適合値
適合値はfitsまたはとも呼ばれます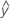 。適合値は、予測変数の値の平均応答の点推定です。予測変数の値はx値とも呼ばれます。
。適合値は、予測変数の値の平均応答の点推定です。予測変数の値はx値とも呼ばれます。
解釈
適合値は、データセットに含まれる観測値ごとの特定のx値をモデル式に入力することによって計算されます。
たとえば、式がy = 5 + 10xの場合に、x値が2ならば、適合値は25 (25 = 5 + 10(2))となります。
観測された値と非常に異なる適合値を含む観測値は、異常な観測値である可能性があります。異常な予測値を持つ観測値は、影響力がある可能性があります。Minitabが、データに異常または影響力がある値が含まれていると判断した場合は、これらの観測値が特定された、異常な観測値の適合値と診断の表が出力されます。ラベルが付けられた異常な観測値は、提示された回帰式にしっかりと従っていません。ただし、いくつかの異常な観測値があることは予測されています。たとえば、大きな標準化残差の基準に基づくと、観測値の約5%は大きな標準化残差を持つとしてフラグがつけられることが予測されます。異常な値に関する詳細は、異常な観測値を参照してください。
適合値の標準誤差(SE Fit)
適合値の標準誤差(SE Fit)は、特定の変数設定について推定される平均応答の変動を推定します。平均応答の信頼区間の計算には、適合値の標準誤差が使用されます。標準誤差は常に正数です。この解析では、 統計 メニューのモデルと 予測分析モジュールの 線形回帰 モデルと 2値ロジスティック回帰 モデルの標準誤差が計算されます。
解釈
適合値の標準誤差は、平均応答の推定値の精度を測定するために使用します。標準誤差が小さいほど、予測される平均応答の精度は高くなります。たとえば、分析者が配達時間を予測するモデルを開発するとします。変数設定のひとつのセットに、モデルは3.80日の平均配達時間を予測します。これらの設定の適合値の標準誤差は0.08日です。変数設定の2つめのセットに、モデルは適合値の標準誤差の0.02日で同じ平均配達時間を生成します。分析者は、変数設定の2つめのセットの平均配達時間が3.80日近くであるということに、より自信を持つことができます。
あてはめ値を使用すると、近似の標準誤差を使用して、平均応答の信頼区間を作成できます。たとえば、自由度の数に応じて、95% 信頼区間は、予測平均の上下に約 2 つの標準誤差を拡張します。配達時間の場合、標準誤差が 0.08 の場合の予測平均 3.80 日の 95% 信頼区間は (3.64, 3.96) 日です。これは、95%の信頼度で、母集団の平均がこの範囲に含まれることを意味します。標準誤差が 0.02 の場合、95% 信頼区間は (3.76, 3.84) 日です。変数設定の 2 番目のセットの信頼区間は、標準誤差が小さいため、より狭くなります。
95%信頼区間(CI)
適合値の信頼区間は、指定された予測を条件として、応答平均値になる可能性のある値の範囲を表します。
解釈
信頼区間を使用して、変数の観測値に関する適合値の推定値を評価します。
たとえば、信頼水準が95%の場合は、モデル内の指定された値の変数を持つ母集団が含まれる信頼区間を95%信頼できます。信頼区間は、結果の実質的な有意性を評価するのに役立ちます。専門知識を使って、信頼区間に実質的に有意な値が含まれているかどうかを状況に応じて判断します。信頼区間が広い場合、将来価値の平均値に対する信頼性が低くなります。信頼区間が広すぎて役に立たない場合、サンプルのサイズを大きくすることを検討します。
95% 予測区間(PI)
予測区間は、予測変数の設定が指定されたものとして、予測変数の値に関する将来の応答が1つ含まれる可能性のある範囲です。
解釈
たとえば、家具メーカーの材料技師は単回帰モデルを開発して、パーティクルボードの密度からそのボードの剛性を予測します。技師は、モデルが分析の仮定を満たすかどうかを検証します。その後、モデルを使用して、剛性を予測します。
回帰式は、新しい観測値の剛性が66.995になることを予測し、予測区間は[50, 85]になります。観測値の剛性値が厳密に66.995になる可能性は低いと考えられますが、予測区間は実際の値が95%の信頼度でおよそ50~85になるであろうことを示します。
単一の応答の予測は、複数の応答平均の予測よりも不確実であるため、予測区間は常に対応する信頼区間よりも広くなります。