注
このコマンドは、予測分析モジュールで使用できます。モジュールをアクティブにする方法については、ここをクリックしてください。
TreeNet®モデルは、単一分類または回帰木よりもさらに正確でオーバーフィットに対する耐性を備えた分類と回帰の問題を解決するためのアプローチです。プロセスの広範な一般的な説明は、最初のモデルとして小さな回帰木から始めることです。その木から、次の回帰木の応答変数となるデータのすべての行の残差が表示されます。次に、最初の木の残差を予測し、結果として得られる残差を計算するために、別の小さな回帰木を構築します。検証法を使用して、最小予測誤差を持つ最適な木の数がで特定されるまでこのシーケンスを繰り返します。木の結果のシーケンスが、TreeNet®回帰モデルを作成します。
回帰の場合、分析の一般的な説明を追加できますが、一部の説明は以下のうちどれが損失関数であるかに応じて異なります。
| 統計量 | 値 |
|---|---|
初期適合、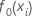
|
応答変数の平均 |
一般化残差、 予測応答値としての 行iの
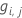
|

|
ノード更新内で、 
|

|
| 統計量 | 値 |
|---|---|
初期適合、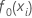
|
応答変数の中央値 |
一般化残差、行iの予測応答値としての 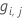
|
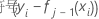
|
ノード更新内で、 
|
の中央値 
|
フーバー損失関数
フーバー損失関数の場合、統計値は次のとおりです。
初期適合、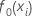 、すべての応答値の中央値と等しくなります。
、すべての応答値の中央値と等しくなります。
j番目の木を成が増加すると、 
次に i番目の行の一般化残差は次のようになります。
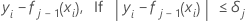

一般化残差は、j番目の木を拡大する応答値として使用されます。
j番目の木のm番目のターミナル ノードの行の更新値は次のとおりです。
を定義します。 j-1の木が成長した後の
i番目の行の通常残差。次のように定義します。
j-1の木が成長した後の
i番目の行の通常残差。次のように定義します。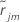 、の中央値
、の中央値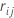 、
j番目の木のターミナルノードm
内の行の値。次に、j番目の木のm番目のターミナルノード内の各行の更新値は次のとおりです。
、
j番目の木のターミナルノードm
内の行の値。次に、j番目の木のm番目のターミナルノード内の各行の更新値は次のとおりです。 
j-1の木が成長した後の
i番目の行の通常残差。次のように定義します。、の中央値、
j番目の木のターミナルノードm
内の行の値。次に、j番目の木のm番目のターミナルノード内の各行の更新値は次のとおりです。 前の式の平均値は、j番目の木のターミナルノードm内のすべての行で計算されます。
損失関数の表記
前の詳細では、 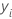 は、行iの応答変数の値であり、
は、行iの応答変数の値であり、 は、前の
j - 1 の木からの適合値であり、
は、前の
j - 1 の木からの適合値であり、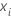 は、トレーニングデータ内の予測値の
i番目の行を表すベクトルです。
は、トレーニングデータ内の予測値の
i番目の行を表すベクトルです。
入力パラメータ
モデルの作成では、アナリストからの次の入力も使用されます:
| 入力 | 記号 |
|---|---|
| 学習率 |  |
| サンプル率 | 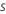 |
| ツリーあたりの終端ノードの最大数 | 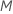 |
| 木の数 | 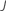 |
| 切り替え値 |  |
一般的なプロセス
このプロセスには、j番目の木を拡張するための一般的な手順が次に示されています(j = 1, ...,
J)。
- トレーニングデータから s * N のサイズのランダムサンプルを引き出します (N はトレーニングデータ内の行数)。
- 一般化残差を計算します、i:
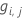 、
、 .
.
- 一般化残差に、最大M個のターミナルノードを持つ回帰木を適合します。木は、観測値を最大M個の相互に排他的なグループに分割します。
- 回帰木のm番目のノードについて、損失関数に依存する木へのノード内更新を計算します。
 .
.
- ノード内の更新を学習率で縮小し、その値を適用して更新された適合値を取得します
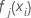 :
:
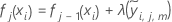
- 分析のJ個の木のそれぞれに対してステップ1から5を繰り返します。