指数族とリンク関数
古典的線形モデルの一般化線形モデルへの拡張には2つのパートがあります。指数族の分布とリンク関数です。
指数族
1つ目のパートは、線型モデルを「指数族」と呼ばれる大きな分布族の一部である応答変数に拡張することです。指数分布族の一部には、以下のような一般形で観測された応答の確率分布関数があります。
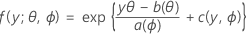
上記の式では、a(∙)、b(∙)、c(∙)は応答変数の分布によって変化します。パラメータθは、しばしば「正準パラメータ」と呼ばれる位置母数パラメータのことを指し、ϕは分散パラメータと呼ばれます。通常、関数a(ϕ)はa(ϕ)= ϕ/ ωという式が成立します。ωは既知の定数または重みであり、観測値によって変化します。(Minitabでは、重みが設定されると、関数a(ϕ)が設定に合わせて調整されます)
指数族の一部は、離散分布または連続分布になることがあります。指数族の一部となる連続分布の例として、正規分布やガンマ分布があります。指数族の一部となる離散分布の例には、二項分布とポアソン分布があります。以下の表には、このうち幾つかの分布の特徴を記載しています。
| 分布 | ϕ | b(θ) | a(φ) | c(y, ϕ) |
| 正規 | σ2 | θ2/2 | φω |  |
| 二項 | 1 | 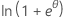 |
φ/ω | -ln(y!) |
| ポアソン | 1 | exp(θ) | φ/ω |  |
リンク関数
2つ目のパートはリンク関数です。リンク関数は、i番目の観測値の平均応答を以下の線形予測変数の式に関連付けます。
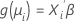
古典的線型モデルは、リンク関数が恒等関数になるような一般的な形式化の特殊ケースです。
2つ目のパートにおけるリンク関数の選択は、1つ目のパートの指数族の特定の分布によって変わります。特に、指数族の各分布には「正準リンク関数」と呼ばれる特殊なリンク関数があります。このリンク関数はg (μi) = Xi'β= θという方程式を満たし、θが正準パラメータにあたります。正準リンク関数により、このモデルの望ましい統計的性質が得られます。異なるリンク関数の適合度を比較するには、適合度の統計量を使うことができます。それまでの経緯や各分野での特殊な意味合いに応じ、使われるリンク関数は異なります。たとえば、logitリンク関数の利点の1つは、オッズ比の推定値が得られるという点です。別な例を挙げると、normitリンク関数は、2値カテゴリに分分類される正規分布に従った、基礎変数があると仮定します。
Minitabには、モデルの各クラスに対して、3つのリンク関数が用意されています。異なるリンク関数により、幅広く多様なデータに十分に適合するモデルを見つけることができます。
二項モデルの場合、リンク関数はlogit、normit(probitとも呼ばれる)、gompit(相補的log-logとも呼ばれる)です。これらは、標準累積ロジスティック分布関数の逆関数(logit)、標準累積正規分布関数の逆関数(normit)、およびゴンペルツ分布関数の逆関数(gompit)です。logitは二項モデルの正準リンク関数であるため、logitはデフォルトのリンク関数です。
ポアソンモデルの場合、リンク関数は自然対数、平方根、恒等関数です。自然対数はポアソンモデルの正準リンク関数であるため、自然対数はデフォルトのリンク関数です。
リンク関数は以下のようにまとめられます。
| モデル | 名前 | リンク関数、g(μi) |
| 二項 | logit | 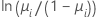 |
| 二項 | normit(probit) | 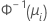 |
| 二項 | gompit(相補的log-log) |  |
| ポアソン | 自然対数 | 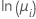 |
| ポアソン | 平方根 |  |
| ポアソン | 恒等 | 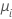 |
表記
| 用語 | 説明 |
|---|---|
| μi | i行目の平均応答 |
| g(μi) | リンク関数 |
| X | 予測変数のベクトル |
| β | 予測変数に関連する係数のベクトル |
 | 正規分布の逆累積分布関数 |
因子/共変量パターン
データセット内の1組の因子/共変量の値を説明します。因子/共変量パターンごとに、事象確率、残差、およびその他の診断測定値が計算されます。
たとえば、データセットに性別や人種の因子、年代の共変量が含まれている場合、これらの予測変数の組み合わせには、統計対象と同じ数のさまざまな共変量パターンが含まれている可能性があります。データセットに人種や性別の因子のみが含まれ、それぞれ2つの水準でコード化されている場合は、4つの因子/共変量パターンしかありません。データを、頻度または成功、試行、もしくは失敗として入力する場合、各行には1つの因子/共変量パターンが含まれます。
の内部重み 2値ロジスティックモデルの当てはめ
計算式
- Logit
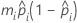
- Normit

- Gompit

表記
| 用語 | 説明 |
|---|---|
| mi | the number of trials for the i番目 row |
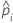 | the predicted probability for the design point in a binary logistic model |
| yi | the number of events for the i番目 row |
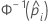 | the inverse cumulative distribution function of the standard normal distribution for the predicted probability in a binary logistic model |
2値ロジスティックモデルの当てはめで回帰式から高い相関を持つ予測変数を取り除く方法
rijが、XiとXjに関連付けられ、現在は取り除かれた行列の要素だとします。
変数は一度に一つずつ入力されるか、削除されます。Xkは、現時点ではrkk ≥ 1(デフォルトの公差は0.0001)を持つモデルにはない独立変数である場合は入力候補となり、現在モデルにあるXjの各変数の候補にもなります。

- Minitabでは、X1 … Xpをあたかもランダム変数であるかのように処理する相関行列Rに対して、SWEEP法を実行します。
- 連続予測変数の場合、rkk ≥ 公差(k = 1~p)として、要素rkkを公差と比較します。
- Xjの各変数がモデル内に現在ある場合は(rjj – rjk * (rkj / rkk)) * 公差 ≤ 1であるかどうかチェックされます。
注
ここでは、rkk、rjk、rjjは、kステップにおけるSWEEP操作の後に、XjとXkに対応する対角要素と非対角要素です。
- そうでない場合、予測値は検定に不合格となり、モデルから削除されます。
注
デフォルトの公差の値は8.8e–12です。
注
GZLMセッションコマンドでTOLERANCEサブコマンドを使用すると、別の予測変数と相関が高い予測変数をモデル内に保持するように強制できます。ただし、公差を下げると、数値結果が不正確となる可能性があるため危険です。