であることがわかります。Minitabでは、分散分析計算の最適モデルを使用します。p値はほぼ0.000であるので、0.05の有意水準にある最適モデルは統計的に有意です。
方法
| 交差検証 | 観測値を1つずつ省略 |
|---|---|
| 評価する成分 | 設定 |
| 評価された成分数 | 10 |
| 選択された成分数 | 4 |
芳香の分散分析
| 要因 | 自由度 | 平方和 | 平均平方 | F値 | p値 |
|---|---|---|---|---|---|
| 回帰 | 4 | 34.5514 | 8.63784 | 41.55 | 0.000 |
| 残差誤差 | 32 | 6.6519 | 0.20787 | ||
| 合計 | 36 | 41.2032 |
芳香に対するモデル選択および検証
| 成分 | X分散 | 誤差 | R二乗 | 予測残差平方和 (PRESS) | R二乗 (予測) |
|---|---|---|---|---|---|
| 1 | 0.158849 | 14.9389 | 0.637435 | 23.3439 | 0.433444 |
| 2 | 0.442267 | 12.2966 | 0.701564 | 21.0936 | 0.488060 |
| 3 | 0.522977 | 7.9761 | 0.806420 | 19.6136 | 0.523978 |
| 4 | 0.594546 | 6.6519 | 0.838559 | 18.1683 | 0.559056 |
| 5 | 5.8530 | 0.857948 | 19.2675 | 0.532379 | |
| 6 | 5.0123 | 0.878352 | 22.3739 | 0.456988 | |
| 7 | 4.3109 | 0.895374 | 24.0041 | 0.417421 | |
| 8 | 4.0866 | 0.900818 | 24.7736 | 0.398747 | |
| 9 | 3.5886 | 0.912904 | 24.9090 | 0.395460 | |
| 10 | 3.2750 | 0.920516 | 24.8293 | 0.397395 |