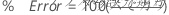注
このコマンドは、予測分析モジュールで使用できます。モジュールをアクティブにする方法については、ここをクリックしてください。
目的の方法また計算式を選択します。
誤分類テーブルには、モデルの分類精度に関する結果が含まれています。ほとんどの場合、レコードの分類は予測確率が最も高い応答レベルです。たとえば、2値応答では、予測される事象の確率が0.50を超える場合、行の分類は事象カテゴリになります。ただし、2値応答の場合は、0.50以外のしきい値を指定できます。
カウント数
重みがない場合、カウント数とサンプルサイズは同じです。
重み付きカウント
重み付きの場合、重み付きカウント数はあるカテゴリの重みの合計です。重みを使用して、パーセンテージとレートを計算します。次の単純な例を考えてみます。
| 応答レベル | 予測レベル | 体重 |
|---|---|---|
| はい | はい | 0.1 |
| はい | はい | 0.2 |
| はい | いいえ | 0.3 |
| はい | いいえ | 0.4 |
| いいえ | いいえ | 0.5 |
| いいえ | いいえ | 0.6 |
| いいえ | はい | 0.7 |
| いいえ | はい | 0.8 |
次の表に、次の統計情報を示します:
| 実際のクラス | 重み付きカウント | 誤分類 | 予測クラス = いいえ | 正解率 |
|---|---|---|---|---|
| はい | 0.1 + 0.2 + 0.3 + 0.4 = 1 | 0.1 + 0.2 = 0.3 ≈ 0 | 0.3 + 0.4 = 0.7 ≈ 1 | (0.3 / 1.0) ×100 = 30% |
| いいえ | 0.5 + 0.6 + 0.7 + 0.8 = 2.6 ≈ 3 | 0.7 + 0.8 = 1.5 ≈ 2 | 0.5 + 0.6 = 1.1 ≈ 1 | 1.1 / 2.6) × 100 = 42.31% |
| すべて | 1 + 2.6 = 3.6 ≈ 4 | 0.3 + 1.5 = 1.8 ≈ 2 | 0.7 + 1.1 = 1.8 ≈ 2 | (0.3 + 1.1) / 3.6 × 100 = 38.89% |
%不正解
重み付きの場合、カウント数の代わりに重み付きカウント数を使用します。