ステップワイズ手順として検証のある前方選択 を使用すると、モデル選択手順の各ステップについて、トレーニングデータセットのR2統計量と、テストのR2統計量またはK分割ステップワイズのR2統計量のプロットが提供されます。テストのR2統計量またはK分割ステップワイズのR2統計量の表示は、テストデータセットを使用するか、K分割公差検証を使用するかによって異なります。
解釈
プロットを使用して、各ステップで異なるR2統計量の値を比較します。通常、R2統計量が両方とも大きい場合、モデルは良好に動作します。Minitabでは、テストのR2統計量またはK分割ステップワイズのR2統計量のいずれかを最大化するステップからのモデルの回帰統計量が表示されます。このプロットは、より単純なモデルが、適切な候補になれるほど良好に適合するかどうかを示します。
モデルが過剰適合している場合、項がモデルに入るにつれて、テストの R2統計量またはk分割ステップワイズのR2統計量が減少し始めます。この減少は、対応するトレーニングのR2統計量またはすべてのデータの R2統計量が増加し続けている間に発生します。過剰適合モデルは、母集団において重要でない効果に関する項を追加するときに発生します。過剰適合モデルは、母集団に関する予測を行う場合に役に立たない場合があります。モデルが過剰適合している場合、それ以前のステップのモデルを検討することができます。
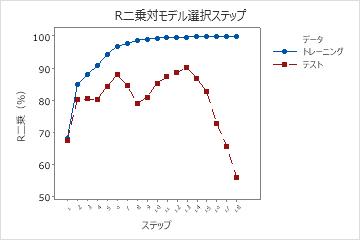
次のプロットは、例として、テストのR2を示しています。最初は、R2統計量はどちらも70%に近いです。最初のいくつかのステップでは、項がモデルに入るにつれて、R2統計量の両方が増加する傾向があります。ステップ6では、テストのR2統計量は約88%です。テストのR2統計量の最大値はステップ14のもので、値は90%に近い値です。適合度の改善が、モデルに項を追加する際の複雑さが増すことを正当化するかどうかを検討できます。
ステップ14の後、R2が増加し続ける間、テストのR2は増加しません。ステップ14後のテストのR2の減少は、このモデルが過剰適合していることを示します。