注
このコマンドは、予測分析モジュールで使用できます。モジュールをアクティブにする方法については、ここをクリックしてください。
1つの予測変数の部分依存プロット
トレーニングデータセットにm個の予測変数があると仮定し、x1, x2, ..., xmで示されるとします。まず、トレーニングデータセット内のそれぞれの予測変数 x1 の値を昇順に並べ替えます。x11はx1の最初の個別値として示されます。次に、x11はプロットでx座標の左端の点となります。
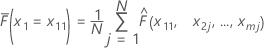
| 用語 | 説明 |
|---|---|
| N | トレーニングデータセットに含まれる行数 |
 | の観測値  トレーニングデータ
セット内の トレーニングデータ
セット内の |
| j | J 行の各行 |
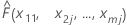 | x1 = x11, x2 = x2j,...., xm = xmjの場合のモデルからの適合値 |
x11 を x1の個別値で置き換えると、プロット上の残りの点のy座標が得られます。残りの予測変数の計算も同様に行われます。
xのすべての個別値に対するすべてのy座標を計算しようとすると、大きなデータセットでは時間を要します。TreeNet®では、計算を高速化する方法があります。Friedman, J. H. (2001)を参照。欲張り関数の近似: グラデーションブースティングマシン。 The Annals of Statistics, 29(5), page 1221.
多項応答の場合の計算も同様です。ここでは、適合値は個々のクラスのモデルから取得されます。
2つの予測変数の部分依存プロット
トレーニングデータセットにm個の予測変数があると仮定し、x1, x2, ..., xmで示されるとします。まず、トレーニングデータセット内の予測変数x1, x2の個別値を昇順に並べ替えます。x11, x21を個別のペアの1つとして示します。次に、各ペアは、曲面プロットの点に対しx座標とy座標を作成します。
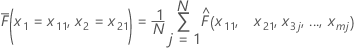
| 用語 | 説明 |
|---|---|
| N | トレーニングデータセットに含まれるすべての行数は、すべてx1 = x11、x2 = x21の共通性がある |
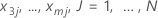 |  |
| j | J 行の各行 |
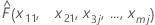 | x1 = x11, x2 = x21, x3 = x3j...., xm = xmjの場合の、モデルからの適合値 |
x1 と x2 のすべての個別値の組み合わせで計算が完了すると、等高線プロットまたは曲面プロットのすべてのz座標が生成されます。大きなデータセットの場合、xとyのすべての個別のペアを計算しようとすると時間がかかります。TreeNet®モデルでは、計算を高速化する方法があります。Friedman, J. H. (2001)を参照。欲張り関数の近似: グラデーションブースティングマシン。 The Annals of Statistics, 29(5), page 1221.